 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamCTC: Learning Speech Representations through Monotonic Temporal Alignment
Jun 01, 2026Self-supervised speech representation learning has made significant progress through Siamese networks, which leverage different views of the same input. However, existing methods often require frame-wise alignment between these views, overlooking the broader linguistic context invariance across different speaking styles. We introduce SiamCTC, a framework that integrates Siamese networks with Connectionist Temporal Classification (CTC) to learn speech representations without strict frame-level correspondence. By employing CTC loss to establish flexible, monotonic alignments between differing temporal realizations of the same content, SiamCTC accommodates speed perturbations and other temporal augmentations. This design relaxes frame-wise constraints while preserving temporal coherence and enhancing robustness to speaking-rate variations in downstream tasks. Our experiments demonstrate that SiamCTC leads to more adaptable speech representations, particularly at diverse speaking rates.
Decomposed On-Policy Distillation for Vision-Language Reasoning: Steering Gradients for Visual Grounding
May 30, 2026While on-policy distillation offers dense supervision for training small reasoning models, its optimization dynamics in the multimodal domain remain under-explored. In this work, we challenge the standard monolithic view of Vision-Language Model (VLM) distillation by mathematically decomposing the loss into two distinct components: the language prior and visual grounding. Our analysis uncovers that gradient vectors for these components are nearly orthogonal, indicating that the objective of aligning with the teacher's language distribution is geometrically independent from the objective of matching its visual perception. Consequently, standard optimization passively follows a suboptimal compromise trajectory that implicitly balances the two objectives. Hypothesizing that visual grounding constitutes the primary bottleneck for vision-language reasoning, we introduce Visual Gradient Steering (VGS), a method that dynamically reorients the update vector to prioritize the visual subspace. Experimental results on multiple distillation settings and complex multimodal benchmarks demonstrate that VGS significantly outperforms the standard monolithic formulation of on-policy distillation, achieving superior grounding with minimal training overhead.
PDCR: Perception-Decomposed Confidence Reward for Vision-Language Reasoning
May 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) traditionally relies on a sparse, outcome-based signal. Recent work shows that providing a fine-grained, model-intrinsic signal (rewarding the confidence growth in the ground-truth answer) effectively improves language reasoning training by providing step-level guidance without costly external models. While effective for unimodal text, we find that naively applying this global reward to vision-language (V-L) reasoning is a suboptimal strategy, as the task is a heterogeneous mix of sparse visual perception and dense textual reasoning. This global normalization creates mixture-induced signal degradation, where the training signal for visual steps is statistically distorted by the predominant textual steps. We propose Perception-Decomposed Confidence Reward (PDCR), a framework that solves this by aligning the reward structure with the task's heterogeneous nature. PDCR first performs an unsupervised skill decomposition, introducing a model-internal Visual Dependence Score to quantify visual reliance and applying a clustering algorithm to separate perception and reasoning steps. Based on this, PDCR computes a decomposed advantage by normalizing confidence gains within each skill cluster. This intra-cluster normalization provides a stable, correctly-scaled signal for both perception and reasoning. We demonstrate that PDCR outperforms the naive, global-reward formulation and sparse-reward baselines on key V-L reasoning benchmarks.
Something from Nothing: Data Augmentation for Robust Severity Level Estimation of Dysarthric Speech
Mar 16, 2026Dysarthric speech quality assessment (DSQA) is critical for clinical diagnostics and inclusive speech technologies. However, subjective evaluation is costly and difficult to scale, and the scarcity of labeled data limits robust objective modeling. To address this, we propose a three-stage framework that leverages unlabeled dysarthric speech and large-scale typical speech datasets to scale training. A teacher model first generates pseudo-labels for unlabeled samples, followed by weakly supervised pretraining using a label-aware contrastive learning strategy that exposes the model to diverse speakers and acoustic conditions. The pretrained model is then fine-tuned for the downstream DSQA task. Experiments on five unseen datasets spanning multiple etiologies and languages demonstrate the robustness of our approach. Our Whisper-based baseline significantly outperforms SOTA DSQA predictors such as SpICE, and the full framework achieves an average SRCC of 0.761 across unseen test datasets.
Towards Robust Dysarthric Speech Recognition: LLM-Agent Post-ASR Correction Beyond WER
Jan 29, 2026While Automatic Speech Recognition (ASR) is typically benchmarked by word error rate (WER), real-world applications ultimately hinge on semantic fidelity. This mismatch is particularly problematic for dysarthric speech, where articulatory imprecision and disfluencies can cause severe semantic distortions. To bridge this gap, we introduce a Large Language Model (LLM)-based agent for post-ASR correction: a Judge-Editor over the top-k ASR hypotheses that keeps high-confidence spans, rewrites uncertain segments, and operates in both zero-shot and fine-tuned modes. In parallel, we release SAP-Hypo5, the largest benchmark for dysarthric speech correction, to enable reproducibility and future exploration. Under multi-perspective evaluation, our agent achieves a 14.51% WER reduction alongside substantial semantic gains, including a +7.59 pp improvement in MENLI and +7.66 pp in Slot Micro F1 on challenging samples. Our analysis further reveals that WER is highly sensitive to domain shift, whereas semantic metrics correlate more closely with downstream task performance.
SICL-AT: Another way to adapt Auditory LLM to low-resource task
Jan 26, 2026Auditory Large Language Models (LLMs) have demonstrated strong performance across a wide range of speech and audio understanding tasks. Nevertheless, they often struggle when applied to low-resource or unfamiliar tasks. In case of labeled in-domain data is scarce or mismatched to the true test distribution, direct fine-tuning can be brittle. In-Context Learning (ICL) provides a training-free, inference-time solution by adapting auditory LLMs through conditioning on a few in-domain demonstrations. In this work, we first show that \emph{Vanilla ICL}, improves zero-shot performance across diverse speech and audio tasks for selected models which suggest this ICL adaptation capability can be generalized to multimodal setting. Building on this, we propose \textbf{Speech In-Context Learning Adaptation Training (SICL-AT)}, a post-training recipe utilizes only high resource speech data intending to strengthen model's in-context learning capability. The enhancement can generalize to audio understanding/reasoning task. Experiments indicate our proposed method consistently outperforms direct fine-tuning in low-resource scenario.
AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
TICL+: A Case Study On Speech In-Context Learning for Children's Speech Recognition
Dec 20, 2025Children's speech recognition remains challenging due to substantial acoustic and linguistic variability, limited labeled data, and significant differences from adult speech. Speech foundation models can address these challenges through Speech In-Context Learning (SICL), allowing adaptation to new domains without fine-tuning. However, the effectiveness of SICL depends on how in-context examples are selected. We extend an existing retrieval-based method, Text-Embedding KNN for SICL (TICL), introducing an acoustic reranking step to create TICL+. This extension prioritizes examples that are both semantically and acoustically aligned with the test input. Experiments on four children's speech corpora show that TICL+ achieves up to a 53.3% relative word error rate reduction over zero-shot performance and 37.6% over baseline TICL, highlighting the value of combining semantic and acoustic information for robust, scalable ASR in children's speech.
That's Deprecated! Understanding, Detecting, and Steering Knowledge Conflicts in Language Models for Code Generation
Oct 21, 2025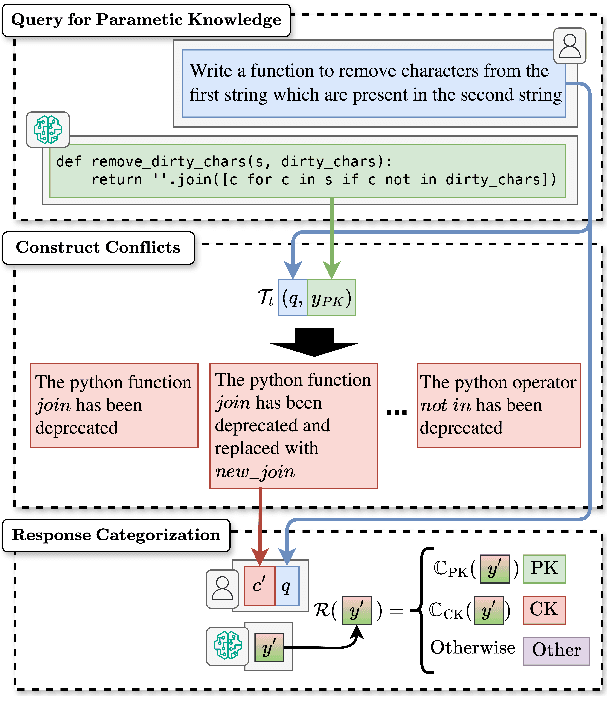
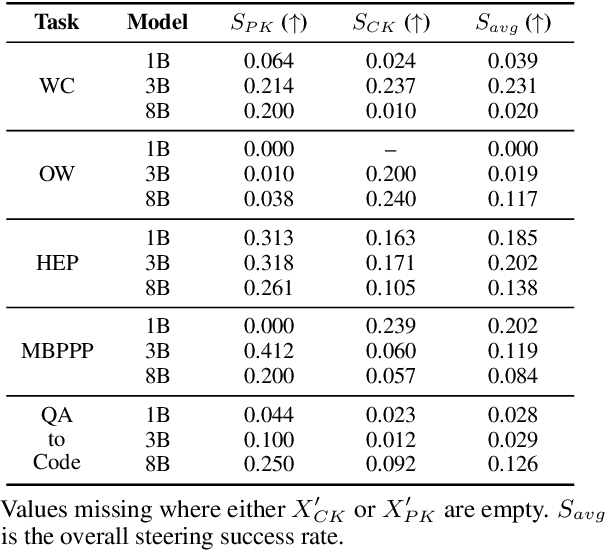
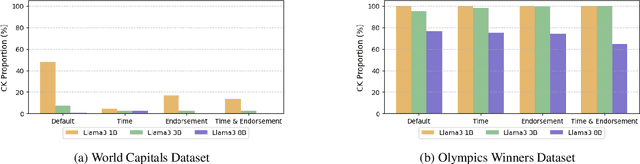
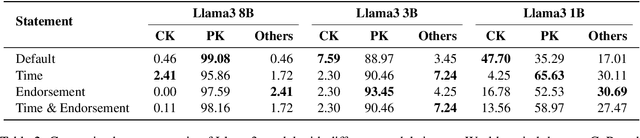
This paper investigates how large language models (LLMs) behave when faced with discrepancies between their parametric knowledge and conflicting information contained in a prompt. Building on prior question-answering (QA) research, we extend the investigation of knowledge conflicts to the realm of code generation. We propose a domain-agnostic framework for constructing and interpreting such conflicts, along with a novel evaluation method and dataset tailored to code conflict scenarios. Our experiments indicate that sufficiently large LLMs encode the notion of a knowledge conflict in their parameters, enabling us to detect knowledge conflicts with up to \textbf{80.65\%} accuracy. Building on these insights, we show that activation-level steering can achieve up to a \textbf{12.6\%} improvement in steering success over a random baseline. However, effectiveness depends critically on balancing model size, task domain, and steering direction. The experiment code and data will be made publicly available after acceptance.
The Interspeech 2025 Speech Accessibility Project Challenge
Jul 29, 2025While the last decade has witnessed significant advancements in Automatic Speech Recognition (ASR) systems, performance of these systems for individuals with speech disabilities remains inadequate, partly due to limited public training data. To bridge this gap, the 2025 Interspeech Speech Accessibility Project (SAP) Challenge was launched, utilizing over 400 hours of SAP data collected and transcribed from more than 500 individuals with diverse speech disabilities. Hosted on EvalAI and leveraging the remote evaluation pipeline, the SAP Challenge evaluates submissions based on Word Error Rate and Semantic Score. Consequently, 12 out of 22 valid teams outperformed the whisper-large-v2 baseline in terms of WER, while 17 teams surpassed the baseline on SemScore. Notably, the top team achieved the lowest WER of 8.11\%, and the highest SemScore of 88.44\% at the same time, setting new benchmarks for future ASR systems in recognizing impaired speech.