 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrectionLM: Self-Corrections with SLM for Dialogue State Tracking
Oct 23, 2024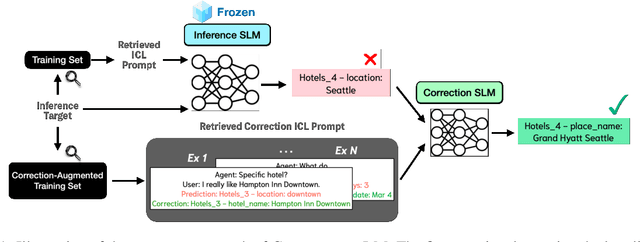


Large language models (LLMs) have demonstrated self-improvement capabilities via feedback and refinement, but current small language models (SLMs) have had limited success in this area. Existing correction approaches often rely on distilling knowledge from LLMs, which imposes significant computation demands. In this work, we introduce CORRECTIONLM, a novel correction framework that enables SLMs to self-correct using in-context exemplars without LLM involvement. Applied to two dialogue state tracking (DST) tasks in low-resource settings, CORRECTIONLM achieves results similar to a state-of-the-art LLM at a small fraction of the computation costs.
Just ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue
Sep 07, 2024
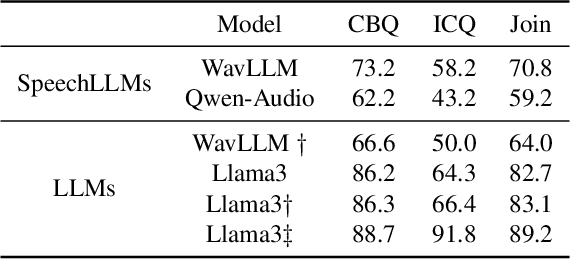
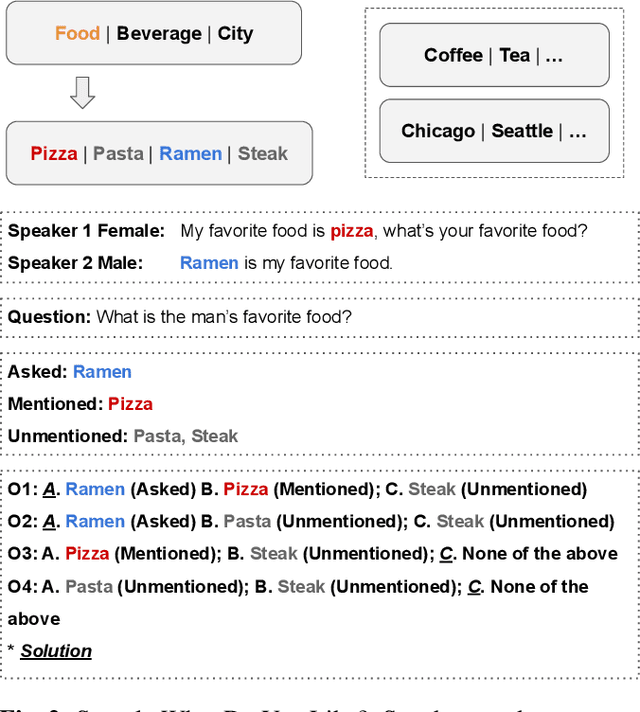
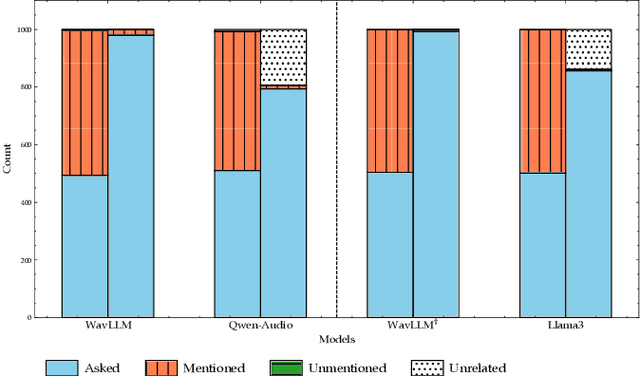
In recent years, we have observed a rapid advancement in speech language models (SpeechLLMs), catching up with humans' listening and reasoning abilities. Remarkably, SpeechLLMs have demonstrated impressive spoken dialogue question-answering (SQA) performance in benchmarks like Gaokao, the English listening test of the college entrance exam in China, which seemingly requires understanding both the spoken content and voice characteristics of speakers in a conversation. However, after carefully examining Gaokao's questions, we find the correct answers to many questions can be inferred from the conversation context alone without identifying the speaker asked in the question. Our evaluation of state-of-the-art models Qwen-Audio and WavLLM in both Gaokao and our proposed "What Do You Like?" dataset shows a significantly higher accuracy in these context-based questions than in identity-critical questions, which can only be answered correctly with correct speaker identification. Our results and analysis suggest that when solving SQA, the current SpeechLLMs exhibit limited speaker awareness from the audio and behave similarly to an LLM reasoning from the conversation transcription without sound. We propose that our definitions and automated classification of context-based and identity-critical questions could offer a more accurate evaluation framework of SpeechLLMs in SQA tasks.
Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models
Jun 13, 2024



Humans draw to facilitate reasoning: we draw auxiliary lines when solving geometry problems; we mark and circle when reasoning on maps; we use sketches to amplify our ideas and relieve our limited-capacity working memory. However, such actions are missing in current multimodal language models (LMs). Current chain-of-thought and tool-use paradigms only use text as intermediate reasoning steps. In this work, we introduce Sketchpad, a framework that gives multimodal LMs a visual sketchpad and tools to draw on the sketchpad. The LM conducts planning and reasoning according to the visual artifacts it has drawn. Different from prior work, which uses text-to-image models to enable LMs to draw, Sketchpad enables LMs to draw with lines, boxes, marks, etc., which is closer to human sketching and better facilitates reasoning. Sketchpad can also use specialist vision models during the sketching process (e.g., draw bounding boxes with object detection models, draw masks with segmentation models), to further enhance visual perception and reasoning. We experiment with a wide range of math tasks (including geometry, functions, graphs, and chess) and complex visual reasoning tasks. Sketchpad substantially improves performance on all tasks over strong base models with no sketching, yielding an average gain of 12.7% on math tasks, and 8.6% on vision tasks. GPT-4o with Sketchpad sets a new state of the art on all tasks, including V*Bench (80.3%), BLINK spatial reasoning (83.9%), and visual correspondence (80.8%). All codes and data are in https://visualsketchpad.github.io/.
Encode Once and Decode in Parallel: Efficient Transformer Decoding
Mar 19, 2024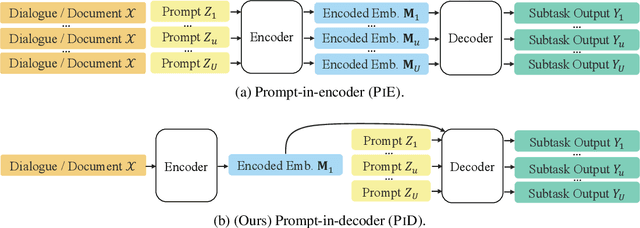

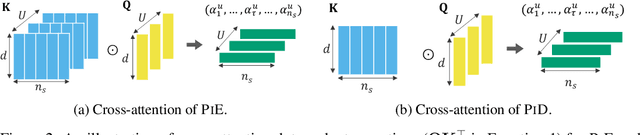
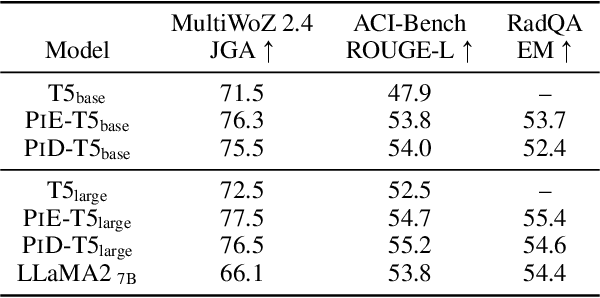
Transformer-based NLP models are powerful but have high computational costs that limit deployment scenarios. Finetuned encoder-decoder models are popular in specialized domains and can outperform larger more generalized decoder-only models, such as GPT-4. We introduce a new configuration for encoder-decoder models that improves efficiency on structured output and question-answering tasks where multiple outputs are required of a single input. Our method, prompt-in-decoder (PiD), encodes the input once and decodes output in parallel, boosting both training and inference efficiency by avoiding duplicate input encoding, thereby reducing the decoder's memory footprint. We achieve computation reduction that roughly scales with the number of subtasks, gaining up to 4.6x speed-up over state-of-the-art models for dialogue state tracking, summarization, and question-answering tasks with comparable or better performance. We release our training/inference code and checkpoints.
OrchestraLLM: Efficient Orchestration of Language Models for Dialogue State Tracking
Nov 16, 2023



Large language models (LLMs) have revolutionized the landscape of Natural Language Processing systems, but are computationally expensive. To reduce the cost without sacrificing performance, previous studies have explored various approaches to harness the potential of Small Language Models (SLMs) as cost-effective alternatives to their larger counterparts. Driven by findings that SLMs and LLMs exhibit complementary strengths in a structured knowledge extraction task, this work presents a novel SLM/LLM routing framework designed to improve computational efficiency and enhance task performance. First, exemplar pools are created to represent the types of contexts where each LM provides a more reliable answer, leveraging a sentence embedding fine-tuned so that context similarity is close to dialogue state similarity. Then, during inference, the k-nearest exemplars to the testing instance are retrieved, and the instance is routed according to majority vote. In dialogue state tracking tasks, the proposed routing framework enhances performance substantially compared to relying solely on LLMs, while reducing the computational costs by over 50%.
DIALGEN: Collaborative Human-LM Generated Dialogues for Improved Understanding of Human-Human Conversations
Jul 13, 2023



Applications that could benefit from automatic understanding of human-human conversations often come with challenges associated with private information in real-world data such as call center or clinical conversations. Working with protected data also increases costs of annotation, which limits technology development. To address these challenges, we propose DIALGEN, a human-in-the-loop semi-automated dialogue generation framework. DIALGEN uses a language model (ChatGPT) that can follow schema and style specifications to produce fluent conversational text, generating a complex conversation through iteratively generating subdialogues and using human feedback to correct inconsistencies or redirect the flow. In experiments on structured summarization of agent-client information gathering calls, framed as dialogue state tracking, we show that DIALGEN data enables significant improvement in model performance.
Building blocks for complex tasks: Robust generative event extraction for radiology reports under domain shifts
Jun 15, 2023This paper explores methods for extracting information from radiology reports that generalize across exam modalities to reduce requirements for annotated data. We demonstrate that multi-pass T5-based text-to-text generative models exhibit better generalization across exam modalities compared to approaches that employ BERT-based task-specific classification layers. We then develop methods that reduce the inference cost of the model, making large-scale corpus processing more feasible for clinical applications. Specifically, we introduce a generative technique that decomposes complex tasks into smaller subtask blocks, which improves a single-pass model when combined with multitask training. In addition, we leverage target-domain contexts during inference to enhance domain adaptation, enabling use of smaller models. Analyses offer insights into the benefits of different cost reduction strategies.
Fine-Grained Human Feedback Gives Better Rewards for Language Model Training
Jun 02, 2023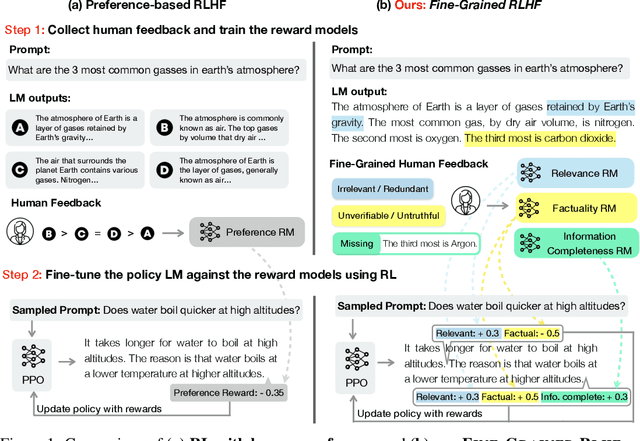
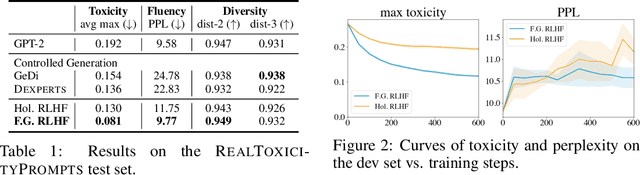

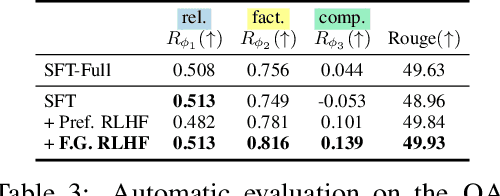
Language models (LMs) often exhibit undesirable text generation behaviors, including generating false, toxic, or irrelevant outputs. Reinforcement learning from human feedback (RLHF) - where human preference judgments on LM outputs are transformed into a learning signal - has recently shown promise in addressing these issues. However, such holistic feedback conveys limited information on long text outputs; it does not indicate which aspects of the outputs influenced user preference; e.g., which parts contain what type(s) of errors. In this paper, we use fine-grained human feedback (e.g., which sentence is false, which sub-sentence is irrelevant) as an explicit training signal. We introduce Fine-Grained RLHF, a framework that enables training and learning from reward functions that are fine-grained in two respects: (1) density, providing a reward after every segment (e.g., a sentence) is generated; and (2) incorporating multiple reward models associated with different feedback types (e.g., factual incorrectness, irrelevance, and information incompleteness). We conduct experiments on detoxification and long-form question answering to illustrate how learning with such reward functions leads to improved performance, supported by both automatic and human evaluation. Additionally, we show that LM behaviors can be customized using different combinations of fine-grained reward models. We release all data, collected human feedback, and codes at https://FineGrainedRLHF.github.io.
TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering
Mar 28, 2023Despite thousands of researchers, engineers, and artists actively working on improving text-to-image generation models, systems often fail to produce images that accurately align with the text inputs. We introduce TIFA (Text-to-Image Faithfulness evaluation with question Answering), an automatic evaluation metric that measures the faithfulness of a generated image to its text input via visual question answering (VQA). Specifically, given a text input, we automatically generate several question-answer pairs using a language model. We calculate image faithfulness by checking whether existing VQA models can answer these questions using the generated image. TIFA is a reference-free metric that allows for fine-grained and interpretable evaluations of generated images. TIFA also has better correlations with human judgments than existing metrics. Based on this approach, we introduce TIFA v1.0, a benchmark consisting of 4K diverse text inputs and 25K questions across 12 categories (object, counting, etc.). We present a comprehensive evaluation of existing text-to-image models using TIFA v1.0 and highlight the limitations and challenges of current models. For instance, we find that current text-to-image models, despite doing well on color and material, still struggle in counting, spatial relations, and composing multiple objects. We hope our benchmark will help carefully measure the research progress in text-to-image synthesis and provide valuable insights for further research.
One Embedder, Any Task: Instruction-Finetuned Text Embeddings
Dec 20, 2022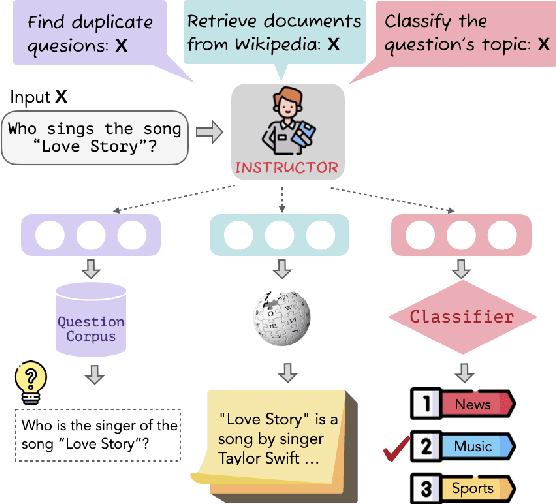
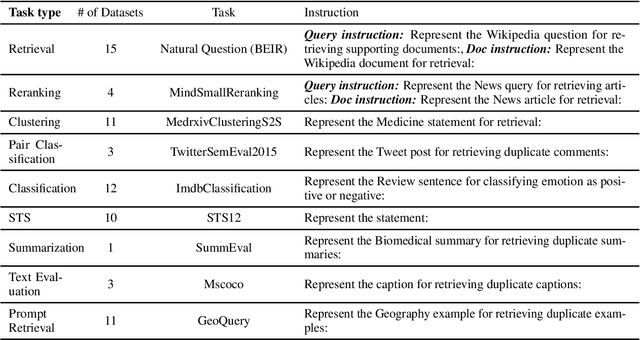
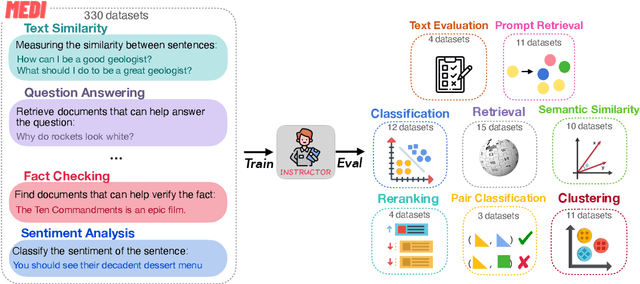
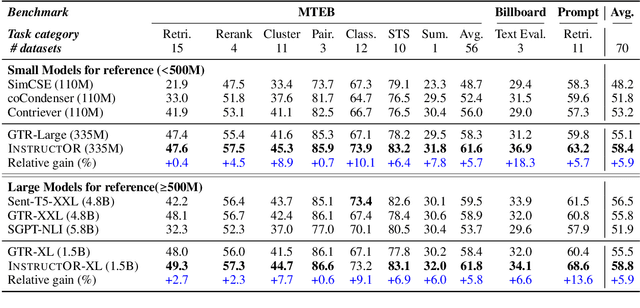
We introduce INSTRUCTOR, a new method for computing text embeddings given task instructions: every text input is embedded together with instructions explaining the use case (e.g., task and domain descriptions). Unlike encoders from prior work that are more specialized, INSTRUCTOR is a single embedder that can generate text embeddings tailored to different downstream tasks and domains, without any further training. We first annotate instructions for 330 diverse tasks and train INSTRUCTOR on this multitask mixture with a contrastive loss. We evaluate INSTRUCTOR on 70 embedding evaluation tasks (66 of which are unseen during training), ranging from classification and information retrieval to semantic textual similarity and text generation evaluation. INSTRUCTOR, while having an order of magnitude fewer parameters than the previous best model, achieves state-of-the-art performance, with an average improvement of 3.4% compared to the previous best results on the 70 diverse datasets. Our analysis suggests that INSTRUCTOR is robust to changes in instructions, and that instruction finetuning mitigates the challenge of training a single model on diverse datasets. Our model, code, and data are available at https://instructor-embedding.github.io.