 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue
Paper and Code

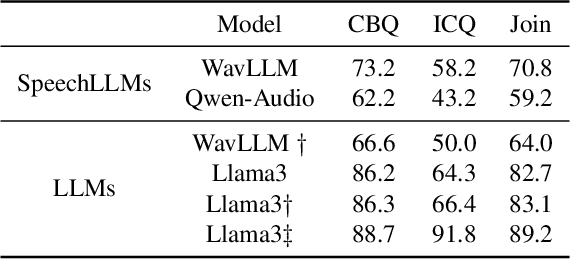
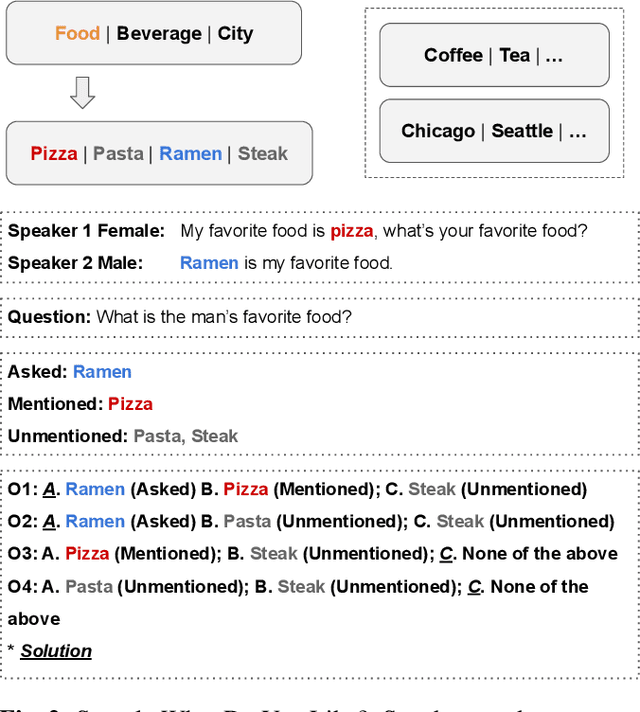
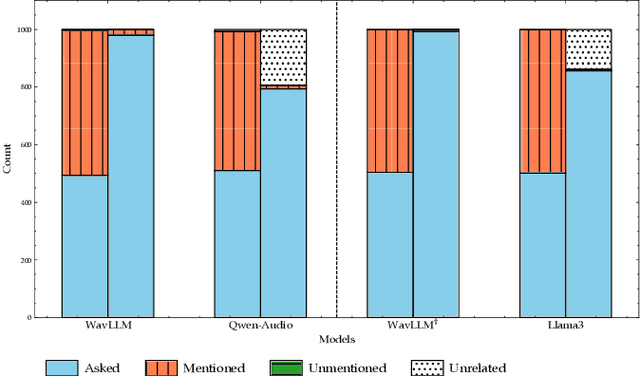
In recent years, we have observed a rapid advancement in speech language models (SpeechLLMs), catching up with humans' listening and reasoning abilities. Remarkably, SpeechLLMs have demonstrated impressive spoken dialogue question-answering (SQA) performance in benchmarks like Gaokao, the English listening test of the college entrance exam in China, which seemingly requires understanding both the spoken content and voice characteristics of speakers in a conversation. However, after carefully examining Gaokao's questions, we find the correct answers to many questions can be inferred from the conversation context alone without identifying the speaker asked in the question. Our evaluation of state-of-the-art models Qwen-Audio and WavLLM in both Gaokao and our proposed "What Do You Like?" dataset shows a significantly higher accuracy in these context-based questions than in identity-critical questions, which can only be answered correctly with correct speaker identification. Our results and analysis suggest that when solving SQA, the current SpeechLLMs exhibit limited speaker awareness from the audio and behave similarly to an LLM reasoning from the conversation transcription without sound. We propose that our definitions and automated classification of context-based and identity-critical questions could offer a more accurate evaluation framework of SpeechLLMs in SQA tasks.