 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
SightSound-R1: Cross-Modal Reasoning Distillation from Vision to Audio Language Models
Sep 19, 2025While large audio-language models (LALMs) have demonstrated state-of-the-art audio understanding, their reasoning capability in complex soundscapes still falls behind large vision-language models (LVLMs). Compared to the visual domain, one bottleneck is the lack of large-scale chain-of-thought audio data to teach LALM stepwise reasoning. To circumvent this data and modality gap, we present SightSound-R1, a cross-modal distillation framework that transfers advanced reasoning from a stronger LVLM teacher to a weaker LALM student on the same audio-visual question answering (AVQA) dataset. SightSound-R1 consists of three core steps: (i) test-time scaling to generate audio-focused chains of thought (CoT) from an LVLM teacher, (ii) audio-grounded validation to filter hallucinations, and (iii) a distillation pipeline with supervised fine-tuning (SFT) followed by Group Relative Policy Optimization (GRPO) for the LALM student. Results show that SightSound-R1 improves LALM reasoning performance both in the in-domain AVQA test set as well as in unseen auditory scenes and questions, outperforming both pretrained and label-only distilled baselines. Thus, we conclude that vision reasoning can be effectively transferred to audio models and scaled with abundant audio-visual data.
Bridging Ears and Eyes: Analyzing Audio and Visual Large Language Models to Humans in Visible Sound Recognition and Reducing Their Sensory Gap via Cross-Modal Distillation
May 11, 2025Audio large language models (LLMs) are considered experts at recognizing sound objects, yet their performance relative to LLMs in other sensory modalities, such as visual or audio-visual LLMs, and to humans using their ears, eyes, or both remains unexplored. To investigate this, we systematically evaluate audio, visual, and audio-visual LLMs, specifically Qwen2-Audio, Qwen2-VL, and Qwen2.5-Omni, against humans in recognizing sound objects of different classes from audio-only, silent video, or sounded video inputs. We uncover a performance gap between Qwen2-Audio and Qwen2-VL that parallels the sensory discrepancy between human ears and eyes. To reduce this gap, we introduce a cross-modal distillation framework, where an LLM in one modality serves as the teacher and another as the student, with knowledge transfer in sound classes predicted as more challenging to the student by a heuristic model. Distillation in both directions, from Qwen2-VL to Qwen2-Audio and vice versa, leads to notable improvements, particularly in challenging classes. This work highlights the sensory gap in LLMs from a human-aligned perspective and proposes a principled approach to enhancing modality-specific perception in multimodal LLMs.
Just ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue
Sep 07, 2024
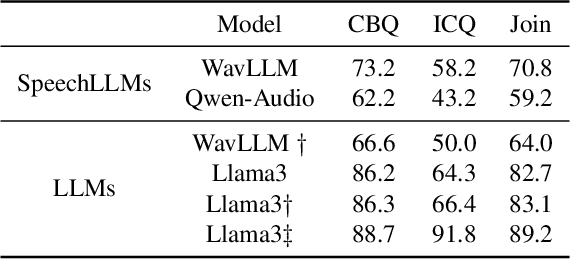
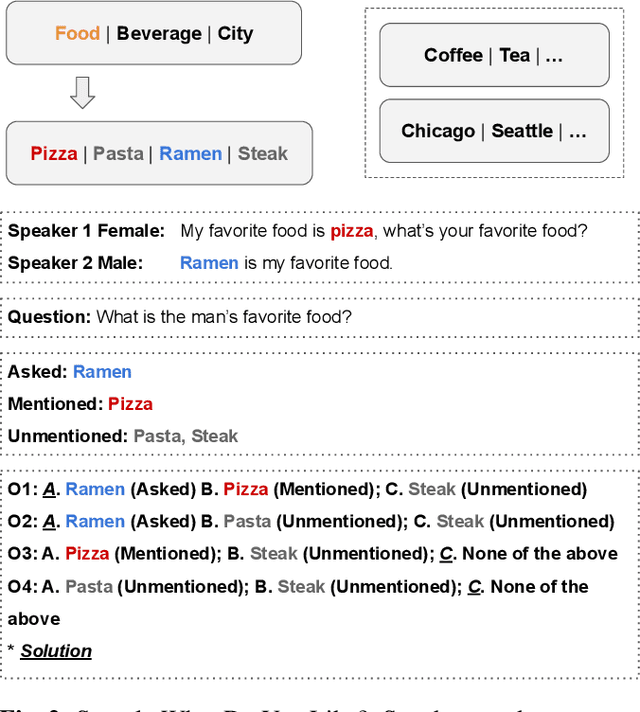
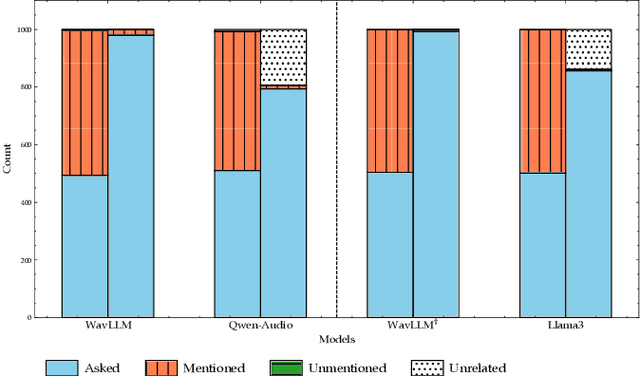
In recent years, we have observed a rapid advancement in speech language models (SpeechLLMs), catching up with humans' listening and reasoning abilities. Remarkably, SpeechLLMs have demonstrated impressive spoken dialogue question-answering (SQA) performance in benchmarks like Gaokao, the English listening test of the college entrance exam in China, which seemingly requires understanding both the spoken content and voice characteristics of speakers in a conversation. However, after carefully examining Gaokao's questions, we find the correct answers to many questions can be inferred from the conversation context alone without identifying the speaker asked in the question. Our evaluation of state-of-the-art models Qwen-Audio and WavLLM in both Gaokao and our proposed "What Do You Like?" dataset shows a significantly higher accuracy in these context-based questions than in identity-critical questions, which can only be answered correctly with correct speaker identification. Our results and analysis suggest that when solving SQA, the current SpeechLLMs exhibit limited speaker awareness from the audio and behave similarly to an LLM reasoning from the conversation transcription without sound. We propose that our definitions and automated classification of context-based and identity-critical questions could offer a more accurate evaluation framework of SpeechLLMs in SQA tasks.
Meta-AF Echo Cancellation for Improved Keyword Spotting
Dec 17, 2023Adaptive filters (AFs) are vital for enhancing the performance of downstream tasks, such as speech recognition, sound event detection, and keyword spotting. However, traditional AF design prioritizes isolated signal-level objectives, often overlooking downstream task performance. This can lead to suboptimal performance. Recent research has leveraged meta-learning to automatically learn AF update rules from data, alleviating the need for manual tuning when using simple signal-level objectives. This paper improves the Meta-AF framework by expanding it to support end-to-end training for arbitrary downstream tasks. We focus on classification tasks, where we introduce a novel training methodology that harnesses self-supervision and classifier feedback. We evaluate our approach on the combined task of acoustic echo cancellation and keyword spotting. Our findings demonstrate consistent performance improvements with both pre-trained and joint-trained keyword spotting models across synthetic and real playback. Notably, these improvements come without requiring additional tuning, increased inference-time complexity, or reliance on oracle signal-level training data.
Unsupervised Improvement of Audio-Text Cross-Modal Representations
May 05, 2023Recent advances in using language models to obtain cross-modal audio-text representations have overcome the limitations of conventional training approaches that use predefined labels. This has allowed the community to make progress in tasks like zero-shot classification, which would otherwise not be possible. However, learning such representations requires a large amount of human-annotated audio-text pairs. In this paper, we study unsupervised approaches to improve the learning framework of such representations with unpaired text and audio. We explore domain-unspecific and domain-specific curation methods to create audio-text pairs that we use to further improve the model. We also show that when domain-specific curation is used in conjunction with a soft-labeled contrastive loss, we are able to obtain significant improvement in terms of zero-shot classification performance on downstream sound event classification or acoustic scene classification tasks.
Meta-Learning for Adaptive Filters with Higher-Order Frequency Dependencies
Sep 20, 2022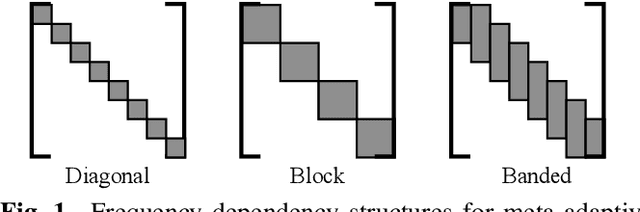
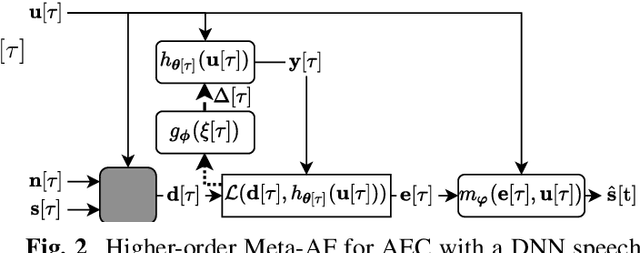
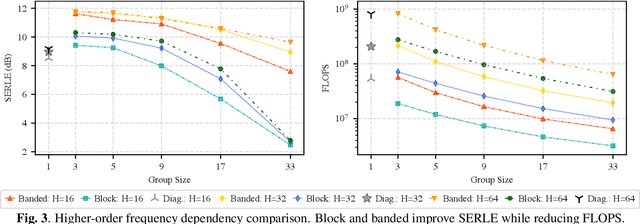
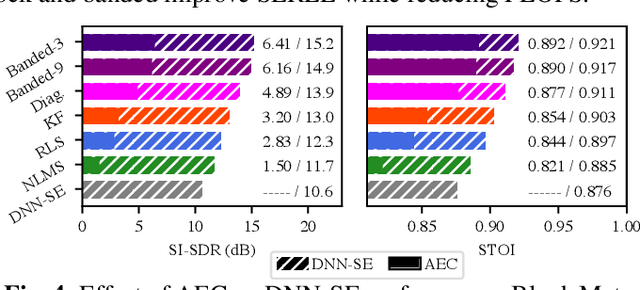
Adaptive filters are applicable to many signal processing tasks including acoustic echo cancellation, beamforming, and more. Adaptive filters are typically controlled using algorithms such as least-mean squares(LMS), recursive least squares(RLS), or Kalman filter updates. Such models are often applied in the frequency domain, assume frequency independent processing, and do not exploit higher-order frequency dependencies, for simplicity. Recent work on meta-adaptive filters, however, has shown that we can control filter adaptation using neural networks without manual derivation, motivating new work to exploit such information. In this work, we present higher-order meta-adaptive filters, a key improvement to meta-adaptive filters that incorporates higher-order frequency dependencies. We demonstrate our approach on acoustic echo cancellation and develop a family of filters that yield multi-dB improvements over competitive baselines, and are at least an order-of-magnitude less complex. Moreover, we show our improvements hold with or without a downstream speech enhancer.
Learning Representations for New Sound Classes With Continual Self-Supervised Learning
May 15, 2022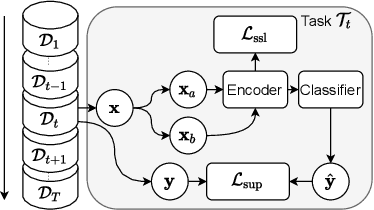
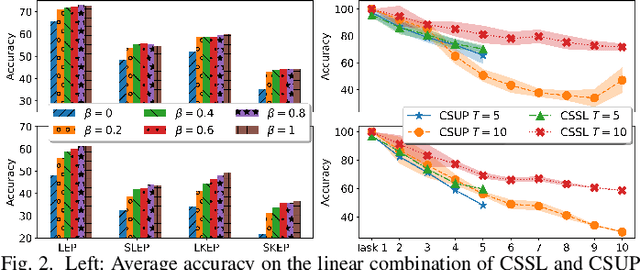
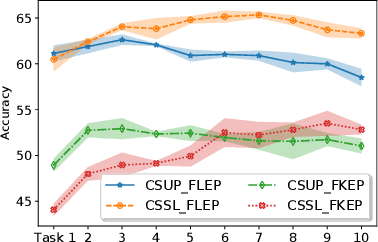
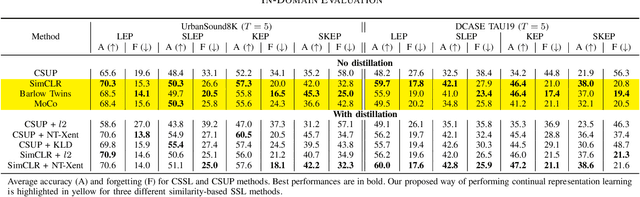
In this paper, we present a self-supervised learning framework for continually learning representations for new sound classes. The proposed system relies on a continually trained neural encoder that is trained with similarity-based learning objectives without using labels. We show that representations learned with the proposed method generalize better and are less susceptible to catastrophic forgetting than fully-supervised approaches. Remarkably, our technique does not store past data or models and is more computationally efficient than distillation-based methods. To accurately assess the system performance, in addition to using existing protocols, we propose two realistic evaluation protocols that use only a small amount of labeled data to simulate practical use cases.