 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Non-Negative Matrix Factorization with Implicit Neural Representations
Apr 05, 2024



Non-negative Matrix Factorization (NMF) is a powerful technique for analyzing regularly-sampled data, i.e., data that can be stored in a matrix. For audio, this has led to numerous applications using time-frequency (TF) representations like the Short-Time Fourier Transform. However extending these applications to irregularly-spaced TF representations, like the Constant-Q transform, wavelets, or sinusoidal analysis models, has not been possible since these representations cannot be directly stored in matrix form. In this paper, we formulate NMF in terms of continuous functions (instead of fixed vectors) and show that NMF can be extended to a wider variety of signal classes that need not be regularly sampled.
Noise-Robust DSP-Assisted Neural Pitch Estimation with Very Low Complexity
Sep 25, 2023Pitch estimation is an essential step of many speech processing algorithms, including speech coding, synthesis, and enhancement. Recently, pitch estimators based on deep neural networks (DNNs) have have been outperforming well-established DSP-based techniques. Unfortunately, these new estimators can be impractical to deploy in real-time systems, both because of their relatively high complexity, and the fact that some require significant lookahead. We show that a hybrid estimator using a small deep neural network (DNN) with traditional DSP-based features can match or exceed the performance of pure DNN-based models, with a complexity and algorithmic delay comparable to traditional DSP-based algorithms. We further demonstrate that this hybrid approach can provide benefits for a neural vocoding task.
Unsupervised Improvement of Audio-Text Cross-Modal Representations
May 05, 2023Recent advances in using language models to obtain cross-modal audio-text representations have overcome the limitations of conventional training approaches that use predefined labels. This has allowed the community to make progress in tasks like zero-shot classification, which would otherwise not be possible. However, learning such representations requires a large amount of human-annotated audio-text pairs. In this paper, we study unsupervised approaches to improve the learning framework of such representations with unpaired text and audio. We explore domain-unspecific and domain-specific curation methods to create audio-text pairs that we use to further improve the model. We also show that when domain-specific curation is used in conjunction with a soft-labeled contrastive loss, we are able to obtain significant improvement in terms of zero-shot classification performance on downstream sound event classification or acoustic scene classification tasks.
End-to-end LPCNet: A Neural Vocoder With Fully-Differentiable LPC Estimation
Mar 29, 2022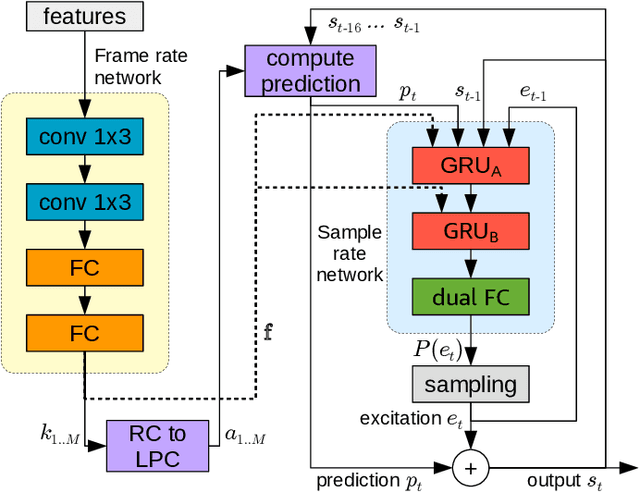

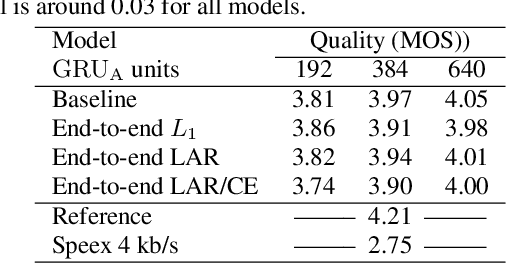
Neural vocoders have recently demonstrated high quality speech synthesis, but typically require a high computational complexity. LPCNet was proposed as a way to reduce the complexity of neural synthesis by using linear prediction (LP) to assist an autoregressive model. At inference time, LPCNet relies on the LP coefficients being explicitly computed from the input acoustic features. That makes the design of LPCNet-based systems more complicated, while adding the constraint that the input features must represent a clean speech spectrum. We propose an end-to-end version of LPCNet that lifts these limitations by learning to infer the LP coefficients from the input features in the frame rate network. Results show that the proposed end-to-end approach equals or exceeds the quality of the original LPCNet model, but without explicit LP analysis. Our open-source end-to-end model still benefits from LPCNet's low complexity, while allowing for any type of conditioning features.
Point Cloud Audio Processing
May 06, 2021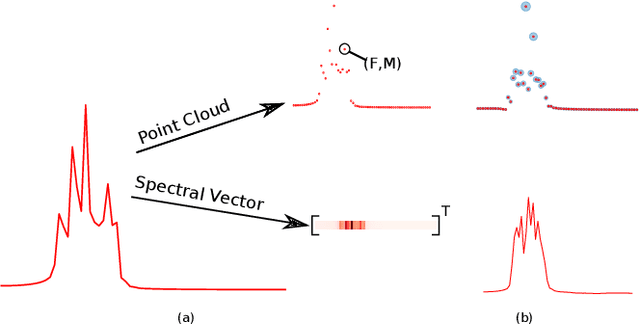
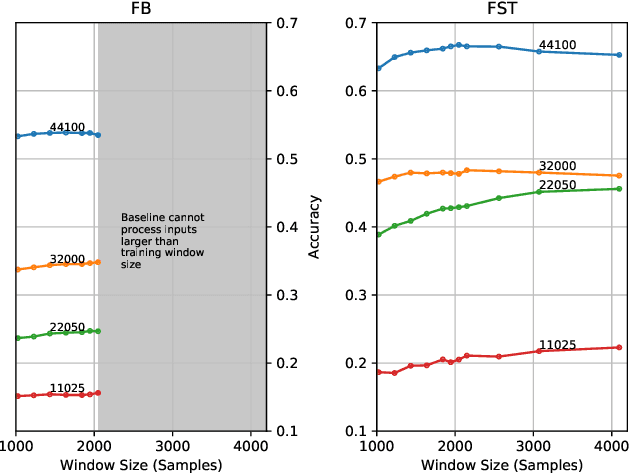
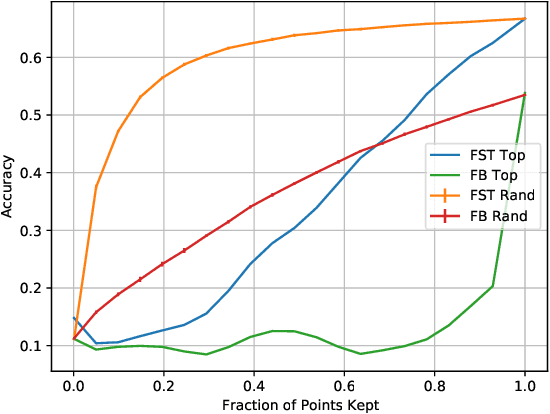
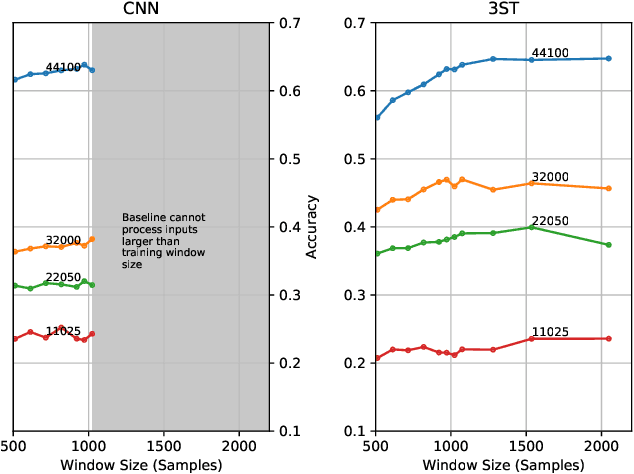
Most audio processing pipelines involve transformations that act on fixed-dimensional input representations of audio. For example, when using the Short Time Fourier Transform (STFT) the DFT size specifies a fixed dimension for the input representation. As a consequence, most audio machine learning models are designed to process fixed-size vector inputs which often prohibits the repurposing of learned models on audio with different sampling rates or alternative representations. We note, however, that the intrinsic spectral information in the audio signal is invariant to the choice of the input representation or the sampling rate. Motivated by this, we introduce a novel way of processing audio signals by treating them as a collection of points in feature space, and we use point cloud machine learning models that give us invariance to the choice of representation parameters, such as DFT size or the sampling rate. Additionally, we observe that these methods result in smaller models, and allow us to significantly subsample the input representation with minimal effects to a trained model performance.
Optimizing Short-Time Fourier Transform Parameters via Gradient Descent
Oct 28, 2020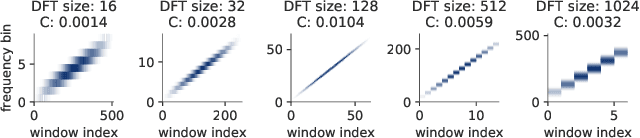
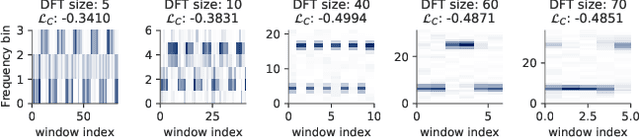
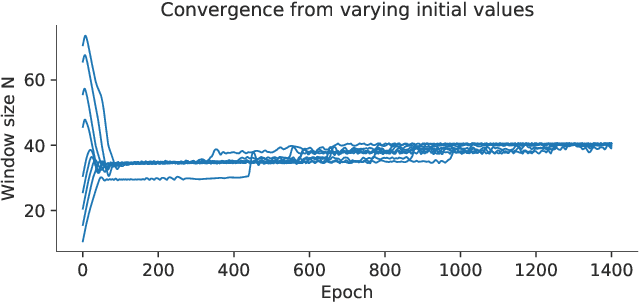
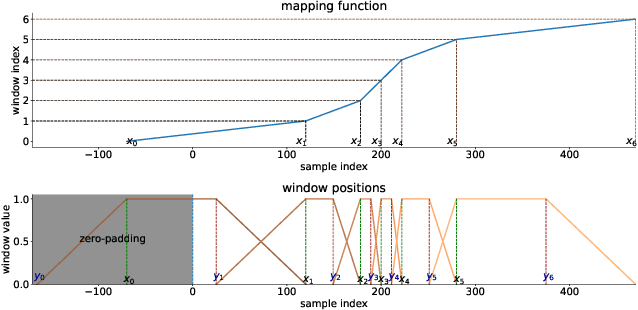
The Short-Time Fourier Transform (STFT) has been a staple of signal processing, often being the first step for many audio tasks. A very familiar process when using the STFT is the search for the best STFT parameters, as they often have significant side effects if chosen poorly. These parameters are often defined in terms of an integer number of samples, which makes their optimization non-trivial. In this paper we show an approach that allows us to obtain a gradient for STFT parameters with respect to arbitrary cost functions, and thus enable the ability to employ gradient descent optimization of quantities like the STFT window length, or the STFT hop size. We do so for parameter values that stay constant throughout an input, but also for cases where these parameters have to dynamically change over time to accommodate varying signal characteristics.
HpRNet : Incorporating Residual Noise Modeling for Violin in a Variational Parametric Synthesizer
Aug 19, 2020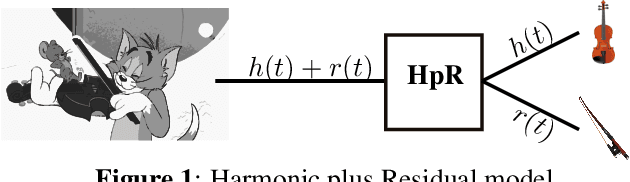



Generative Models for Audio Synthesis have been gaining momentum in the last few years. More recently, parametric representations of the audio signal have been incorporated to facilitate better musical control of the synthesized output. In this work, we investigate a parametric model for violin tones, in particular the generative modeling of the residual bow noise to make for more natural tone quality. To aid in our analysis, we introduce a dataset of Carnatic Violin Recordings where bow noise is an integral part of the playing style of higher pitched notes in specific gestural contexts. We obtain insights about each of the harmonic and residual components of the signal, as well as their interdependence, via observations on the latent space derived in the course of variational encoding of the spectral envelopes of the sustained sounds.
VaPar Synth -- A Variational Parametric Model for Audio Synthesis
Mar 30, 2020

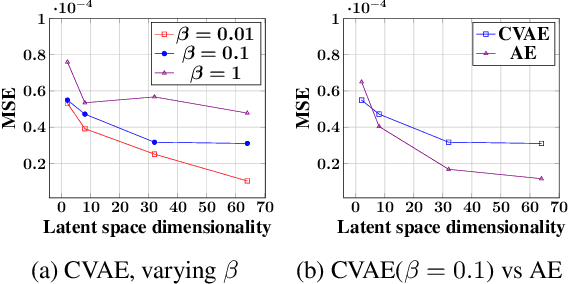
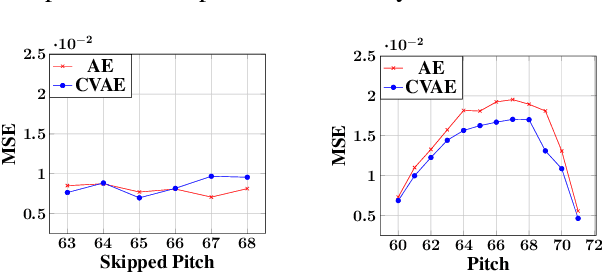
With the advent of data-driven statistical modeling and abundant computing power, researchers are turning increasingly to deep learning for audio synthesis. These methods try to model audio signals directly in the time or frequency domain. In the interest of more flexible control over the generated sound, it could be more useful to work with a parametric representation of the signal which corresponds more directly to the musical attributes such as pitch, dynamics and timbre. We present VaPar Synth - a Variational Parametric Synthesizer which utilizes a conditional variational autoencoder (CVAE) trained on a suitable parametric representation. We demonstrate our proposed model's capabilities via the reconstruction and generation of instrumental tones with flexible control over their pitch.
Generative Audio Synthesis with a Parametric Model
Nov 15, 2019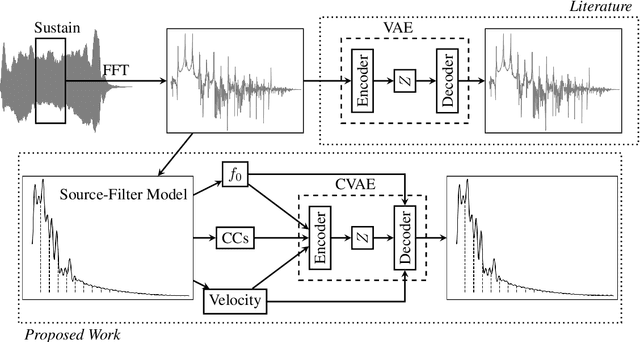
Use a parametric representation of audio to train a generative model in the interest of obtaining more flexible control over the generated sound.