 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbisonics Super-Resolution Using A Waveform-Domain Neural Network
Aug 01, 2025Ambisonics is a spatial audio format describing a sound field. First-order Ambisonics (FOA) is a popular format comprising only four channels. This limited channel count comes at the expense of spatial accuracy. Ideally one would be able to take the efficiency of a FOA format without its limitations. We have devised a data-driven spatial audio solution that retains the efficiency of the FOA format but achieves quality that surpasses conventional renderers. Utilizing a fully convolutional time-domain audio neural network (Conv-TasNet), we created a solution that takes a FOA input and provides a higher order Ambisonics (HOA) output. This data driven approach is novel when compared to typical physics and psychoacoustic based renderers. Quantitative evaluations showed a 0.6dB average positional mean squared error difference between predicted and actual 3rd order HOA. The median qualitative rating showed an 80% improvement in perceived quality over the traditional rendering approach.
ImmerseDiffusion: A Generative Spatial Audio Latent Diffusion Model
Oct 19, 2024



We introduce ImmerseDiffusion, an end-to-end generative audio model that produces 3D immersive soundscapes conditioned on the spatial, temporal, and environmental conditions of sound objects. ImmerseDiffusion is trained to generate first-order ambisonics (FOA) audio, which is a conventional spatial audio format comprising four channels that can be rendered to multichannel spatial output. The proposed generative system is composed of a spatial audio codec that maps FOA audio to latent components, a latent diffusion model trained based on various user input types, namely, text prompts, spatial, temporal and environmental acoustic parameters, and optionally a spatial audio and text encoder trained in a Contrastive Language and Audio Pretraining (CLAP) style. We propose metrics to evaluate the quality and spatial adherence of the generated spatial audio. Finally, we assess the model performance in terms of generation quality and spatial conformance, comparing the two proposed modes: ``descriptive", which uses spatial text prompts) and ``parametric", which uses non-spatial text prompts and spatial parameters. Our evaluations demonstrate promising results that are consistent with the user conditions and reflect reliable spatial fidelity.
Rethinking Non-Negative Matrix Factorization with Implicit Neural Representations
Apr 05, 2024



Non-negative Matrix Factorization (NMF) is a powerful technique for analyzing regularly-sampled data, i.e., data that can be stored in a matrix. For audio, this has led to numerous applications using time-frequency (TF) representations like the Short-Time Fourier Transform. However extending these applications to irregularly-spaced TF representations, like the Constant-Q transform, wavelets, or sinusoidal analysis models, has not been possible since these representations cannot be directly stored in matrix form. In this paper, we formulate NMF in terms of continuous functions (instead of fixed vectors) and show that NMF can be extended to a wider variety of signal classes that need not be regularly sampled.
Resource-constrained stereo singing voice cancellation
Jan 22, 2024We study the problem of stereo singing voice cancellation, a subtask of music source separation, whose goal is to estimate an instrumental background from a stereo mix. We explore how to achieve performance similar to large state-of-the-art source separation networks starting from a small, efficient model for real-time speech separation. Such a model is useful when memory and compute are limited and singing voice processing has to run with limited look-ahead. In practice, this is realised by adapting an existing mono model to handle stereo input. Improvements in quality are obtained by tuning model parameters and expanding the training set. Moreover, we highlight the benefits a stereo model brings by introducing a new metric which detects attenuation inconsistencies between channels. Our approach is evaluated using objective offline metrics and a large-scale MUSHRA trial, confirming the effectiveness of our techniques in stringent listening tests.
Dynamic curriculum learning via data parameters for noise robust keyword spotting
Feb 18, 2021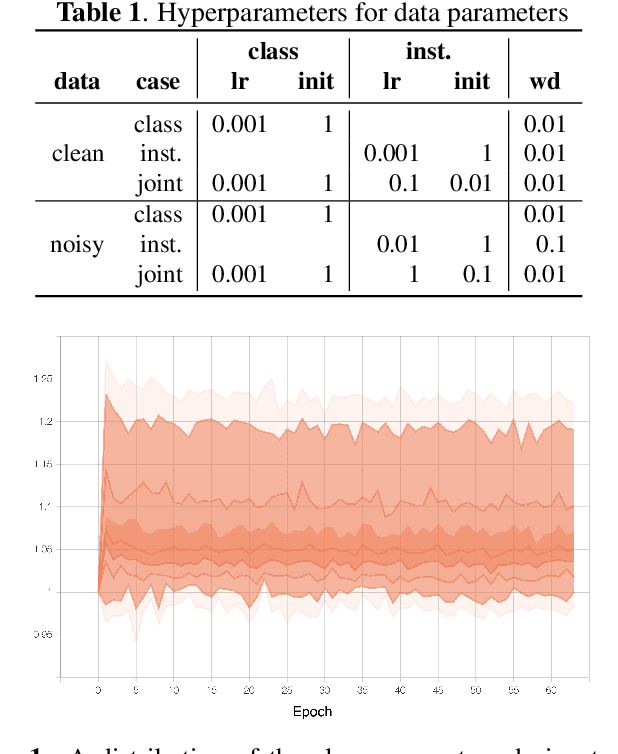
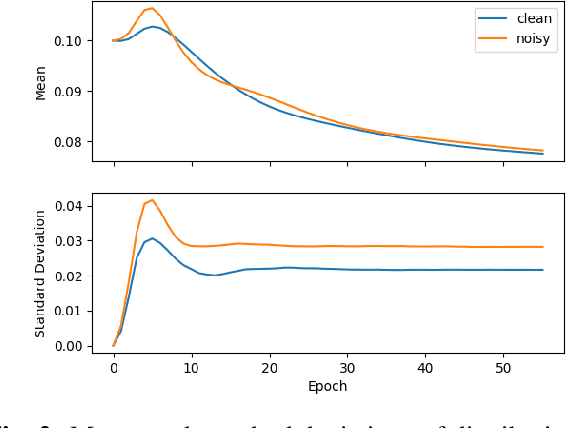
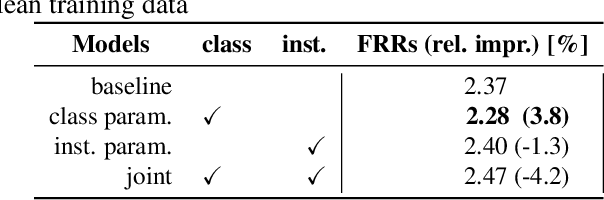

We propose dynamic curriculum learning via data parameters for noise robust keyword spotting. Data parameter learning has recently been introduced for image processing, where weight parameters, so-called data parameters, for target classes and instances are introduced and optimized along with model parameters. The data parameters scale logits and control importance over classes and instances during training, which enables automatic curriculum learning without additional annotations for training data. Similarly, in this paper, we propose using this curriculum learning approach for acoustic modeling, and train an acoustic model on clean and noisy utterances with the data parameters. The proposed approach automatically learns the difficulty of the classes and instances, e.g. due to low speech to noise ratio (SNR), in the gradient descent optimization and performs curriculum learning. This curriculum learning leads to overall improvement of the accuracy of the acoustic model. We evaluate the effectiveness of the proposed approach on a keyword spotting task. Experimental results show 7.7% relative reduction in false reject ratio with the data parameters compared to a baseline model which is simply trained on the multiconditioned dataset.