 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGencho: Room Impulse Response Generation from Reverberant Speech and Text via Diffusion Transformers
Feb 09, 2026Blind room impulse response (RIR) estimation is a core task for capturing and transferring acoustic properties; yet existing methods often suffer from limited modeling capability and degraded performance under unseen conditions. Moreover, emerging generative audio applications call for more flexible impulse response generation methods. We propose Gencho, a diffusion-transformer-based model that predicts complex spectrogram RIRs from reverberant speech. A structure-aware encoder leverages isolation between early and late reflections to encode the input audio into a robust representation for conditioning, while the diffusion decoder generates diverse and perceptually realistic impulse responses from it. Gencho integrates modularly with standard speech processing pipelines for acoustic matching. Results show richer generated RIRs than non-generative baselines while maintaining strong performance in standard RIR metrics. We further demonstrate its application to text-conditioned RIR generation, highlighting Gencho's versatility for controllable acoustic simulation and generative audio tasks.
PromptSep: Generative Audio Separation via Multimodal Prompting
Nov 06, 2025Recent breakthroughs in language-queried audio source separation (LASS) have shown that generative models can achieve higher separation audio quality than traditional masking-based approaches. However, two key limitations restrict their practical use: (1) users often require operations beyond separation, such as sound removal; and (2) relying solely on text prompts can be unintuitive for specifying sound sources. In this paper, we propose PromptSep to extend LASS into a broader framework for general-purpose sound separation. PromptSep leverages a conditional diffusion model enhanced with elaborated data simulation to enable both audio extraction and sound removal. To move beyond text-only queries, we incorporate vocal imitation as an additional and more intuitive conditioning modality for our model, by incorporating Sketch2Sound as a data augmentation strategy. Both objective and subjective evaluations on multiple benchmarks demonstrate that PromptSep achieves state-of-the-art performance in sound removal and vocal-imitation-guided source separation, while maintaining competitive results on language-queried source separation.
Re-Bottleneck: Latent Re-Structuring for Neural Audio Autoencoders
Jul 10, 2025Neural audio codecs and autoencoders have emerged as versatile models for audio compression, transmission, feature-extraction, and latent-space generation. However, a key limitation is that most are trained to maximize reconstruction fidelity, often neglecting the specific latent structure necessary for optimal performance in diverse downstream applications. We propose a simple, post-hoc framework to address this by modifying the bottleneck of a pre-trained autoencoder. Our method introduces a "Re-Bottleneck", an inner bottleneck trained exclusively through latent space losses to instill user-defined structure. We demonstrate the framework's effectiveness in three experiments. First, we enforce an ordering on latent channels without sacrificing reconstruction quality. Second, we align latents with semantic embeddings, analyzing the impact on downstream diffusion modeling. Third, we introduce equivariance, ensuring that a filtering operation on the input waveform directly corresponds to a specific transformation in the latent space. Ultimately, our Re-Bottleneck framework offers a flexible and efficient way to tailor representations of neural audio models, enabling them to seamlessly meet the varied demands of different applications with minimal additional training.
User-guided Generative Source Separation
Jul 02, 2025

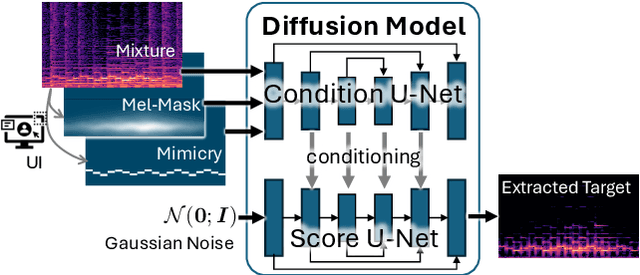
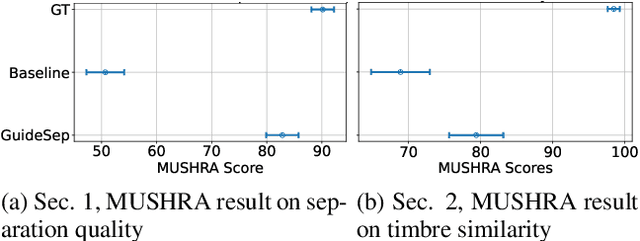
Music source separation (MSS) aims to extract individual instrument sources from their mixture. While most existing methods focus on the widely adopted four-stem separation setup (vocals, bass, drums, and other instruments), this approach lacks the flexibility needed for real-world applications. To address this, we propose GuideSep, a diffusion-based MSS model capable of instrument-agnostic separation beyond the four-stem setup. GuideSep is conditioned on multiple inputs: a waveform mimicry condition, which can be easily provided by humming or playing the target melody, and mel-spectrogram domain masks, which offer additional guidance for separation. Unlike prior approaches that relied on fixed class labels or sound queries, our conditioning scheme, coupled with the generative approach, provides greater flexibility and applicability. Additionally, we design a mask-prediction baseline using the same model architecture to systematically compare predictive and generative approaches. Our objective and subjective evaluations demonstrate that GuideSep achieves high-quality separation while enabling more versatile instrument extraction, highlighting the potential of user participation in the diffusion-based generative process for MSS. Our code and demo page are available at https://yutongwen.github.io/GuideSep/
Measuring similarity between embedding spaces using induced neighborhood graphs
Nov 13, 2024



Deep Learning techniques have excelled at generating embedding spaces that capture semantic similarities between items. Often these representations are paired, enabling experiments with analogies (pairs within the same domain) and cross-modality (pairs across domains). These experiments are based on specific assumptions about the geometry of embedding spaces, which allow finding paired items by extrapolating the positional relationships between embedding pairs in the training dataset, allowing for tasks such as finding new analogies, and multimodal zero-shot classification. In this work, we propose a metric to evaluate the similarity between paired item representations. Our proposal is built from the structural similarity between the nearest-neighbors induced graphs of each representation, and can be configured to compare spaces based on different distance metrics and on different neighborhood sizes. We demonstrate that our proposal can be used to identify similar structures at different scales, which is hard to achieve with kernel methods such as Centered Kernel Alignment (CKA). We further illustrate our method with two case studies: an analogy task using GloVe embeddings, and zero-shot classification in the CIFAR-100 dataset using CLIP embeddings. Our results show that accuracy in both analogy and zero-shot classification tasks correlates with the embedding similarity. These findings can help explain performance differences in these tasks, and may lead to improved design of paired-embedding models in the future.
On Class Separability Pitfalls In Audio-Text Contrastive Zero-Shot Learning
Aug 23, 2024
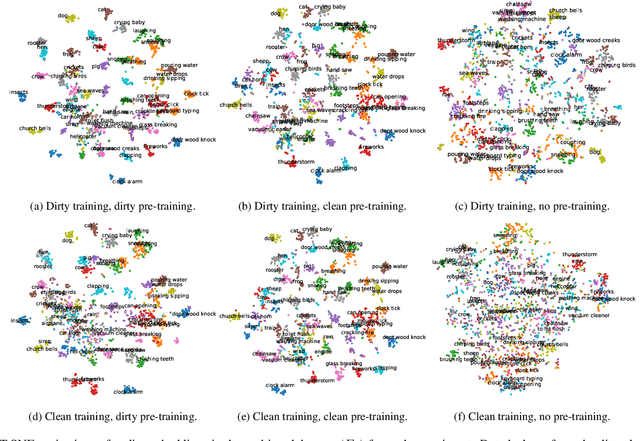


Recent advances in audio-text cross-modal contrastive learning have shown its potential towards zero-shot learning. One possibility for this is by projecting item embeddings from pre-trained backbone neural networks into a cross-modal space in which item similarity can be calculated in either domain. This process relies on a strong unimodal pre-training of the backbone networks, and on a data-intensive training task for the projectors. These two processes can be biased by unintentional data leakage, which can arise from using supervised learning in pre-training or from inadvertently training the cross-modal projection using labels from the zero-shot learning evaluation. In this study, we show that a significant part of the measured zero-shot learning accuracy is due to strengths inherited from the audio and text backbones, that is, they are not learned in the cross-modal domain and are not transferred from one modality to another.
Rethinking Non-Negative Matrix Factorization with Implicit Neural Representations
Apr 05, 2024



Non-negative Matrix Factorization (NMF) is a powerful technique for analyzing regularly-sampled data, i.e., data that can be stored in a matrix. For audio, this has led to numerous applications using time-frequency (TF) representations like the Short-Time Fourier Transform. However extending these applications to irregularly-spaced TF representations, like the Constant-Q transform, wavelets, or sinusoidal analysis models, has not been possible since these representations cannot be directly stored in matrix form. In this paper, we formulate NMF in terms of continuous functions (instead of fixed vectors) and show that NMF can be extended to a wider variety of signal classes that need not be regularly sampled.
Scaling Up Adaptive Filter Optimizers
Mar 01, 2024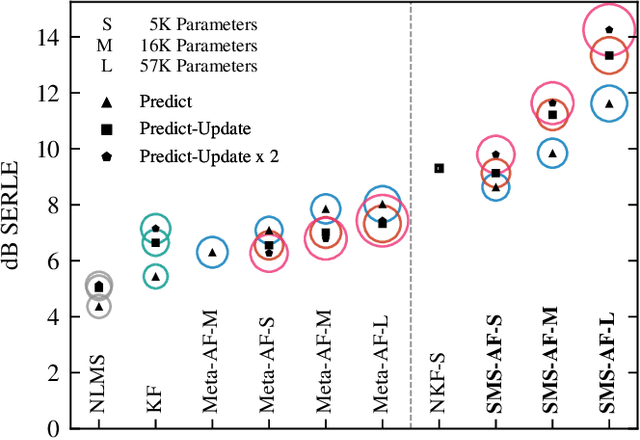
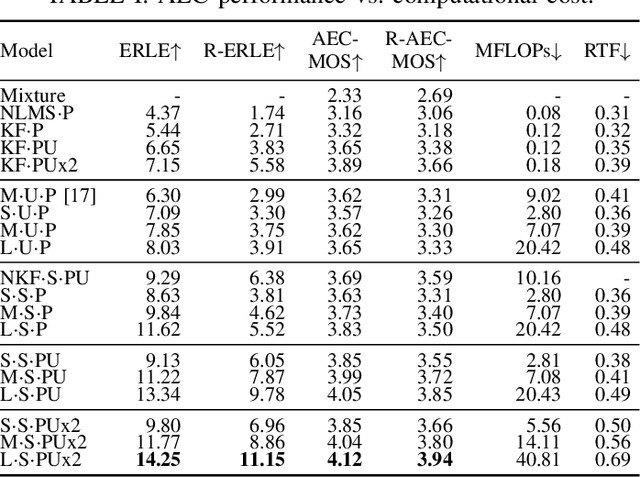
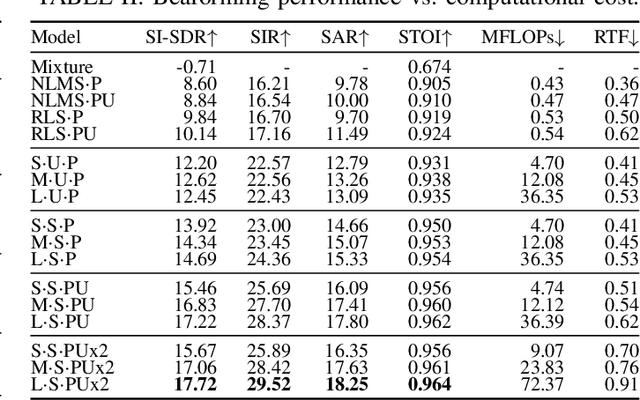
We introduce a new online adaptive filtering method called supervised multi-step adaptive filters (SMS-AF). Our method uses neural networks to control or optimize linear multi-delay or multi-channel frequency-domain filters and can flexibly scale-up performance at the cost of increased compute -- a property rarely addressed in the AF literature, but critical for many applications. To do so, we extend recent work with a set of improvements including feature pruning, a supervised loss, and multiple optimization steps per time-frame. These improvements work in a cohesive manner to unlock scaling. Furthermore, we show how our method relates to Kalman filtering and meta-adaptive filtering, making it seamlessly applicable to a diverse set of AF tasks. We evaluate our method on acoustic echo cancellation (AEC) and multi-channel speech enhancement tasks and compare against several baselines on standard synthetic and real-world datasets. Results show our method performance scales with inference cost and model capacity, yields multi-dB performance gains for both tasks, and is real-time capable on a single CPU core.
Sound Source Separation Using Latent Variational Block-Wise Disentanglement
Feb 08, 2024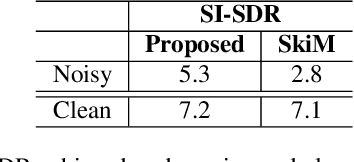
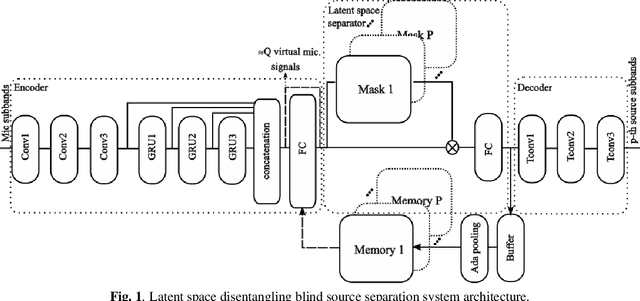
While neural network approaches have made significant strides in resolving classical signal processing problems, it is often the case that hybrid approaches that draw insight from both signal processing and neural networks produce more complete solutions. In this paper, we present a hybrid classical digital signal processing/deep neural network (DSP/DNN) approach to source separation (SS) highlighting the theoretical link between variational autoencoder and classical approaches to SS. We propose a system that transforms the single channel under-determined SS task to an equivalent multichannel over-determined SS problem in a properly designed latent space. The separation task in the latent space is treated as finding a variational block-wise disentangled representation of the mixture. We show empirically, that the design choices and the variational formulation of the task at hand motivated by the classical signal processing theoretical results lead to robustness to unseen out-of-distribution data and reduction of the overfitting risk. To address the resulting permutation issue we explicitly incorporate a novel differentiable permutation loss function and augment the model with a memory mechanism to keep track of the statistics of the individual sources.
Meta-AF Echo Cancellation for Improved Keyword Spotting
Dec 17, 2023Adaptive filters (AFs) are vital for enhancing the performance of downstream tasks, such as speech recognition, sound event detection, and keyword spotting. However, traditional AF design prioritizes isolated signal-level objectives, often overlooking downstream task performance. This can lead to suboptimal performance. Recent research has leveraged meta-learning to automatically learn AF update rules from data, alleviating the need for manual tuning when using simple signal-level objectives. This paper improves the Meta-AF framework by expanding it to support end-to-end training for arbitrary downstream tasks. We focus on classification tasks, where we introduce a novel training methodology that harnesses self-supervision and classifier feedback. We evaluate our approach on the combined task of acoustic echo cancellation and keyword spotting. Our findings demonstrate consistent performance improvements with both pre-trained and joint-trained keyword spotting models across synthetic and real playback. Notably, these improvements come without requiring additional tuning, increased inference-time complexity, or reliance on oracle signal-level training data.