 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring similarity between embedding spaces using induced neighborhood graphs
Nov 13, 2024



Deep Learning techniques have excelled at generating embedding spaces that capture semantic similarities between items. Often these representations are paired, enabling experiments with analogies (pairs within the same domain) and cross-modality (pairs across domains). These experiments are based on specific assumptions about the geometry of embedding spaces, which allow finding paired items by extrapolating the positional relationships between embedding pairs in the training dataset, allowing for tasks such as finding new analogies, and multimodal zero-shot classification. In this work, we propose a metric to evaluate the similarity between paired item representations. Our proposal is built from the structural similarity between the nearest-neighbors induced graphs of each representation, and can be configured to compare spaces based on different distance metrics and on different neighborhood sizes. We demonstrate that our proposal can be used to identify similar structures at different scales, which is hard to achieve with kernel methods such as Centered Kernel Alignment (CKA). We further illustrate our method with two case studies: an analogy task using GloVe embeddings, and zero-shot classification in the CIFAR-100 dataset using CLIP embeddings. Our results show that accuracy in both analogy and zero-shot classification tasks correlates with the embedding similarity. These findings can help explain performance differences in these tasks, and may lead to improved design of paired-embedding models in the future.
On Class Separability Pitfalls In Audio-Text Contrastive Zero-Shot Learning
Aug 23, 2024
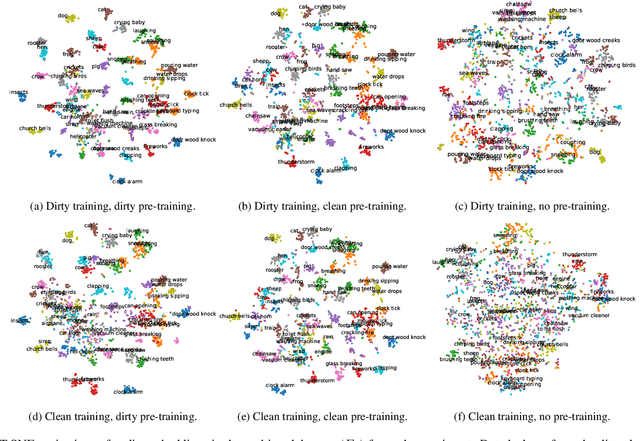


Recent advances in audio-text cross-modal contrastive learning have shown its potential towards zero-shot learning. One possibility for this is by projecting item embeddings from pre-trained backbone neural networks into a cross-modal space in which item similarity can be calculated in either domain. This process relies on a strong unimodal pre-training of the backbone networks, and on a data-intensive training task for the projectors. These two processes can be biased by unintentional data leakage, which can arise from using supervised learning in pre-training or from inadvertently training the cross-modal projection using labels from the zero-shot learning evaluation. In this study, we show that a significant part of the measured zero-shot learning accuracy is due to strengths inherited from the audio and text backbones, that is, they are not learned in the cross-modal domain and are not transferred from one modality to another.
Unsupervised Improvement of Audio-Text Cross-Modal Representations
May 05, 2023Recent advances in using language models to obtain cross-modal audio-text representations have overcome the limitations of conventional training approaches that use predefined labels. This has allowed the community to make progress in tasks like zero-shot classification, which would otherwise not be possible. However, learning such representations requires a large amount of human-annotated audio-text pairs. In this paper, we study unsupervised approaches to improve the learning framework of such representations with unpaired text and audio. We explore domain-unspecific and domain-specific curation methods to create audio-text pairs that we use to further improve the model. We also show that when domain-specific curation is used in conjunction with a soft-labeled contrastive loss, we are able to obtain significant improvement in terms of zero-shot classification performance on downstream sound event classification or acoustic scene classification tasks.