 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring similarity between embedding spaces using induced neighborhood graphs
Nov 13, 2024



Deep Learning techniques have excelled at generating embedding spaces that capture semantic similarities between items. Often these representations are paired, enabling experiments with analogies (pairs within the same domain) and cross-modality (pairs across domains). These experiments are based on specific assumptions about the geometry of embedding spaces, which allow finding paired items by extrapolating the positional relationships between embedding pairs in the training dataset, allowing for tasks such as finding new analogies, and multimodal zero-shot classification. In this work, we propose a metric to evaluate the similarity between paired item representations. Our proposal is built from the structural similarity between the nearest-neighbors induced graphs of each representation, and can be configured to compare spaces based on different distance metrics and on different neighborhood sizes. We demonstrate that our proposal can be used to identify similar structures at different scales, which is hard to achieve with kernel methods such as Centered Kernel Alignment (CKA). We further illustrate our method with two case studies: an analogy task using GloVe embeddings, and zero-shot classification in the CIFAR-100 dataset using CLIP embeddings. Our results show that accuracy in both analogy and zero-shot classification tasks correlates with the embedding similarity. These findings can help explain performance differences in these tasks, and may lead to improved design of paired-embedding models in the future.
Texture Selection for Automatic Music Genre Classification
May 28, 2019


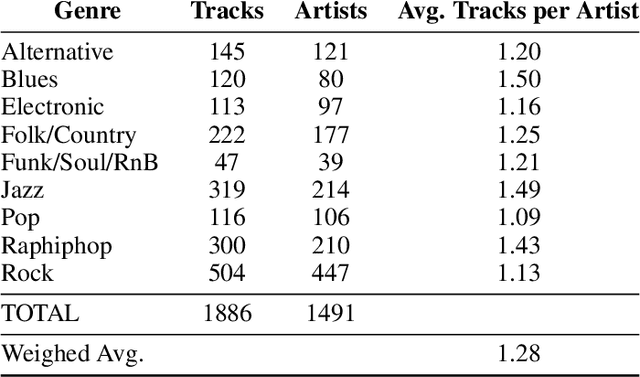
Music Genre Classification is the problem of associating genre-related labels to digitized music tracks. It has applications in the organization of commercial and personal music collections. Often, music tracks are described as a set of timbre-inspired sound textures. In shallow-learning systems, the total number of sound textures per track is usually too high, and texture downsampling is necessary to make training tractable. Although previous work has solved this by linear downsampling, no extensive work has been done to evaluate how texture selection benefits genre classification in the context of the bag of frames track descriptions. In this paper, we evaluate the impact of frame selection on automatic music genre classification in a bag of frames scenario. We also present a novel texture selector based on K-Means aimed to identify diverse sound textures within each track. We evaluated texture selection in diverse datasets, four different feature sets, as well as its relationship to a univariate feature selection strategy. The results show that frame selection leads to significant improvement over the single vector baseline on datasets consisting of full-length tracks, regardless of the feature set. Results also indicate that the K-Means texture selector achieves significant improvements over the baseline, using fewer textures per track than the commonly used linear downsampling. The results also suggest that texture selection is complementary to the feature selection strategy evaluated. Our qualitative analysis indicates that texture variety within classes benefits model generalization. Our analysis shows that selecting specific audio excerpts can improve classification performance, and it can be done automatically.