 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative-First Neural Audio Autoencoder
Feb 17, 2026Neural autoencoders underpin generative models. Practical, large-scale use of neural autoencoders for generative modeling necessitates fast encoding, low latent rates, and a single model across representations. Existing approaches are reconstruction-first: they incur high latent rates, slow encoding, and separate architectures for discrete vs. continuous latents and for different audio channel formats, hindering workflows from preprocessing to inference conditioning. We introduce a generative-first architecture for audio autoencoding that increases temporal downsampling from 2048x to 3360x and supports continuous and discrete representations and common audio channel formats in one model. By balancing compression, quality, and speed, it delivers 10x faster encoding, 1.6x lower rates, and eliminates channel-format-specific variants while maintaining competitive reconstruction quality. This enables applications previously constrained by processing costs: a 60-second mono signal compresses to 788 tokens, making generative modeling more tractable.
Rethinking Music Captioning with Music Metadata LLMs
Feb 03, 2026Music captioning, or the task of generating a natural language description of music, is useful for both music understanding and controllable music generation. Training captioning models, however, typically requires high-quality music caption data which is scarce compared to metadata (e.g., genre, mood, etc.). As a result, it is common to use large language models (LLMs) to synthesize captions from metadata to generate training data for captioning models, though this process imposes a fixed stylization and entangles factual information with natural language style. As a more direct approach, we propose metadata-based captioning. We train a metadata prediction model to infer detailed music metadata from audio and then convert it into expressive captions via pre-trained LLMs at inference time. Compared to a strong end-to-end baseline trained on LLM-generated captions derived from metadata, our method: (1) achieves comparable performance in less training time over end-to-end captioners, (2) offers flexibility to easily change stylization post-training, enabling output captions to be tailored to specific stylistic and quality requirements, and (3) can be prompted with audio and partial metadata to enable powerful metadata imputation or in-filling--a common task for organizing music data.
Primitive-Planner: An Ultra Lightweight Quadrotor Planner with Time-optimal Primitives
Feb 24, 2025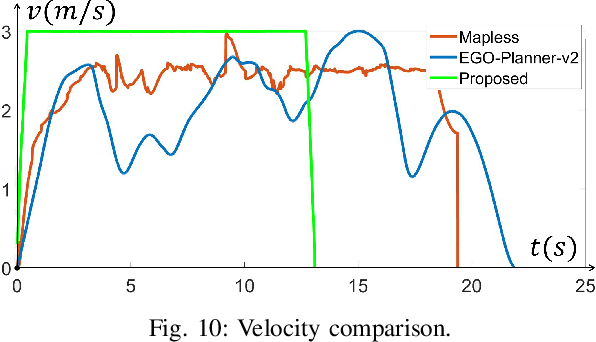
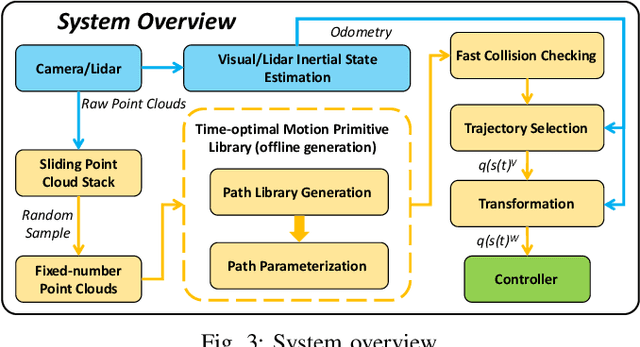
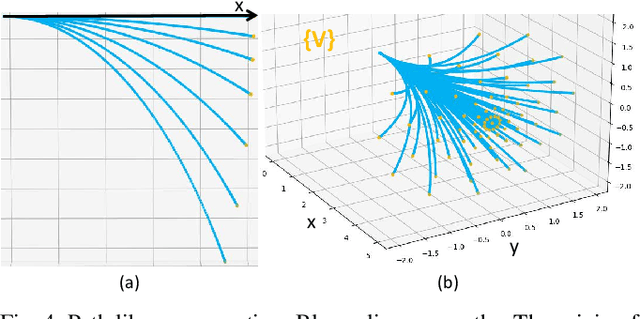
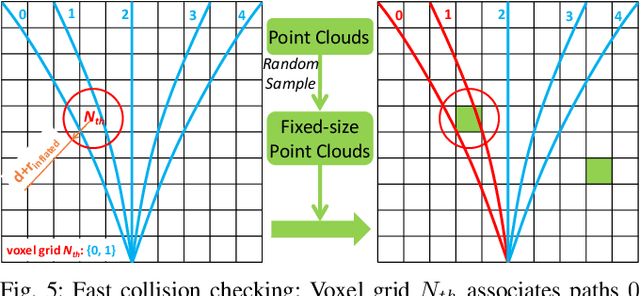
It is a significant requirement for a quadrotor trajectory planner to simultaneously guarantee trajectory quality and system lightweight. Many researchers focus on this problem, but there's still a gap between their performance and our common wish. In this paper, we propose an ultra lightweight quadrotor planner with time-optimal primitives. Firstly, a novel motion primitive library is proposed to generate time-optimal and dynamical feasible trajectories offline. Secondly, we propose a fast collision checking method with a deterministic time consumption, independent of the sampling resolution of the primitives. Finally, we select the minimum cost trajectory to execute among the safe primitives based on user-defined requirements. The propsed transformation relation between the local trajectories ensures the smoothness of the global trajectory. The planner reduces unnecessary online computing power consumption as much as possible, while ensuring a high-quality trajectory. Benchmark comparisons show that our method can generate the shortest flight time and distance of trajectory with the lowest computation overload. Challenging real-world experiments validate the robustness of our method.
On Class Separability Pitfalls In Audio-Text Contrastive Zero-Shot Learning
Aug 23, 2024
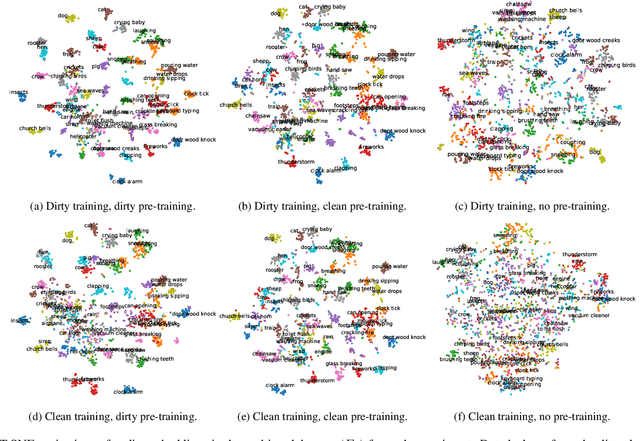


Recent advances in audio-text cross-modal contrastive learning have shown its potential towards zero-shot learning. One possibility for this is by projecting item embeddings from pre-trained backbone neural networks into a cross-modal space in which item similarity can be calculated in either domain. This process relies on a strong unimodal pre-training of the backbone networks, and on a data-intensive training task for the projectors. These two processes can be biased by unintentional data leakage, which can arise from using supervised learning in pre-training or from inadvertently training the cross-modal projection using labels from the zero-shot learning evaluation. In this study, we show that a significant part of the measured zero-shot learning accuracy is due to strengths inherited from the audio and text backbones, that is, they are not learned in the cross-modal domain and are not transferred from one modality to another.
Fast Iterative Region Inflation for Computing Large 2-D/3-D Convex Regions of Obstacle-Free Space
Mar 05, 20241) Restrictive Inflation is designed to ensure the managibility of the generated convex polytope. Based on its characteristic of few variables but rich constraints, an efficient and numerically stable solver is designed. 2) A novel method that formulates the MVIE problem into SOCP formulation is proposed, which avoids directly confronting the positive definite constraints and improves the computational efficiency. 3) Especially for 2-D MVIE, a linear-time exact algorithm is introduced for the first time, filling a gap that existed for several decades and further enabling ultra-fast computational performance. 4) Building upon the above methods, a reliable convex polytope generation algorithm FIRI is proposed. Extensive experiments verify its superior comprehensive performance in terms of quality, efficiency, and managibility. High-performance implementation of FIRI will be open-sourced for the reference of the community.
Audio Editing with Non-Rigid Text Prompts
Oct 19, 2023In this paper, we explore audio-editing with non-rigid text edits. We show that the proposed editing pipeline is able to create audio edits that remain faithful to the input audio. We explore text prompts that perform addition, style transfer, and in-painting. We quantitatively and qualitatively show that the edits are able to obtain results which outperform Audio-LDM, a recently released text-prompted audio generation model. Qualitative inspection of the results points out that the edits given by our approach remain more faithful to the input audio in terms of keeping the original onsets and offsets of the audio events.
Unsupervised Improvement of Audio-Text Cross-Modal Representations
May 05, 2023Recent advances in using language models to obtain cross-modal audio-text representations have overcome the limitations of conventional training approaches that use predefined labels. This has allowed the community to make progress in tasks like zero-shot classification, which would otherwise not be possible. However, learning such representations requires a large amount of human-annotated audio-text pairs. In this paper, we study unsupervised approaches to improve the learning framework of such representations with unpaired text and audio. We explore domain-unspecific and domain-specific curation methods to create audio-text pairs that we use to further improve the model. We also show that when domain-specific curation is used in conjunction with a soft-labeled contrastive loss, we are able to obtain significant improvement in terms of zero-shot classification performance on downstream sound event classification or acoustic scene classification tasks.
A Framework for Unified Real-time Personalized and Non-Personalized Speech Enhancement
Feb 23, 2023



In this study, we present an approach to train a single speech enhancement network that can perform both personalized and non-personalized speech enhancement. This is achieved by incorporating a frame-wise conditioning input that specifies the type of enhancement output. To improve the quality of the enhanced output and mitigate oversuppression, we experiment with re-weighting frames by the presence or absence of speech activity and applying augmentations to speaker embeddings. By training under a multi-task learning setting, we empirically show that the proposed unified model obtains promising results on both personalized and non-personalized speech enhancement benchmarks and reaches similar performance to models that are trained specialized for either task. The strong performance of the proposed method demonstrates that the unified model is a more economical alternative compared to keeping separate task-specific models during inference.
A Linear and Exact Algorithm for Whole-Body Collision Evaluation via Scale Optimization
Aug 12, 2022
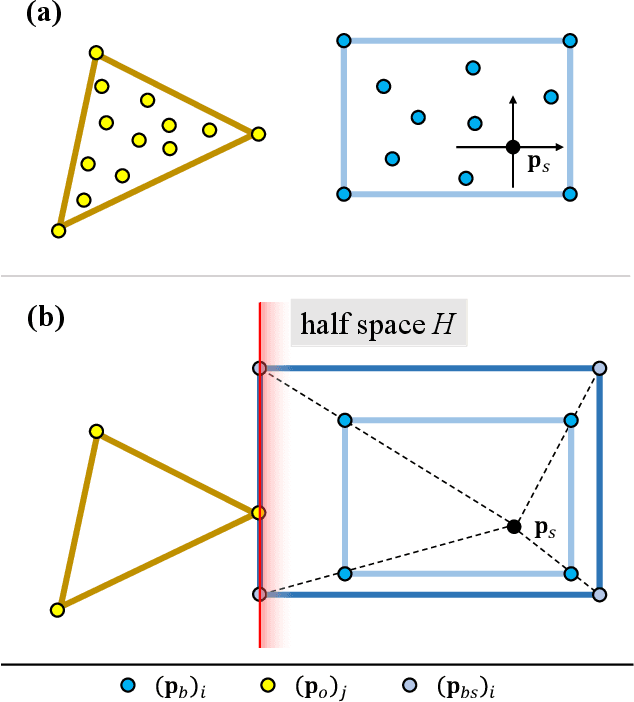
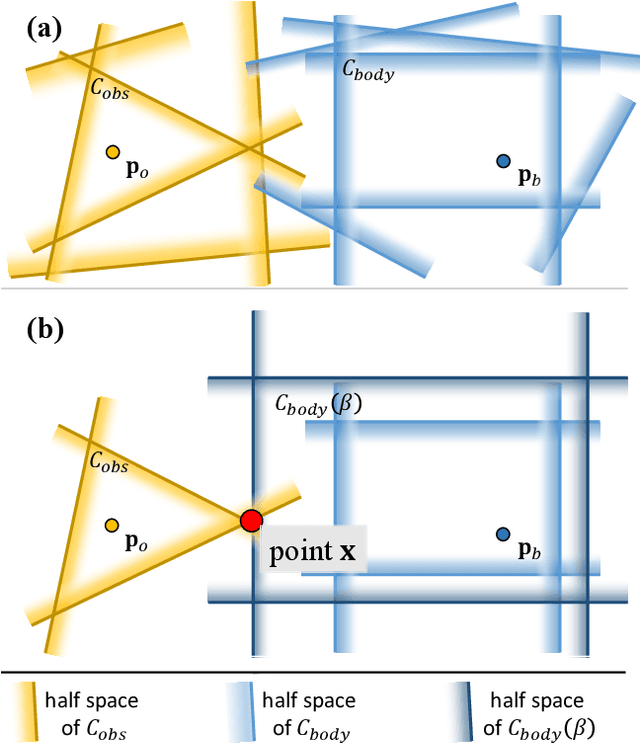

Collision evaluation is of vital importance in various applications. However, existing methods are either cumbersome to calculate or have a gap with the actual value. In this paper, we propose a zero-gap whole-body collision evaluation which can be formulated as a low dimensional linear program. This evaluation can be solved analytically in O(m) computational time, where m is the total number of the linear inequalities in this linear program. Moreover, the proposed method is efficient in obtaining its gradient, making it easy to apply to optimization-based applications.
Semi-supervised Time Domain Target Speaker Extraction with Attention
Jun 18, 2022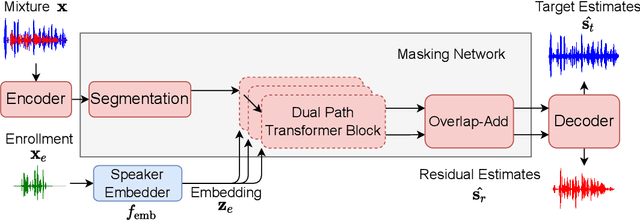

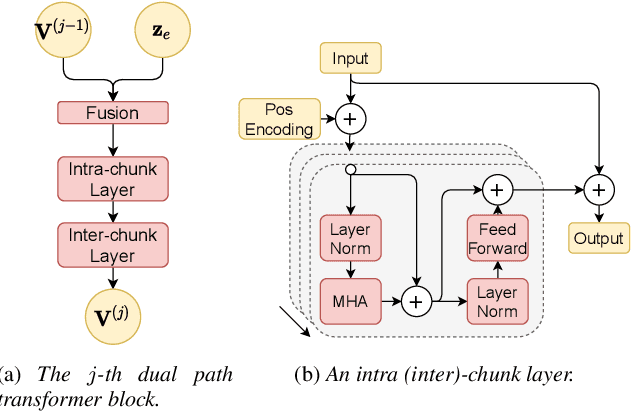
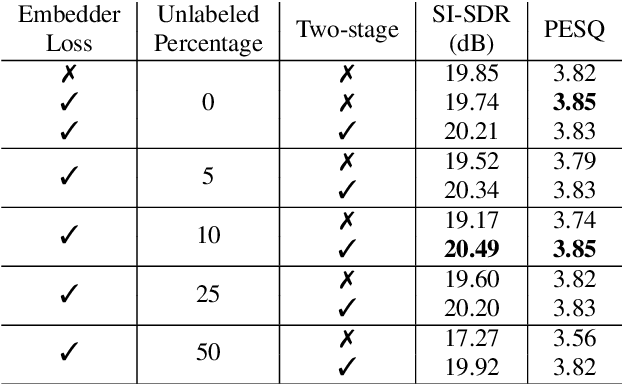
In this work, we propose Exformer, a time-domain architecture for target speaker extraction. It consists of a pre-trained speaker embedder network and a separator network based on transformer encoder blocks. We study multiple methods to combine speaker information with the input mixture, and the resulting Exformer architecture obtains superior extraction performance compared to prior time-domain networks. Furthermore, we investigate a two-stage procedure to train the model using mixtures without reference signals upon a pre-trained supervised model. Experimental results show that the proposed semi-supervised learning procedure improves the performance of the supervised baselines.