 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
HIPPO: Accelerating Video Large Language Models Inference via Holistic-aware Parallel Speculative Decoding
Jan 13, 2026Speculative decoding (SD) has emerged as a promising approach to accelerate LLM inference without sacrificing output quality. Existing SD methods tailored for video-LLMs primarily focus on pruning redundant visual tokens to mitigate the computational burden of massive visual inputs. However, existing methods do not achieve inference acceleration comparable to text-only LLMs. We observe from extensive experiments that this phenomenon mainly stems from two limitations: (i) their pruning strategies inadequately preserve visual semantic tokens, degrading draft quality and acceptance rates; (ii) even with aggressive pruning (e.g., 90% visual tokens removed), the draft model's remaining inference cost limits overall speedup. To address these limitations, we propose HIPPO, a general holistic-aware parallel speculative decoding framework. Specifically, HIPPO proposes (i) a semantic-aware token preservation method, which fuses global attention scores with local visual semantics to retain semantic information at high pruning ratios; (ii) a video parallel SD algorithm that decouples and overlaps draft generation and target verification phases. Experiments on four video-LLMs across six benchmarks demonstrate HIPPO's effectiveness, yielding up to 3.51x speedup compared to vanilla auto-regressive decoding.
TALON: Confidence-Aware Speculative Decoding with Adaptive Token Trees
Jan 12, 2026Speculative decoding (SD) has become a standard technique for accelerating LLM inference without sacrificing output quality. Recent advances in speculative decoding have shifted from sequential chain-based drafting to tree-structured generation, where the draft model constructs a tree of candidate tokens to explore multiple possible drafts in parallel. However, existing tree-based SD methods typically build a fixed-width, fixed-depth draft tree, which fails to adapt to the varying difficulty of tokens and contexts. As a result, the draft model cannot dynamically adjust the tree structure to early stop on difficult tokens and extend generation for simple ones. To address these challenges, we introduce TALON, a training-free, budget-driven adaptive tree expansion framework that can be plugged into existing tree-based methods. Unlike static methods, TALON constructs the draft tree iteratively until a fixed token budget is met, using a hybrid expansion strategy that adaptively allocates the node budget to each layer of the draft tree. This framework naturally shapes the draft tree into a "deep-and-narrow" form for deterministic contexts and a "shallow-and-wide" form for uncertain branches, effectively optimizing the trade-off between exploration width and generation depth under a given budget. Extensive experiments across 5 models and 6 datasets demonstrate that TALON consistently outperforms state-of-the-art EAGLE-3, achieving up to 5.16x end-to-end speedup over auto-regressive decoding.
KALE: Enhancing Knowledge Manipulation in Large Language Models via Knowledge-aware Learning
Jan 12, 2026Despite the impressive performance of large language models (LLMs) pretrained on vast knowledge corpora, advancing their knowledge manipulation-the ability to effectively recall, reason, and transfer relevant knowledge-remains challenging. Existing methods mainly leverage Supervised Fine-Tuning (SFT) on labeled datasets to enhance LLMs' knowledge manipulation ability. However, we observe that SFT models still exhibit the known&incorrect phenomenon, where they explicitly possess relevant knowledge for a given question but fail to leverage it for correct answers. To address this challenge, we propose KALE (Knowledge-Aware LEarning)-a post-training framework that leverages knowledge graphs (KGs) to generate high-quality rationales and enhance LLMs' knowledge manipulation ability. Specifically, KALE first introduces a Knowledge-Induced (KI) data synthesis method that efficiently extracts multi-hop reasoning paths from KGs to generate high-quality rationales for question-answer pairs. Then, KALE employs a Knowledge-Aware (KA) fine-tuning paradigm that enhances knowledge manipulation by internalizing rationale-guided reasoning through minimizing the KL divergence between predictions with and without rationales. Extensive experiments on eight popular benchmarks across six different LLMs demonstrate the effectiveness of KALE, achieving accuracy improvements of up to 11.72% and an average of 4.18%.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
Fusion of Multiscale Features Via Centralized Sparse-attention Network for EEG Decoding
Dec 23, 2025Electroencephalography (EEG) signal decoding is a key technology that translates brain activity into executable commands, laying the foundation for direct brain-machine interfacing and intelligent interaction. To address the inherent spatiotemporal heterogeneity of EEG signals, this paper proposes a multi-branch parallel architecture, where each temporal scale is equipped with an independent spatial feature extraction module. To further enhance multi-branch feature fusion, we propose a Fusion of Multiscale Features via Centralized Sparse-attention Network (EEG-CSANet), a centralized sparse-attention network. It employs a main-auxiliary branch architecture, where the main branch models core spatiotemporal patterns via multiscale self-attention, and the auxiliary branch facilitates efficient local interactions through sparse cross-attention. Experimental results show that EEG-CSANet achieves state-of-the-art (SOTA) performance across five public datasets (BCIC-IV-2A, BCIC-IV-2B, HGD, SEED, and SEED-VIG), with accuracies of 88.54%, 91.09%, 99.43%, 96.03%, and 90.56%, respectively. Such performance demonstrates its strong adaptability and robustness across various EEG decoding tasks. Moreover, extensive ablation studies are conducted to enhance the interpretability of EEG-CSANet. In the future, we hope that EEG-CSANet could serve as a promising baseline model in the field of EEG signal decoding. The source code is publicly available at: https://github.com/Xiangrui-Cai/EEG-CSANet
A Survey of Vibe Coding with Large Language Models
Oct 14, 2025The advancement of large language models (LLMs) has catalyzed a paradigm shift from code generation assistance to autonomous coding agents, enabling a novel development methodology termed "Vibe Coding" where developers validate AI-generated implementations through outcome observation rather than line-by-line code comprehension. Despite its transformative potential, the effectiveness of this emergent paradigm remains under-explored, with empirical evidence revealing unexpected productivity losses and fundamental challenges in human-AI collaboration. To address this gap, this survey provides the first comprehensive and systematic review of Vibe Coding with large language models, establishing both theoretical foundations and practical frameworks for this transformative development approach. Drawing from systematic analysis of over 1000 research papers, we survey the entire vibe coding ecosystem, examining critical infrastructure components including LLMs for coding, LLM-based coding agent, development environment of coding agent, and feedback mechanisms. We first introduce Vibe Coding as a formal discipline by formalizing it through a Constrained Markov Decision Process that captures the dynamic triadic relationship among human developers, software projects, and coding agents. Building upon this theoretical foundation, we then synthesize existing practices into five distinct development models: Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, and Context-Enhanced Models, thus providing the first comprehensive taxonomy in this domain. Critically, our analysis reveals that successful Vibe Coding depends not merely on agent capabilities but on systematic context engineering, well-established development environments, and human-agent collaborative development models.
Mitigating Overthinking through Reasoning Shaping
Oct 10, 2025Large reasoning models (LRMs) boosted by Reinforcement Learning from Verifier Reward (RLVR) have shown great power in problem solving, yet they often cause overthinking: excessive, meandering reasoning that inflates computational cost. Prior designs of penalization in RLVR manage to reduce token consumption while often harming model performance, which arises from the oversimplicity of token-level supervision. In this paper, we argue that the granularity of supervision plays a crucial role in balancing efficiency and accuracy, and propose Group Relative Segment Penalization (GRSP), a step-level method to regularize reasoning. Since preliminary analyses show that reasoning segments are strongly correlated with token consumption and model performance, we design a length-aware weighting mechanism across segment clusters. Extensive experiments demonstrate that GRSP achieves superior token efficiency without heavily compromising accuracy, especially the advantages with harder problems. Moreover, GRSP stabilizes RL training and scales effectively across model sizes.
ECHO: Toward Contextual Seq2Seq Paradigms in Large EEG Models
Sep 26, 2025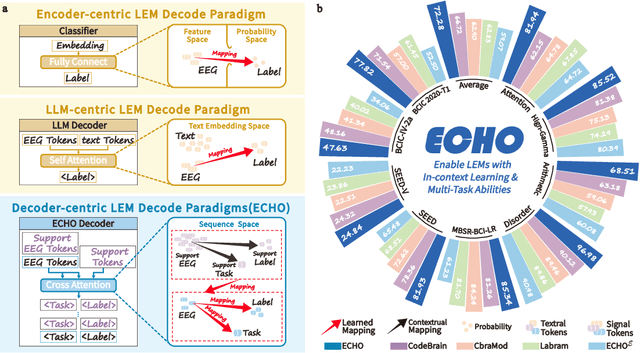
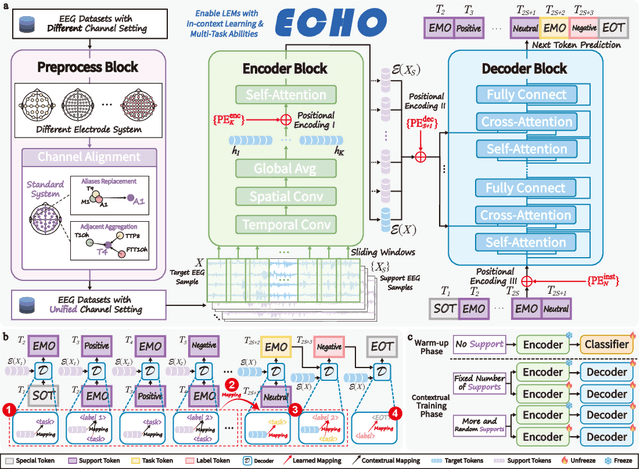
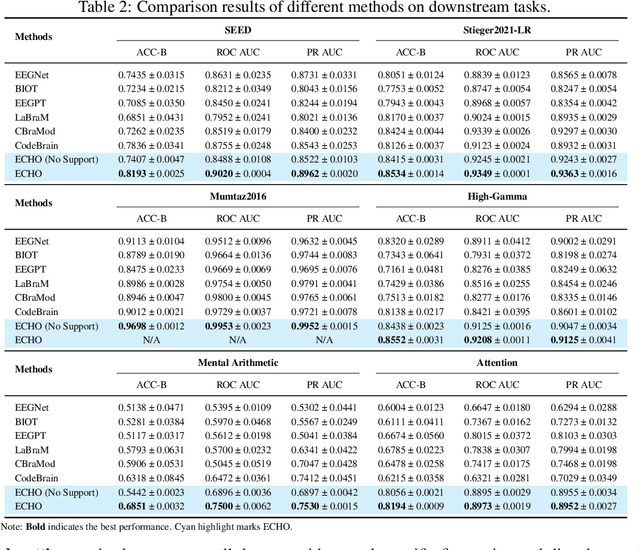
Electroencephalography (EEG), with its broad range of applications, necessitates models that can generalize effectively across various tasks and datasets. Large EEG Models (LEMs) address this by pretraining encoder-centric architectures on large-scale unlabeled data to extract universal representations. While effective, these models lack decoders of comparable capacity, limiting the full utilization of the learned features. To address this issue, we introduce ECHO, a novel decoder-centric LEM paradigm that reformulates EEG modeling as sequence-to-sequence learning. ECHO captures layered relationships among signals, labels, and tasks within sequence space, while incorporating discrete support samples to construct contextual cues. This design equips ECHO with in-context learning, enabling dynamic adaptation to heterogeneous tasks without parameter updates. Extensive experiments across multiple datasets demonstrate that, even with basic model components, ECHO consistently outperforms state-of-the-art single-task LEMs in multi-task settings, showing superior generalization and adaptability.
P-Aligner: Enabling Pre-Alignment of Language Models via Principled Instruction Synthesis
Aug 06, 2025
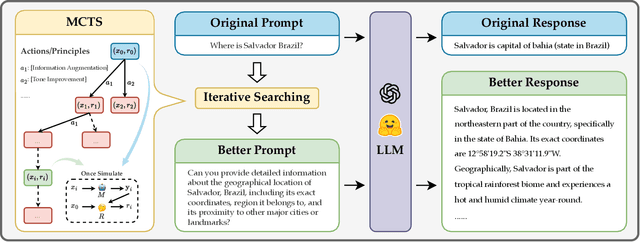
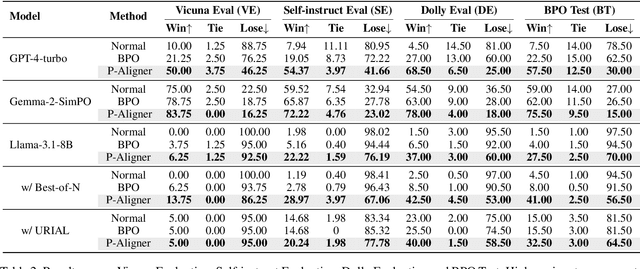
Large Language Models (LLMs) are expected to produce safe, helpful, and honest content during interaction with human users, but they frequently fail to align with such values when given flawed instructions, e.g., missing context, ambiguous directives, or inappropriate tone, leaving substantial room for improvement along multiple dimensions. A cost-effective yet high-impact way is to pre-align instructions before the model begins decoding. Existing approaches either rely on prohibitive test-time search costs or end-to-end model rewrite, which is powered by a customized training corpus with unclear objectives. In this work, we demonstrate that the goal of efficient and effective preference alignment can be achieved by P-Aligner, a lightweight module generating instructions that preserve the original intents while being expressed in a more human-preferred form. P-Aligner is trained on UltraPrompt, a new dataset synthesized via a proposed principle-guided pipeline using Monte-Carlo Tree Search, which systematically explores the space of candidate instructions that are closely tied to human preference. Experiments across different methods show that P-Aligner generally outperforms strong baselines across various models and benchmarks, including average win-rate gains of 28.35% and 8.69% on GPT-4-turbo and Gemma-2-SimPO, respectively. Further analyses validate its effectiveness and efficiency through multiple perspectives, including data quality, search strategies, iterative deployment, and time overhead.