 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutcome-Grounded Advantage Reshaping for Fine-Grained Credit Assignment in Mathematical Reasoning
Jan 12, 2026Group Relative Policy Optimization (GRPO) has emerged as a promising critic-free reinforcement learning paradigm for reasoning tasks. However, standard GRPO employs a coarse-grained credit assignment mechanism that propagates group-level rewards uniformly to to every token in a sequence, neglecting the varying contribution of individual reasoning steps. We address this limitation by introducing Outcome-grounded Advantage Reshaping (OAR), a fine-grained credit assignment mechanism that redistributes advantages based on how much each token influences the model's final answer. We instantiate OAR via two complementary strategies: (1) OAR-P, which estimates outcome sensitivity through counterfactual token perturbations, serving as a high-fidelity attribution signal; (2) OAR-G, which uses an input-gradient sensitivity proxy to approximate the influence signal with a single backward pass. These importance signals are integrated with a conservative Bi-Level advantage reshaping scheme that suppresses low-impact tokens and boosts pivotal ones while preserving the overall advantage mass. Empirical results on extensive mathematical reasoning benchmarks demonstrate that while OAR-P sets the performance upper bound, OAR-G achieves comparable gains with negligible computational overhead, both significantly outperforming a strong GRPO baseline, pushing the boundaries of critic-free LLM reasoning.
DRQA: Dynamic Reasoning Quota Allocation for Controlling Overthinking in Reasoning Large Language Models
Aug 25, 2025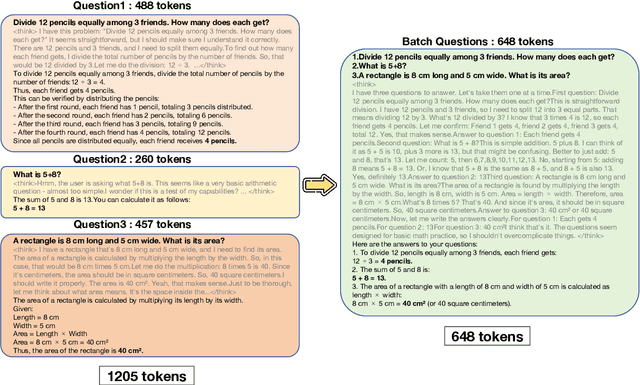

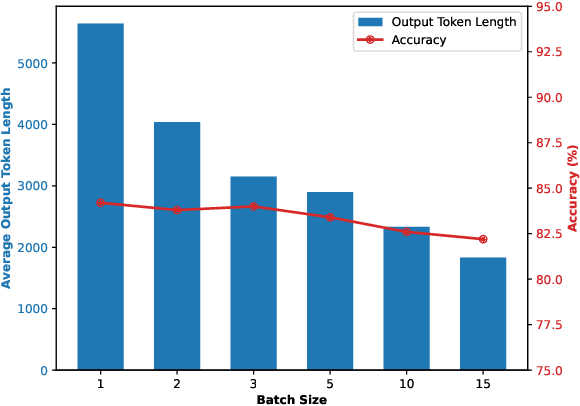

Reasoning large language models (RLLMs), such as OpenAI-O3 and DeepSeek-R1, have recently demonstrated remarkable capabilities by performing structured and multi-step reasoning. However, recent studies reveal that RLLMs often suffer from overthinking, i.e., producing unnecessarily lengthy reasoning chains even for simple questions, leading to excessive token consumption and computational inefficiency. Interestingly, we observe that when processing multiple questions in batch mode, RLLMs exhibit more resource-efficient behavior by dynamically compressing reasoning steps for easier problems, due to implicit resource competition. Inspired by this, we propose Dynamic Reasoning Quota Allocation (DRQA), a novel method that transfers the benefits of resource competition from batch processing to single-question inference. Specifically, DRQA leverages batch-generated preference data and reinforcement learning to train the model to allocate reasoning resources adaptively. By encouraging the model to internalize a preference for responses that are both accurate and concise, DRQA enables it to generate concise answers for simple questions while retaining sufficient reasoning depth for more challenging ones. Extensive experiments on a wide range of mathematical and scientific reasoning benchmarks demonstrate that DRQA significantly reduces token usage while maintaining, and in many cases improving, answer accuracy. By effectively mitigating the overthinking problem, DRQA offers a promising direction for more efficient and scalable deployment of RLLMs, and we hope it inspires further exploration into fine-grained control of reasoning behaviors.
DinoCompanion: An Attachment-Theory Informed Multimodal Robot for Emotionally Responsive Child-AI Interaction
Jun 14, 2025Children's emotional development fundamentally relies on secure attachment relationships, yet current AI companions lack the theoretical foundation to provide developmentally appropriate emotional support. We introduce DinoCompanion, the first attachment-theory-grounded multimodal robot for emotionally responsive child-AI interaction. We address three critical challenges in child-AI systems: the absence of developmentally-informed AI architectures, the need to balance engagement with safety, and the lack of standardized evaluation frameworks for attachment-based capabilities. Our contributions include: (i) a multimodal dataset of 128 caregiver-child dyads containing 125,382 annotated clips with paired preference-risk labels, (ii) CARPO (Child-Aware Risk-calibrated Preference Optimization), a novel training objective that maximizes engagement while applying epistemic-uncertainty-weighted risk penalties, and (iii) AttachSecure-Bench, a comprehensive evaluation benchmark covering ten attachment-centric competencies with strong expert consensus (\k{appa}=0.81). DinoCompanion achieves state-of-the-art performance (57.15%), outperforming GPT-4o (50.29%) and Claude-3.7-Sonnet (53.43%), with exceptional secure base behaviors (72.99%, approaching human expert levels of 78.4%) and superior attachment risk detection (69.73%). Ablations validate the critical importance of multimodal fusion, uncertainty-aware risk modeling, and hierarchical memory for coherent, emotionally attuned interactions.
Act-as-Pet: Benchmarking the Abilities of Large Language Models as E-Pets in Social Network Services
Jun 04, 2025As interest in using Large Language Models (LLMs) for interactive and emotionally rich experiences grows, virtual pet companionship emerges as a novel yet underexplored application. Existing approaches focus on basic pet role-playing interactions without systematically benchmarking LLMs for comprehensive companionship. In this paper, we introduce Pet-Bench, a dedicated benchmark that evaluates LLMs across both self-interaction and human-interaction dimensions. Unlike prior work, Pet-Bench emphasizes self-evolution and developmental behaviors alongside interactive engagement, offering a more realistic reflection of pet companionship. It features diverse tasks such as intelligent scheduling, memory-based dialogues, and psychological conversations, with over 7,500 interaction instances designed to simulate complex pet behaviors. Evaluation of 28 LLMs reveals significant performance variations linked to model size and inherent capabilities, underscoring the need for specialized optimization in this domain. Pet-Bench serves as a foundational resource for benchmarking pet-related LLM abilities and advancing emotionally immersive human-pet interactions.
SNS-Bench-VL: Benchmarking Multimodal Large Language Models in Social Networking Services
May 29, 2025With the increasing integration of visual and textual content in Social Networking Services (SNS), evaluating the multimodal capabilities of Large Language Models (LLMs) is crucial for enhancing user experience, content understanding, and platform intelligence. Existing benchmarks primarily focus on text-centric tasks, lacking coverage of the multimodal contexts prevalent in modern SNS ecosystems. In this paper, we introduce SNS-Bench-VL, a comprehensive multimodal benchmark designed to assess the performance of Vision-Language LLMs in real-world social media scenarios. SNS-Bench-VL incorporates images and text across 8 multimodal tasks, including note comprehension, user engagement analysis, information retrieval, and personalized recommendation. It comprises 4,001 carefully curated multimodal question-answer pairs, covering single-choice, multiple-choice, and open-ended tasks. We evaluate over 25 state-of-the-art multimodal LLMs, analyzing their performance across tasks. Our findings highlight persistent challenges in multimodal social context comprehension. We hope SNS-Bench-VL will inspire future research towards robust, context-aware, and human-aligned multimodal intelligence for next-generation social networking services.
U2-BENCH: Benchmarking Large Vision-Language Models on Ultrasound Understanding
May 23, 2025Ultrasound is a widely-used imaging modality critical to global healthcare, yet its interpretation remains challenging due to its varying image quality on operators, noises, and anatomical structures. Although large vision-language models (LVLMs) have demonstrated impressive multimodal capabilities across natural and medical domains, their performance on ultrasound remains largely unexplored. We introduce U2-BENCH, the first comprehensive benchmark to evaluate LVLMs on ultrasound understanding across classification, detection, regression, and text generation tasks. U2-BENCH aggregates 7,241 cases spanning 15 anatomical regions and defines 8 clinically inspired tasks, such as diagnosis, view recognition, lesion localization, clinical value estimation, and report generation, across 50 ultrasound application scenarios. We evaluate 20 state-of-the-art LVLMs, both open- and closed-source, general-purpose and medical-specific. Our results reveal strong performance on image-level classification, but persistent challenges in spatial reasoning and clinical language generation. U2-BENCH establishes a rigorous and unified testbed to assess and accelerate LVLM research in the uniquely multimodal domain of medical ultrasound imaging.
Revealing Weaknesses in Text Watermarking Through Self-Information Rewrite Attacks
May 08, 2025Text watermarking aims to subtly embed statistical signals into text by controlling the Large Language Model (LLM)'s sampling process, enabling watermark detectors to verify that the output was generated by the specified model. The robustness of these watermarking algorithms has become a key factor in evaluating their effectiveness. Current text watermarking algorithms embed watermarks in high-entropy tokens to ensure text quality. In this paper, we reveal that this seemingly benign design can be exploited by attackers, posing a significant risk to the robustness of the watermark. We introduce a generic efficient paraphrasing attack, the Self-Information Rewrite Attack (SIRA), which leverages the vulnerability by calculating the self-information of each token to identify potential pattern tokens and perform targeted attack. Our work exposes a widely prevalent vulnerability in current watermarking algorithms. The experimental results show SIRA achieves nearly 100% attack success rates on seven recent watermarking methods with only 0.88 USD per million tokens cost. Our approach does not require any access to the watermark algorithms or the watermarked LLM and can seamlessly transfer to any LLM as the attack model, even mobile-level models. Our findings highlight the urgent need for more robust watermarking.
Cluster-Driven Expert Pruning for Mixture-of-Experts Large Language Models
Apr 10, 2025Mixture-of-Experts (MoE) architectures have emerged as a promising paradigm for scaling large language models (LLMs) with sparse activation of task-specific experts. Despite their computational efficiency during inference, the massive overall parameter footprint of MoE models (e.g., GPT-4) introduces critical challenges for practical deployment. Current pruning approaches often fail to address two inherent characteristics of MoE systems: 1).intra-layer expert homogeneity where experts within the same MoE layer exhibit functional redundancy, and 2). inter-layer similarity patterns where deeper layers tend to contain progressively more homogeneous experts. To tackle these issues, we propose Cluster-driven Expert Pruning (C-Prune), a novel two-stage framework for adaptive task-specific compression of MoE LLMs. C-Prune operates through layer-wise expert clustering, which groups functionally similar experts within each MoE layer using parameter similarity metrics, followed by global cluster pruning, which eliminates redundant clusters across all layers through a unified importance scoring mechanism that accounts for cross-layer homogeneity. We validate C-Prune through extensive experiments on multiple MoE models and benchmarks. The results demonstrate that C-Prune effectively reduces model size while outperforming existing MoE pruning methods.
Redefining Machine Translation on Social Network Services with Large Language Models
Apr 10, 2025The globalization of social interactions has heightened the need for machine translation (MT) on Social Network Services (SNS), yet traditional models struggle with culturally nuanced content like memes, slang, and pop culture references. While large language models (LLMs) have advanced general-purpose translation, their performance on SNS-specific content remains limited due to insufficient specialized training data and evaluation benchmarks. This paper introduces RedTrans, a 72B LLM tailored for SNS translation, trained on a novel dataset developed through three innovations: (1) Supervised Finetuning with Dual-LLM Back-Translation Sampling, an unsupervised sampling method using LLM-based back-translation to select diverse data for large-scale finetuning; (2) Rewritten Preference Optimization (RePO), an algorithm that identifies and corrects erroneous preference pairs through expert annotation, building reliable preference corpora; and (3) RedTrans-Bench, the first benchmark for SNS translation, evaluating phenomena like humor localization, emoji semantics, and meme adaptation. Experiments show RedTrans outperforms state-of-the-art LLMs. Besides, RedTrans has already been deployed in a real-world production environment, demonstrating that domain-specific adaptation, effectively bridges the gap between generic and culturally grounded translation systems.
DependEval: Benchmarking LLMs for Repository Dependency Understanding
Mar 09, 2025While large language models (LLMs) have shown considerable promise in code generation, real-world software development demands advanced repository-level reasoning. This includes understanding dependencies, project structures, and managing multi-file changes. However, the ability of LLMs to effectively comprehend and handle complex code repositories has yet to be fully explored. To address challenges, we introduce a hierarchical benchmark designed to evaluate repository dependency understanding (DependEval). Benchmark is based on 15,576 repositories collected from real-world websites. It evaluates models on three core tasks: Dependency Recognition, Repository Construction, and Multi-file Editing, across 8 programming languages from actual code repositories. Our evaluation of over 25 LLMs reveals substantial performance gaps and provides valuable insights into repository-level code understanding.