 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepScorer: Accelerating Reinforcement Learning with Step-wise Scoring and Psychological Regret Modeling
Feb 03, 2026Reinforcement learning algorithms often suffer from slow convergence due to sparse reward signals, particularly in complex environments where feedback is delayed or infrequent. This paper introduces the Psychological Regret Model (PRM), a novel approach that accelerates learning by incorporating regret-based feedback signals after each decision step. Rather than waiting for terminal rewards, PRM computes a regret signal based on the difference between the expected value of the optimal action and the value of the action taken in each state. This transforms sparse rewards into dense feedback signals through a step-wise scoring framework, enabling faster convergence. We demonstrate that PRM achieves stable performance approximately 36\% faster than traditional Proximal Policy Optimization (PPO) in benchmark environments such as Lunar Lander. Our results indicate that PRM is particularly effective in continuous control tasks and environments with delayed feedback, making it suitable for real-world applications such as robotics, finance, and adaptive education where rapid policy adaptation is critical. The approach formalizes human-inspired counterfactual thinking as a computable regret signal, bridging behavioral economics and reinforcement learning.
MOSS Transcribe Diarize: Accurate Transcription with Speaker Diarization
Jan 08, 2026Speaker-Attributed, Time-Stamped Transcription (SATS) aims to transcribe what is said and to precisely determine the timing of each speaker, which is particularly valuable for meeting transcription. Existing SATS systems rarely adopt an end-to-end formulation and are further constrained by limited context windows, weak long-range speaker memory, and the inability to output timestamps. To address these limitations, we present MOSS Transcribe Diarize, a unified multimodal large language model that jointly performs Speaker-Attributed, Time-Stamped Transcription in an end-to-end paradigm. Trained on extensive real wild data and equipped with a 128k context window for up to 90-minute inputs, MOSS Transcribe Diarize scales well and generalizes robustly. Across comprehensive evaluations, it outperforms state-of-the-art commercial systems on multiple public and in-house benchmarks.
Inferring Causal Graph Temporal Logic Formulas to Expedite Reinforcement Learning in Temporally Extended Tasks
Jan 06, 2026Decision-making tasks often unfold on graphs with spatial-temporal dynamics. Black-box reinforcement learning often overlooks how local changes spread through network structure, limiting sample efficiency and interpretability. We present GTL-CIRL, a closed-loop framework that simultaneously learns policies and mines Causal Graph Temporal Logic (Causal GTL) specifications. The method shapes rewards with robustness, collects counterexamples when effects fail, and uses Gaussian Process (GP) driven Bayesian optimization to refine parameterized cause templates. The GP models capture spatial and temporal correlations in the system dynamics, enabling efficient exploration of complex parameter spaces. Case studies in gene and power networks show faster learning and clearer, verifiable behavior compared to standard RL baselines.
Causal-HalBench: Uncovering LVLMs Object Hallucinations Through Causal Intervention
Nov 13, 2025Large Vision-Language Models (LVLMs) often suffer from object hallucination, making erroneous judgments about the presence of objects in images. We propose this primar- ily stems from spurious correlations arising when models strongly associate highly co-occurring objects during train- ing, leading to hallucinated objects influenced by visual con- text. Current benchmarks mainly focus on hallucination de- tection but lack a formal characterization and quantitative evaluation of spurious correlations in LVLMs. To address this, we introduce causal analysis into the object recognition scenario of LVLMs, establishing a Structural Causal Model (SCM). Utilizing the language of causality, we formally de- fine spurious correlations arising from co-occurrence bias. To quantify the influence induced by these spurious correla- tions, we develop Causal-HalBench, a benchmark specifically constructed with counterfactual samples and integrated with comprehensive causal metrics designed to assess model ro- bustness against spurious correlations. Concurrently, we pro- pose an extensible pipeline for the construction of these coun- terfactual samples, leveraging the capabilities of proprietary LVLMs and Text-to-Image (T2I) models for their genera- tion. Our evaluations on mainstream LVLMs using Causal- HalBench demonstrate these models exhibit susceptibility to spurious correlations, albeit to varying extents.
RedOne 2.0: Rethinking Domain-specific LLM Post-Training in Social Networking Services
Nov 10, 2025As a key medium for human interaction and information exchange, social networking services (SNS) pose unique challenges for large language models (LLMs): heterogeneous workloads, fast-shifting norms and slang, and multilingual, culturally diverse corpora that induce sharp distribution shift. Supervised fine-tuning (SFT) can specialize models but often triggers a ``seesaw'' between in-distribution gains and out-of-distribution robustness, especially for smaller models. To address these challenges, we introduce RedOne 2.0, an SNS-oriented LLM trained with a progressive, RL-prioritized post-training paradigm designed for rapid and stable adaptation. The pipeline consist in three stages: (1) Exploratory Learning on curated SNS corpora to establish initial alignment and identify systematic weaknesses; (2) Targeted Fine-Tuning that selectively applies SFT to the diagnosed gaps while mixing a small fraction of general data to mitigate forgetting; and (3) Refinement Learning that re-applies RL with SNS-centric signals to consolidate improvements and harmonize trade-offs across tasks. Across various tasks spanning three categories, our 4B scale model delivers an average improvements about 2.41 over the 7B sub-optimal baseline. Additionally, RedOne 2.0 achieves average performance lift about 8.74 from the base model with less than half the data required by SFT-centric method RedOne, evidencing superior data efficiency and stability at compact scales. Overall, RedOne 2.0 establishes a competitive, cost-effective baseline for domain-specific LLMs in SNS scenario, advancing capability without sacrificing robustness.
Global Feature Enhancing and Fusion Framework for Strain Gauge Time Series Classification
Nov 07, 2025



Strain Gauge Status (SGS) recognition is crucial in the field of intelligent manufacturing based on the Internet of Things, as accurate identification helps timely detection of failed mechanical components, avoiding accidents. The loading and unloading sequences generated by strain gauges can be identified through time series classification (TSC) algorithms. Recently, deep learning models, e.g., convolutional neural networks (CNNs) have shown remarkable success in the TSC task, as they can extract discriminative local features from the subsequences to identify the time series. However, we observe that only the local features may not be sufficient for expressing the time series, especially when the local sub-sequences between different time series are very similar, e.g., SGS data of aircraft wings in static strength experiments. Nevertheless, CNNs suffer from the limitation in extracting global features due to the nature of convolution operations. For extracting global features to more comprehensively represent the SGS time series, we propose two insights: (i) Constructing global features through feature engineering. (ii) Learning high-order relationships between local features to capture global features. To realize and utilize them, we propose a hypergraph-based global feature learning and fusion framework, which learns and fuses global features for semantic consistency to enhance the representation of SGS time series, thereby improving recognition accuracy. Our method designs are validated on industrial SGS and public UCR datasets, showing better generalization for unseen data in SGS recognition.
MOSS-Speech: Towards True Speech-to-Speech Models Without Text Guidance
Oct 02, 2025



Spoken dialogue systems often rely on cascaded pipelines that transcribe, process, and resynthesize speech. While effective, this design discards paralinguistic cues and limits expressivity. Recent end-to-end methods reduce latency and better preserve these cues, yet still rely on text intermediates, creating a fundamental bottleneck. We present MOSS-Speech, a true speech-to-speech large language model that directly understands and generates speech without relying on text guidance. Our approach combines a modality-based layer-splitting architecture with a frozen pre-training strategy, preserving the reasoning and knowledge of pretrained text LLMs while adding native speech capabilities. Experiments show that our model achieves state-of-the-art results in spoken question answering and delivers comparable speech-to-speech performance relative to existing text-guided systems, while still maintaining competitive text performance. By narrowing the gap between text-guided and direct speech generation, our work establishes a new paradigm for expressive and efficient end-to-end speech interaction.
An Adaptive ICP LiDAR Odometry Based on Reliable Initial Pose
Sep 26, 2025As a key technology for autonomous navigation and positioning in mobile robots, light detection and ranging (LiDAR) odometry is widely used in autonomous driving applications. The Iterative Closest Point (ICP)-based methods have become the core technique in LiDAR odometry due to their efficient and accurate point cloud registration capability. However, some existing ICP-based methods do not consider the reliability of the initial pose, which may cause the method to converge to a local optimum. Furthermore, the absence of an adaptive mechanism hinders the effective handling of complex dynamic environments, resulting in a significant degradation of registration accuracy. To address these issues, this paper proposes an adaptive ICP-based LiDAR odometry method that relies on a reliable initial pose. First, distributed coarse registration based on density filtering is employed to obtain the initial pose estimation. The reliable initial pose is then selected by comparing it with the motion prediction pose, reducing the initial error between the source and target point clouds. Subsequently, by combining the current and historical errors, the adaptive threshold is dynamically adjusted to accommodate the real-time changes in the dynamic environment. Finally, based on the reliable initial pose and the adaptive threshold, point-to-plane adaptive ICP registration is performed from the current frame to the local map, achieving high-precision alignment of the source and target point clouds. Extensive experiments on the public KITTI dataset demonstrate that the proposed method outperforms existing approaches and significantly enhances the accuracy of LiDAR odometry.
Jupiter: Enhancing LLM Data Analysis Capabilities via Notebook and Inference-Time Value-Guided Search
Sep 11, 2025

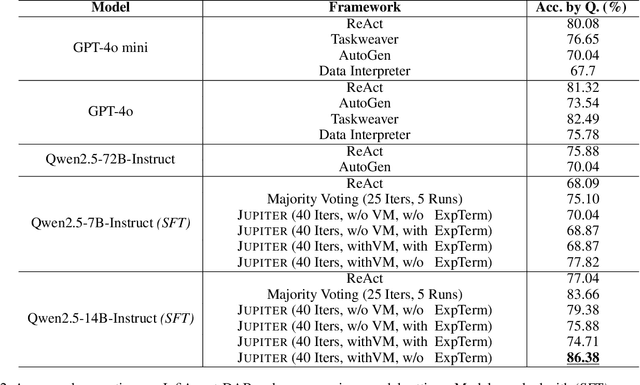
Large language models (LLMs) have shown great promise in automating data science workflows, but existing models still struggle with multi-step reasoning and tool use, which limits their effectiveness on complex data analysis tasks. To address this, we propose a scalable pipeline that extracts high-quality, tool-based data analysis tasks and their executable multi-step solutions from real-world Jupyter notebooks and associated data files. Using this pipeline, we introduce NbQA, a large-scale dataset of standardized task-solution pairs that reflect authentic tool-use patterns in practical data science scenarios. To further enhance multi-step reasoning, we present Jupiter, a framework that formulates data analysis as a search problem and applies Monte Carlo Tree Search (MCTS) to generate diverse solution trajectories for value model learning. During inference, Jupiter combines the value model and node visit counts to efficiently collect executable multi-step plans with minimal search steps. Experimental results show that Qwen2.5-7B and 14B-Instruct models on NbQA solve 77.82% and 86.38% of tasks on InfiAgent-DABench, respectively-matching or surpassing GPT-4o and advanced agent frameworks. Further evaluations demonstrate improved generalization and stronger tool-use reasoning across diverse multi-step reasoning tasks.
Attention Basin: Why Contextual Position Matters in Large Language Models
Aug 07, 2025The performance of Large Language Models (LLMs) is significantly sensitive to the contextual position of information in the input. To investigate the mechanism behind this positional bias, our extensive experiments reveal a consistent phenomenon we term the attention basin: when presented with a sequence of structured items (e.g., retrieved documents or few-shot examples), models systematically assign higher attention to the items at the beginning and end of the sequence, while neglecting those in the middle. Crucially, our analysis further reveals that allocating higher attention to critical information is key to enhancing model performance. Based on these insights, we introduce Attention-Driven Reranking (AttnRank), a two-stage framework that (i) estimates a model's intrinsic positional attention preferences using a small calibration set, and (ii) reorders retrieved documents or few-shot examples to align the most salient content with these high-attention positions. AttnRank is a model-agnostic, training-free, and plug-and-play method with minimal computational overhead. Experiments on multi-hop QA and few-shot in-context learning tasks demonstrate that AttnRank achieves substantial improvements across 10 large language models of varying architectures and scales, without modifying model parameters or training procedures.