 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Embodied AI Reliable: A Community Agenda from Testing to Formal Verification
Jun 02, 2026Embodied AI systems are increasingly deployed in open-world environments, yet ensuring their reliability remains a fundamental challenge. Drawing on discussions from the AAAI'26 Bridge Program on "Making Embodied AI Reliable with Testing and Formal Verification", this article argues that reliability in embodied AI is inherently a lifecycle assurance problem arising from uncertainty, human interaction, and emergent behaviors across tightly coupled system components. We identify three complementary directions toward reliable embodied AI: (1) trustworthy scenario-based testing supported by validated specifications and meaningful coverage metrics, (2) compositional verification enabled by structured symbolic representations of system behavior and environmental context, and (3) runtime assurance mechanisms capable of adapting to uncertainty and distribution shifts during deployment. Rather than treating these approaches independently, we advocate integrated assurance workflows that connect testing, verification, and runtime adaptation through shared neuro-symbolic representations and continuous feedback across the system lifecycle. Such integration provides a foundation for building trustworthy embodied AI systems that can operate safely and reliably in complex real-world environments.
Detecting Diffusion-Generated Time Series Under Generator Shift
May 27, 2026The boundary between real and diffusion-generated time series is becoming increasingly difficult to draw, yet detection in this domain remains underexplored, especially when the generator is unknown. We compare white-box detection, which requires access to the generator, against black-box detection, which operates on the raw signal alone. The white-box approach, a reconstruction-based detector adapted from the image domain, works well in in-distribution but breaks down under generator shift: reconstruction-based detection in images succeeds because large generic generators provide a near-universal reconstruction prior, and no analogous generator exists for time series. In contrast, a simple off-the-shelf classifier used as a black-box detector performs remarkably well, achieving an average F1 of 79.2, a 22.1% relative improvement over the white-box approach, and a TPR@1%FPR of 57.2. Diffusion-generated time series detection is therefore not a direct transfer of the image domain problem. This work provides the first systematic exploration of white-box and black-box detection for diffusion-generated time series. We close by identifying several open and promising directions.
Evaluating Counterfactual Explanation Methods on Incomplete Inputs
Apr 09, 2026Existing algorithms for generating Counterfactual Explanations (CXs) for Machine Learning (ML) typically assume fully specified inputs. However, real-world data often contains missing values, and the impact of these incomplete inputs on the performance of existing CX methods remains unexplored. To address this gap, we systematically evaluate recent CX generation methods on their ability to provide valid and plausible counterfactuals when inputs are incomplete. As part of this investigation, we hypothesize that robust CX generation methods will be better suited to address the challenge of providing valid and plausible counterfactuals when inputs are incomplete. Our findings reveal that while robust CX methods achieve higher validity than non-robust ones, all methods struggle to find valid counterfactuals. These results motivate the need for new CX methods capable of handling incomplete inputs.
Reinforcement Learning with Symbolic Reward Machines
Mar 03, 2026Reward Machines (RMs) are an established mechanism in Reinforcement Learning (RL) to represent and learn sparse, temporally extended tasks with non-Markovian rewards. RMs rely on high-level information in the form of labels that are emitted by the environment alongside the observation. However, this concept requires manual user input for each environment and task. The user has to create a suitable labeling function that computes the labels. These limitations lead to poor applicability in widely adopted RL frameworks. We propose Symbolic Reward Machines (SRMs) together with the learning algorithms QSRM and LSRM to overcome the limitations of RMs. SRMs consume only the standard output of the environment and process the observation directly through guards that are represented by symbolic formulas. In our evaluation, our SRM methods outperform the baseline RL approaches and generate the same results as the existing RM methods. At the same time, our methods adhere to the widely used environment definition and provide interpretable representations of the task to the user.
On Uniformly Scaling Flows: A Density-Aligned Approach to Deep One-Class Classification
Oct 10, 2025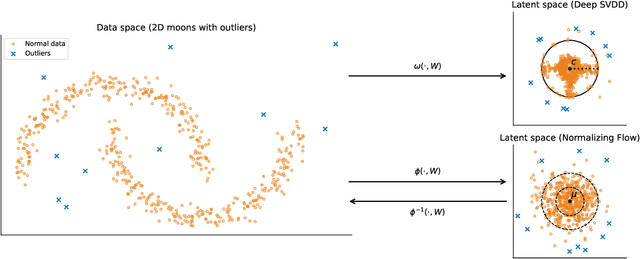
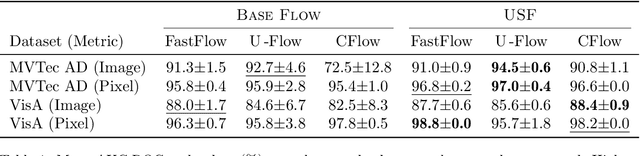
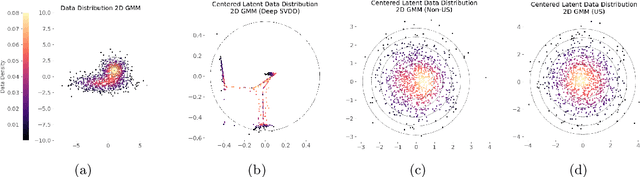
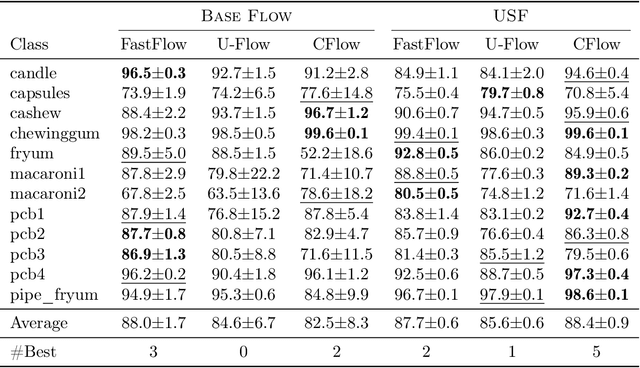
Unsupervised anomaly detection is often framed around two widely studied paradigms. Deep one-class classification, exemplified by Deep SVDD, learns compact latent representations of normality, while density estimators realized by normalizing flows directly model the likelihood of nominal data. In this work, we show that uniformly scaling flows (USFs), normalizing flows with a constant Jacobian determinant, precisely connect these approaches. Specifically, we prove how training a USF via maximum-likelihood reduces to a Deep SVDD objective with a unique regularization that inherently prevents representational collapse. This theoretical bridge implies that USFs inherit both the density faithfulness of flows and the distance-based reasoning of one-class methods. We further demonstrate that USFs induce a tighter alignment between negative log-likelihood and latent norm than either Deep SVDD or non-USFs, and how recent hybrid approaches combining one-class objectives with VAEs can be naturally extended to USFs. Consequently, we advocate using USFs as a drop-in replacement for non-USFs in modern anomaly detection architectures. Empirically, this substitution yields consistent performance gains and substantially improved training stability across multiple benchmarks and model backbones for both image-level and pixel-level detection. These results unify two major anomaly detection paradigms, advancing both theoretical understanding and practical performance.
Decentralizing Multi-Agent Reinforcement Learning with Temporal Causal Information
Jun 09, 2025Reinforcement learning (RL) algorithms can find an optimal policy for a single agent to accomplish a particular task. However, many real-world problems require multiple agents to collaborate in order to achieve a common goal. For example, a robot executing a task in a warehouse may require the assistance of a drone to retrieve items from high shelves. In Decentralized Multi-Agent RL (DMARL), agents learn independently and then combine their policies at execution time, but often must satisfy constraints on compatibility of local policies to ensure that they can achieve the global task when combined. In this paper, we study how providing high-level symbolic knowledge to agents can help address unique challenges of this setting, such as privacy constraints, communication limitations, and performance concerns. In particular, we extend the formal tools used to check the compatibility of local policies with the team task, making decentralized training with theoretical guarantees usable in more scenarios. Furthermore, we empirically demonstrate that symbolic knowledge about the temporal evolution of events in the environment can significantly expedite the learning process in DMARL.
A Cautionary Tale About "Neutrally" Informative AI Tools Ahead of the 2025 Federal Elections in Germany
Feb 21, 2025In this study, we examine the reliability of AI-based Voting Advice Applications (VAAs) and large language models (LLMs) in providing objective political information. Our analysis is based upon a comparison with party responses to 38 statements of the Wahl-O-Mat, a well-established German online tool that helps inform voters by comparing their views with political party positions. For the LLMs, we identify significant biases. They exhibit a strong alignment (over 75% on average) with left-wing parties and a substantially lower alignment with center-right (smaller 50%) and right-wing parties (around 30%). Furthermore, for the VAAs, intended to objectively inform voters, we found substantial deviations from the parties' stated positions in Wahl-O-Mat: While one VAA deviated in 25% of cases, another VAA showed deviations in more than 50% of cases. For the latter, we even observed that simple prompt injections led to severe hallucinations, including false claims such as non-existent connections between political parties and right-wing extremist ties.
What is Formal Verification without Specifications? A Survey on mining LTL Specifications
Jan 27, 2025Virtually all verification techniques using formal methods rely on the availability of a formal specification, which describes the design requirements precisely. However, formulating specifications remains a manual task that is notoriously challenging and error-prone. To address this bottleneck in formal verification, recent research has thus focussed on automatically generating specifications for formal verification from examples of (desired and undesired) system behavior. In this survey, we list and compare recent advances in mining specifications in Linear Temporal Logic (LTL), the de facto standard specification language for reactive systems. Several approaches have been designed for learning LTL formulas, which address different aspects and settings of specification design. Moreover, the approaches rely on a diverse range of techniques such as constraint solving, neural network training, enumerative search, etc. We survey the current state-of-the-art techniques and compare them for the convenience of the formal methods practitioners.
Learning Tree Pattern Transformations
Oct 10, 2024
Explaining why and how a tree $t$ structurally differs from another tree $t^*$ is a question that is encountered throughout computer science, including in understanding tree-structured data such as XML or JSON data. In this article, we explore how to learn explanations for structural differences between pairs of trees from sample data: suppose we are given a set $\{(t_1, t_1^*),\dots, (t_n, t_n^*)\}$ of pairs of labelled, ordered trees; is there a small set of rules that explains the structural differences between all pairs $(t_i, t_i^*)$? This raises two research questions: (i) what is a good notion of "rule" in this context?; and (ii) how can sets of rules explaining a data set be learnt algorithmically? We explore these questions from the perspective of database theory by (1) introducing a pattern-based specification language for tree transformations; (2) exploring the computational complexity of variants of the above algorithmic problem, e.g. showing NP-hardness for very restricted variants; and (3) discussing how to solve the problem for data from CS education research using SAT solvers.
VeriFlow: Modeling Distributions for Neural Network Verification
Jun 20, 2024Formal verification has emerged as a promising method to ensure the safety and reliability of neural networks. Naively verifying a safety property amounts to ensuring the safety of a neural network for the whole input space irrespective of any training or test set. However, this also implies that the safety of the neural network is checked even for inputs that do not occur in the real-world and have no meaning at all, often resulting in spurious errors. To tackle this shortcoming, we propose the VeriFlow architecture as a flow based density model tailored to allow any verification approach to restrict its search to the some data distribution of interest. We argue that our architecture is particularly well suited for this purpose because of two major properties. First, we show that the transformation and log-density function that are defined by our model are piece-wise affine. Therefore, the model allows the usage of verifiers based on SMT with linear arithmetic. Second, upper density level sets (UDL) of the data distribution take the shape of an $L^p$-ball in the latent space. As a consequence, representations of UDLs specified by a given probability are effectively computable in latent space. This allows for SMT and abstract interpretation approaches with fine-grained, probabilistically interpretable, control regarding on how (a)typical the inputs subject to verification are.