 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Coalition Structure Detection in Natural Language-based Interactions
Feb 22, 2025In strategic multi-agent sequential interactions, detecting dynamic coalition structures is crucial for understanding how self-interested agents coordinate to influence outcomes. However, natural-language-based interactions introduce unique challenges to coalition detection due to ambiguity over intents and difficulty in modeling players' subjective perspectives. We propose a new method that leverages recent advancements in large language models and game theory to predict dynamic multilateral coalition formation in Diplomacy, a strategic multi-agent game where agents negotiate coalitions using natural language. The method consists of two stages. The first stage extracts the set of agreements discussed by two agents in their private dialogue, by combining a parsing-based filtering function with a fine-tuned language model trained to predict player intents. In the second stage, we define a new metric using the concept of subjective rationalizability from hypergame theory to evaluate the expected value of an agreement for each player. We then compute this metric for each agreement identified in the first stage by assessing the strategic value of the agreement for both players and taking into account the subjective belief of one player that the second player would honor the agreement. We demonstrate that our method effectively detects potential coalition structures in online Diplomacy gameplay by assigning high values to agreements likely to be honored and low values to those likely to be violated. The proposed method provides foundational insights into coalition formation in multi-agent environments with language-based negotiation and offers key directions for future research on the analysis of complex natural language-based interactions between agents.
Using Large Language Models to Automate and Expedite Reinforcement Learning with Reward Machine
Feb 11, 2024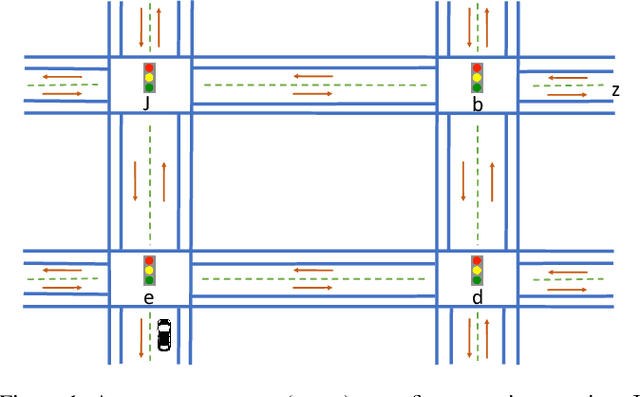
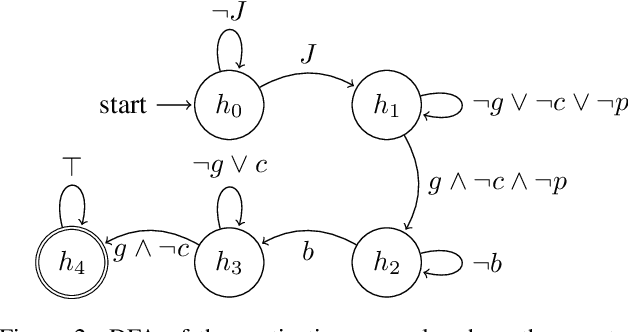


We present LARL-RM (Large language model-generated Automaton for Reinforcement Learning with Reward Machine) algorithm in order to encode high-level knowledge into reinforcement learning using automaton to expedite the reinforcement learning. Our method uses Large Language Models (LLM) to obtain high-level domain-specific knowledge using prompt engineering instead of providing the reinforcement learning algorithm directly with the high-level knowledge which requires an expert to encode the automaton. We use chain-of-thought and few-shot methods for prompt engineering and demonstrate that our method works using these approaches. Additionally, LARL-RM allows for fully closed-loop reinforcement learning without the need for an expert to guide and supervise the learning since LARL-RM can use the LLM directly to generate the required high-level knowledge for the task at hand. We also show the theoretical guarantee of our algorithm to converge to an optimal policy. We demonstrate that LARL-RM speeds up the convergence by 30% by implementing our method in two case studies.