 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent psychometrics: Task-level performance prediction in agentic coding benchmarks
Apr 01, 2026As the focus in LLM-based coding shifts from static single-step code generation to multi-step agentic interaction with tools and environments, understanding which tasks will challenge agents and why becomes increasingly difficult. This is compounded by current practice: agent performance is typically measured by aggregate pass rates on benchmarks, but single-number metrics obscure the diversity of tasks within a benchmark. We present a framework for predicting success or failure on individual tasks tailored to the agentic coding regime. Our approach augments Item Response Theory (IRT) with rich features extracted from tasks, including issue statements, repository contexts, solutions, and test cases, and introduces a novel decomposition of agent ability into LLM and scaffold ability components. This parameterization enables us to aggregate evaluation data across heterogeneous leaderboards and accurately predict task-level performance for unseen benchmarks, as well as unseen LLM-scaffold combinations. Our methods have practical utility for benchmark designers, who can better calibrate the difficulty of their new tasks without running computationally expensive agent evaluations.
How Well Does Agent Development Reflect Real-World Work?
Mar 01, 2026AI agents are increasingly developed and evaluated on benchmarks relevant to human work, yet it remains unclear how representative these benchmarking efforts are of the labor market as a whole. In this work, we systematically study the relationship between agent development efforts and the distribution of real-world human work by mapping benchmark instances to work domains and skills. We first analyze 43 benchmarks and 72,342 tasks, measuring their alignment with human employment and capital allocation across all 1,016 real-world occupations in the U.S. labor market. We reveal substantial mismatches between agent development that tends to be programming-centric, and the categories in which human labor and economic value are concentrated. Within work areas that agents currently target, we further characterize current agent utility by measuring their autonomy levels, providing practical guidance for agent interaction strategies across work scenarios. Building on these findings, we propose three measurable principles for designing benchmarks that better capture socially important and technically challenging forms of work: coverage, realism, and granular evaluation.
Hybrid-Gym: Training Coding Agents to Generalize Across Tasks
Feb 18, 2026When assessing the quality of coding agents, predominant benchmarks focus on solving single issues on GitHub, such as SWE-Bench. In contrast, in real use, these agents solve more various and complex tasks that involve other skills such as exploring codebases, testing software, and designing architecture. In this paper, we first characterize some transferable skills that are shared across diverse tasks by decomposing trajectories into fine-grained components, and derive a set of principles for designing auxiliary training tasks to teach language models these skills. Guided by these principles, we propose a training environment, Hybrid-Gym, consisting of a set of scalable synthetic tasks, such as function localization and dependency search. Experiments show that agents trained on our synthetic tasks effectively generalize to diverse real-world tasks that are not present in training, improving a base model by 25.4% absolute gain on SWE-Bench Verified, 7.9% on SWT-Bench Verified, and 5.1% on Commit-0 Lite. Hybrid-Gym also complements datasets built for the downstream tasks (e.g., improving SWE-Play by 4.9% on SWT-Bench Verified). Code available at: https://github.com/yiqingxyq/Hybrid-Gym.
Reasoning with Latent Tokens in Diffusion Language Models
Feb 03, 2026Discrete diffusion models have recently become competitive with autoregressive models for language modeling, even outperforming them on reasoning tasks requiring planning and global coherence, but they require more computation at inference time. We trace this trade-off to a key mechanism: diffusion models are trained to jointly predict a distribution over all unknown tokens, including those that will not actually be decoded in the current step. Ablating this joint prediction yields faster inference but degrades performance, revealing that accurate prediction at the decoded position relies on joint reasoning about the distribution of undecoded tokens. We interpret these as latent tokens and introduce a method for modulating their number, demonstrating empirically that this enables a smooth tradeoff between inference speed and sample quality. Furthermore, we demonstrate that latent tokens can be introduced into autoregressive models through an auxiliary multi-token prediction objective, yielding substantial improvements on the same reasoning tasks where they have traditionally struggled. Our results suggest that latent tokens, while arising naturally in diffusion, represent a general mechanism for improving performance on tasks requiring global coherence or lookahead.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Toward Training Superintelligent Software Agents through Self-Play SWE-RL
Dec 21, 2025While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.
Measuring Fine-Grained Negotiation Tactics of Humans and LLMs in Diplomacy
Dec 20, 2025The study of negotiation styles dates back to Aristotle's ethos-pathos-logos rhetoric. Prior efforts primarily studied the success of negotiation agents. Here, we shift the focus towards the styles of negotiation strategies. Our focus is the strategic dialogue board game Diplomacy, which affords rich natural language negotiation and measures of game success. We used LLM-as-a-judge to annotate a large human-human set of Diplomacy games for fine-grained negotiation tactics from a sociologically-grounded taxonomy. Using a combination of the It Takes Two and WebDiplomacy datasets, we demonstrate the reliability of our LLM-as-a-Judge framework and show strong correlations between negotiation features and success in the Diplomacy setting. Lastly, we investigate the differences between LLM and human negotiation strategies and show that fine-tuning can steer LLM agents toward more human-like negotiation behaviors.
Propose, Solve, Verify: Self-Play Through Formal Verification
Dec 20, 2025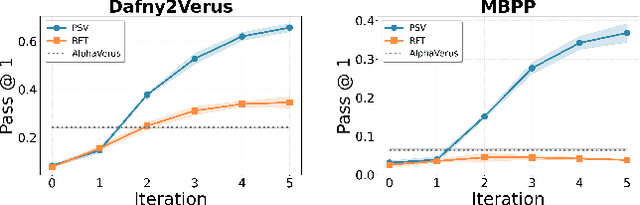
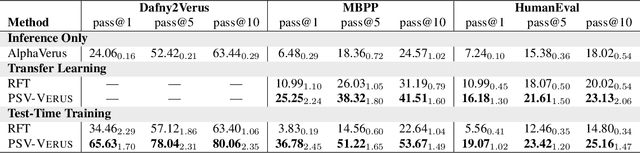
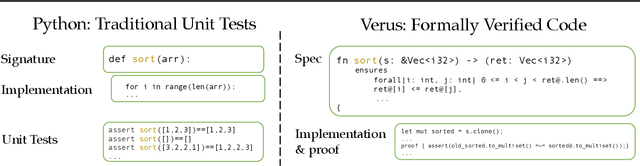

Training models through self-play alone (without any human data) has been a longstanding goal in AI, but its effectiveness for training large language models remains unclear, particularly in code generation where rewards based on unit tests are brittle and prone to error propagation. We study self-play in the verified code generation setting, where formal verification provides reliable correctness signals. We introduce Propose, Solve, Verify (PSV) a simple self-play framework where formal verification signals are used to create a proposer capable of generating challenging synthetic problems and a solver trained via expert iteration. We use PSV to train PSV-Verus, which across three benchmarks improves pass@1 by up to 9.6x over inference-only and expert-iteration baselines. We show that performance scales with the number of generated questions and training iterations, and through ablations identify formal verification and difficulty-aware proposal as essential ingredients for successful self-play.
How Do AI Agents Do Human Work? Comparing AI and Human Workflows Across Diverse Occupations
Oct 26, 2025AI agents are continually optimized for tasks related to human work, such as software engineering and professional writing, signaling a pressing trend with significant impacts on the human workforce. However, these agent developments have often not been grounded in a clear understanding of how humans execute work, to reveal what expertise agents possess and the roles they can play in diverse workflows. In this work, we study how agents do human work by presenting the first direct comparison of human and agent workers across multiple essential work-related skills: data analysis, engineering, computation, writing, and design. To better understand and compare heterogeneous computer-use activities of workers, we introduce a scalable toolkit to induce interpretable, structured workflows from either human or agent computer-use activities. Using such induced workflows, we compare how humans and agents perform the same tasks and find that: (1) While agents exhibit promise in their alignment to human workflows, they take an overwhelmingly programmatic approach across all work domains, even for open-ended, visually dependent tasks like design, creating a contrast with the UI-centric methods typically used by humans. (2) Agents produce work of inferior quality, yet often mask their deficiencies via data fabrication and misuse of advanced tools. (3) Nonetheless, agents deliver results 88.3% faster and cost 90.4-96.2% less than humans, highlighting the potential for enabling efficient collaboration by delegating easily programmable tasks to agents.
Identifying & Interactively Refining Ambiguous User Goals for Data Visualization Code Generation
Oct 10, 2025Establishing shared goals is a fundamental step in human-AI communication. However, ambiguities can lead to outputs that seem correct but fail to reflect the speaker's intent. In this paper, we explore this issue with a focus on the data visualization domain, where ambiguities in natural language impact the generation of code that visualizes data. The availability of multiple views on the contextual (e.g., the intended plot and the code rendering the plot) allows for a unique and comprehensive analysis of diverse ambiguity types. We develop a taxonomy of types of ambiguity that arise in this task and propose metrics to quantify them. Using Matplotlib problems from the DS-1000 dataset, we demonstrate that our ambiguity metrics better correlate with human annotations than uncertainty baselines. Our work also explores how multi-turn dialogue can reduce ambiguity, therefore, improve code accuracy by better matching user goals. We evaluate three pragmatic models to inform our dialogue strategies: Gricean Cooperativity, Discourse Representation Theory, and Questions under Discussion. A simulated user study reveals how pragmatic dialogues reduce ambiguity and enhance code accuracy, highlighting the value of multi-turn exchanges in code generation.