 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying & Interactively Refining Ambiguous User Goals for Data Visualization Code Generation
Oct 10, 2025Establishing shared goals is a fundamental step in human-AI communication. However, ambiguities can lead to outputs that seem correct but fail to reflect the speaker's intent. In this paper, we explore this issue with a focus on the data visualization domain, where ambiguities in natural language impact the generation of code that visualizes data. The availability of multiple views on the contextual (e.g., the intended plot and the code rendering the plot) allows for a unique and comprehensive analysis of diverse ambiguity types. We develop a taxonomy of types of ambiguity that arise in this task and propose metrics to quantify them. Using Matplotlib problems from the DS-1000 dataset, we demonstrate that our ambiguity metrics better correlate with human annotations than uncertainty baselines. Our work also explores how multi-turn dialogue can reduce ambiguity, therefore, improve code accuracy by better matching user goals. We evaluate three pragmatic models to inform our dialogue strategies: Gricean Cooperativity, Discourse Representation Theory, and Questions under Discussion. A simulated user study reveals how pragmatic dialogues reduce ambiguity and enhance code accuracy, highlighting the value of multi-turn exchanges in code generation.
SiLVERScore: Semantically-Aware Embeddings for Sign Language Generation Evaluation
Sep 04, 2025Evaluating sign language generation is often done through back-translation, where generated signs are first recognized back to text and then compared to a reference using text-based metrics. However, this two-step evaluation pipeline introduces ambiguity: it not only fails to capture the multimodal nature of sign language-such as facial expressions, spatial grammar, and prosody-but also makes it hard to pinpoint whether evaluation errors come from sign generation model or the translation system used to assess it. In this work, we propose SiLVERScore, a novel semantically-aware embedding-based evaluation metric that assesses sign language generation in a joint embedding space. Our contributions include: (1) identifying limitations of existing metrics, (2) introducing SiLVERScore for semantically-aware evaluation, (3) demonstrating its robustness to semantic and prosodic variations, and (4) exploring generalization challenges across datasets. On PHOENIX-14T and CSL-Daily datasets, SiLVERScore achieves near-perfect discrimination between correct and random pairs (ROC AUC = 0.99, overlap < 7%), substantially outperforming traditional metrics.
Measuring How (Not Just Whether) VLMs Build Common Ground
Sep 04, 2025Large vision language models (VLMs) increasingly claim reasoning skills, yet current benchmarks evaluate them in single-turn or question answering settings. However, grounding is an interactive process in which people gradually develop shared understanding through ongoing communication. We introduce a four-metric suite (grounding efficiency, content alignment, lexical adaptation, and human-likeness) to systematically evaluate VLM performance in interactive grounding contexts. We deploy the suite on 150 self-play sessions of interactive referential games between three proprietary VLMs and compare them with human dyads. All three models diverge from human patterns on at least three metrics, while GPT4o-mini is the closest overall. We find that (i) task success scores do not indicate successful grounding and (ii) high image-utterance alignment does not necessarily predict task success. Our metric suite and findings offer a framework for future research on VLM grounding.
Quantifying Sycophancy as Deviations from Bayesian Rationality in LLMs
Aug 23, 2025Sycophancy, or overly agreeable or flattering behavior, is a documented issue in large language models (LLMs), and is critical to understand in the context of human/AI collaboration. Prior works typically quantify sycophancy by measuring shifts in behavior or impacts on accuracy, but neither metric characterizes shifts in rationality, and accuracy measures can only be used in scenarios with a known ground truth. In this work, we utilize a Bayesian framework to quantify sycophancy as deviations from rational behavior when presented with user perspectives, thus distinguishing between rational and irrational updates based on the introduction of user perspectives. In comparison to other methods, this approach allows us to characterize excessive behavioral shifts, even for tasks that involve inherent uncertainty or do not have a ground truth. We study sycophancy for 3 different tasks, a combination of open-source and closed LLMs, and two different methods for probing sycophancy. We also experiment with multiple methods for eliciting probability judgments from LLMs. We hypothesize that probing LLMs for sycophancy will cause deviations in LLMs' predicted posteriors that will lead to increased Bayesian error. Our findings indicate that: 1) LLMs are not Bayesian rational, 2) probing for sycophancy results in significant increases to the predicted posterior in favor of the steered outcome, 3) sycophancy sometimes results in increased Bayesian error, and in a small number of cases actually decreases error, and 4) changes in Bayesian error due to sycophancy are not strongly correlated in Brier score, suggesting that studying the impact of sycophancy on ground truth alone does not fully capture errors in reasoning due to sycophancy.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025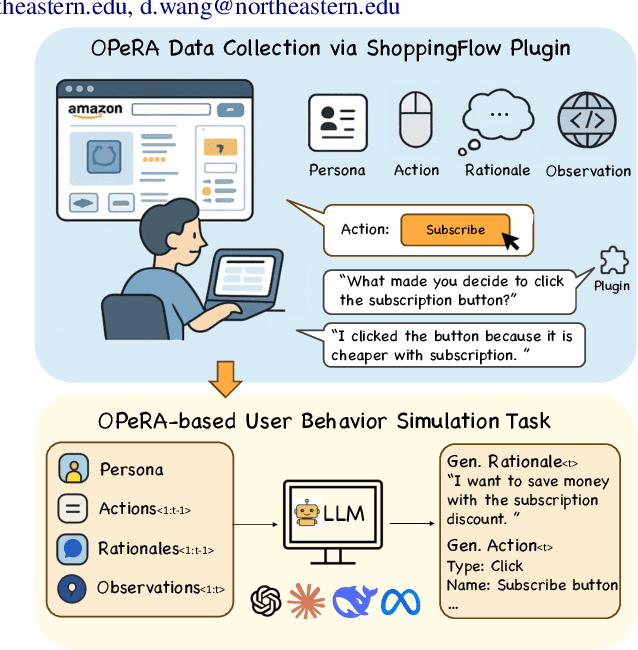
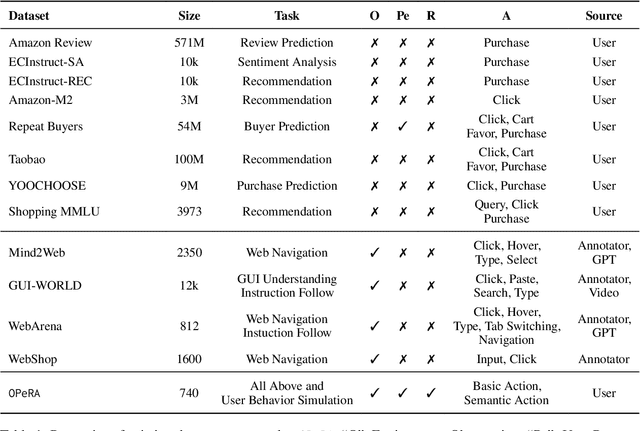
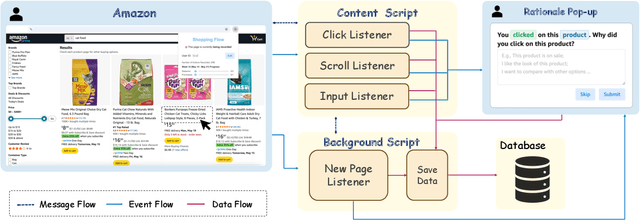
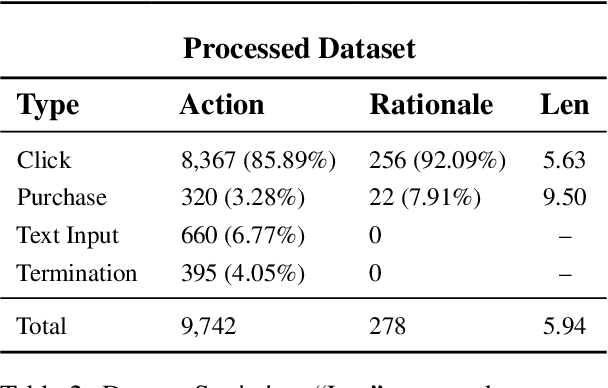
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
Human-centered explanation does not fit all: The interplay of sociotechnical, cognitive, and individual factors in the effect AI explanations in algorithmic decision-making
Feb 17, 2025Recent XAI studies have investigated what constitutes a \textit{good} explanation in AI-assisted decision-making. Despite the widely accepted human-friendly properties of explanations, such as contrastive and selective, existing studies have yielded inconsistent findings. To address these gaps, our study focuses on the cognitive dimensions of explanation evaluation, by evaluating six explanations with different contrastive strategies and information selectivity and scrutinizing factors behind their valuation process. Our analysis results find that contrastive explanations are not the most preferable or understandable in general; Rather, different contrastive and selective explanations were appreciated to a different extent based on who they are, when, how, and what to explain -- with different level of cognitive load and engagement and sociotechnical contexts. Given these findings, we call for a nuanced view of explanation strategies, with implications for designing AI interfaces to accommodate individual and contextual differences in AI-assisted decision-making.
Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems
Jan 31, 2025



While theories of discourse and cognitive science have long recognized the value of unhurried pacing, recent dialogue research tends to minimize friction in conversational systems. Yet, frictionless dialogue risks fostering uncritical reliance on AI outputs, which can obscure implicit assumptions and lead to unintended consequences. To meet this challenge, we propose integrating positive friction into conversational AI, which promotes user reflection on goals, critical thinking on system response, and subsequent re-conditioning of AI systems. We hypothesize systems can improve goal alignment, modeling of user mental states, and task success by deliberately slowing down conversations in strategic moments to ask questions, reveal assumptions, or pause. We present an ontology of positive friction and collect expert human annotations on multi-domain and embodied goal-oriented corpora. Experiments on these corpora, along with simulated interactions using state-of-the-art systems, suggest incorporating friction not only fosters accountable decision-making, but also enhances machine understanding of user beliefs and goals, and increases task success rates.
Contextual ASR Error Handling with LLMs Augmentation for Goal-Oriented Conversational AI
Jan 10, 2025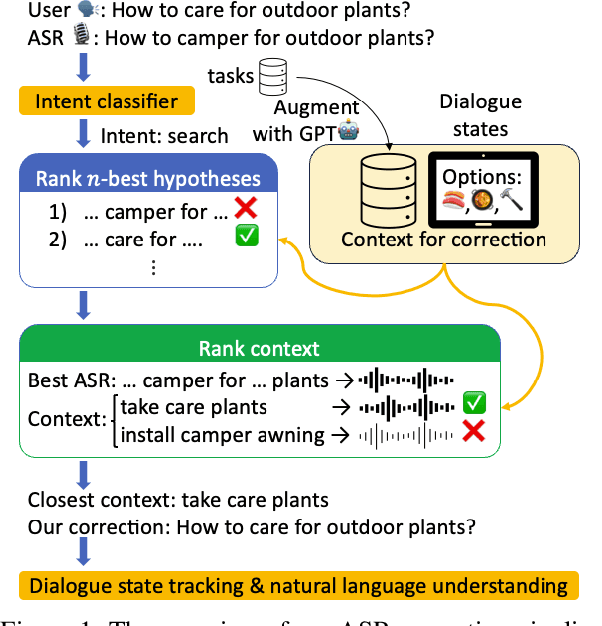
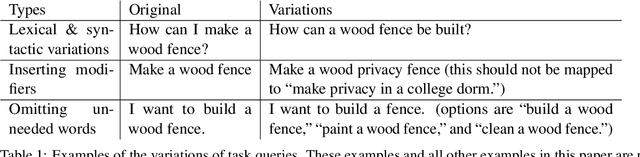


General-purpose automatic speech recognition (ASR) systems do not always perform well in goal-oriented dialogue. Existing ASR correction methods rely on prior user data or named entities. We extend correction to tasks that have no prior user data and exhibit linguistic flexibility such as lexical and syntactic variations. We propose a novel context augmentation with a large language model and a ranking strategy that incorporates contextual information from the dialogue states of a goal-oriented conversational AI and its tasks. Our method ranks (1) n-best ASR hypotheses by their lexical and semantic similarity with context and (2) context by phonetic correspondence with ASR hypotheses. Evaluated in home improvement and cooking domains with real-world users, our method improves recall and F1 of correction by 34% and 16%, respectively, while maintaining precision and false positive rate. Users rated .8-1 point (out of 5) higher when our correction method worked properly, with no decrease due to false positives.
Fairness at Every Intersection: Uncovering and Mitigating Intersectional Biases in Multimodal Clinical Predictions
Nov 30, 2024



Biases in automated clinical decision-making using Electronic Healthcare Records (EHR) impose significant disparities in patient care and treatment outcomes. Conventional approaches have primarily focused on bias mitigation strategies stemming from single attributes, overlooking intersectional subgroups -- groups formed across various demographic intersections (such as race, gender, ethnicity, etc.). Rendering single-attribute mitigation strategies to intersectional subgroups becomes statistically irrelevant due to the varying distribution and bias patterns across these subgroups. The multimodal nature of EHR -- data from various sources such as combinations of text, time series, tabular, events, and images -- adds another layer of complexity as the influence on minority groups may fluctuate across modalities. In this paper, we take the initial steps to uncover potential intersectional biases in predictions by sourcing extensive multimodal datasets, MIMIC-Eye1 and MIMIC-IV ED, and propose mitigation at the intersectional subgroup level. We perform and benchmark downstream tasks and bias evaluation on the datasets by learning a unified text representation from multimodal sources, harnessing the enormous capabilities of the pre-trained clinical Language Models (LM), MedBERT, Clinical BERT, and Clinical BioBERT. Our findings indicate that the proposed sub-group-specific bias mitigation is robust across different datasets, subgroups, and embeddings, demonstrating effectiveness in addressing intersectional biases in multimodal settings.
Coherence-Driven Multimodal Safety Dialogue with Active Learning for Embodied Agents
Oct 18, 2024

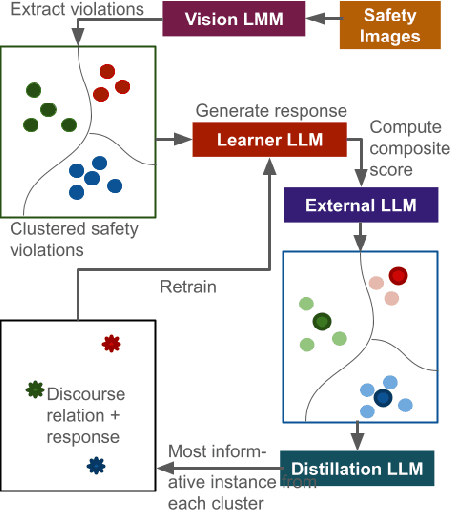
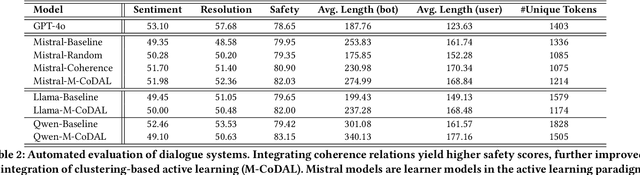
When assisting people in daily tasks, robots need to accurately interpret visual cues and respond effectively in diverse safety-critical situations, such as sharp objects on the floor. In this context, we present M-CoDAL, a multimodal-dialogue system specifically designed for embodied agents to better understand and communicate in safety-critical situations. The system leverages discourse coherence relations to enhance its contextual understanding and communication abilities. To train this system, we introduce a novel clustering-based active learning mechanism that utilizes an external Large Language Model (LLM) to identify informative instances. Our approach is evaluated using a newly created multimodal dataset comprising 1K safety violations extracted from 2K Reddit images. These violations are annotated using a Large Multimodal Model (LMM) and verified by human annotators. Results with this dataset demonstrate that our approach improves resolution of safety situations, user sentiment, as well as safety of the conversation. Next, we deploy our dialogue system on a Hello Robot Stretch robot and conduct a within-subject user study with real-world participants. In the study, participants role-play two safety scenarios with different levels of severity with the robot and receive interventions from our model and a baseline system powered by OpenAI's ChatGPT. The study results corroborate and extend the findings from automated evaluation, showing that our proposed system is more persuasive and competent in a real-world embodied agent setting.