 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTD-EVAL: Revisiting Task-Oriented Dialogue Evaluation by Combining Turn-Level Precision with Dialogue-Level Comparisons
Apr 28, 2025



Task-oriented dialogue (TOD) systems are experiencing a revolution driven by Large Language Models (LLMs), yet the evaluation methodologies for these systems remain insufficient for their growing sophistication. While traditional automatic metrics effectively assessed earlier modular systems, they focus solely on the dialogue level and cannot detect critical intermediate errors that can arise during user-agent interactions. In this paper, we introduce TD-EVAL (Turn and Dialogue-level Evaluation), a two-step evaluation framework that unifies fine-grained turn-level analysis with holistic dialogue-level comparisons. At turn level, we evaluate each response along three TOD-specific dimensions: conversation cohesion, backend knowledge consistency, and policy compliance. Meanwhile, we design TOD Agent Arena that uses pairwise comparisons to provide a measure of dialogue-level quality. Through experiments on MultiWOZ 2.4 and {\tau}-Bench, we demonstrate that TD-EVAL effectively identifies the conversational errors that conventional metrics miss. Furthermore, TD-EVAL exhibits better alignment with human judgments than traditional and LLM-based metrics. These findings demonstrate that TD-EVAL introduces a new paradigm for TOD system evaluation, efficiently assessing both turn and system levels with a plug-and-play framework for future research.
Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems
Jan 31, 2025



While theories of discourse and cognitive science have long recognized the value of unhurried pacing, recent dialogue research tends to minimize friction in conversational systems. Yet, frictionless dialogue risks fostering uncritical reliance on AI outputs, which can obscure implicit assumptions and lead to unintended consequences. To meet this challenge, we propose integrating positive friction into conversational AI, which promotes user reflection on goals, critical thinking on system response, and subsequent re-conditioning of AI systems. We hypothesize systems can improve goal alignment, modeling of user mental states, and task success by deliberately slowing down conversations in strategic moments to ask questions, reveal assumptions, or pause. We present an ontology of positive friction and collect expert human annotations on multi-domain and embodied goal-oriented corpora. Experiments on these corpora, along with simulated interactions using state-of-the-art systems, suggest incorporating friction not only fosters accountable decision-making, but also enhances machine understanding of user beliefs and goals, and increases task success rates.
BoK: Introducing Bag-of-Keywords Loss for Interpretable Dialogue Response Generation
Jan 17, 2025The standard language modeling (LM) loss by itself has been shown to be inadequate for effective dialogue modeling. As a result, various training approaches, such as auxiliary loss functions and leveraging human feedback, are being adopted to enrich open-domain dialogue systems. One such auxiliary loss function is Bag-of-Words (BoW) loss, defined as the cross-entropy loss for predicting all the words/tokens of the next utterance. In this work, we propose a novel auxiliary loss named Bag-of-Keywords (BoK) loss to capture the central thought of the response through keyword prediction and leverage it to enhance the generation of meaningful and interpretable responses in open-domain dialogue systems. BoK loss upgrades the BoW loss by predicting only the keywords or critical words/tokens of the next utterance, intending to estimate the core idea rather than the entire response. We incorporate BoK loss in both encoder-decoder (T5) and decoder-only (DialoGPT) architecture and train the models to minimize the weighted sum of BoK and LM (BoK-LM) loss. We perform our experiments on two popular open-domain dialogue datasets, DailyDialog and Persona-Chat. We show that the inclusion of BoK loss improves the dialogue generation of backbone models while also enabling post-hoc interpretability. We also study the effectiveness of BoK-LM loss as a reference-free metric and observe comparable performance to the state-of-the-art metrics on various dialogue evaluation datasets.
Towards Preventing Overreliance on Task-Oriented Conversational AI Through Accountability Modeling
Jan 17, 2025Recent LLMs have enabled significant advancements for conversational agents. However, they are also well-known to hallucinate, i.e., they often produce responses that seem plausible but are not factually correct. On the other hand, users tend to over-rely on LLM-based AI agents; they accept the AI's suggestion even when it is wrong. Adding good friction, such as explanations or getting user confirmations, has been proposed as a mitigation in AI-supported decision-making systems. In this paper, we propose an accountability model for LLM-based task-oriented dialogue agents to address user overreliance via friction turns in cases of model uncertainty and errors associated with dialogue state tracking (DST). The accountability model is an augmented LLM with an additional accountability head, which functions as a binary classifier to predict the slots of the dialogue states. We perform our experiments with three backbone LLMs (Llama, Mistral, Gemma) on two established task-oriented datasets (MultiWOZ and Snips). Our empirical findings demonstrate that this approach not only enables reliable estimation of AI agent errors but also guides the LLM decoder in generating more accurate actions. We observe around 3% absolute improvement in joint goal accuracy by incorporating accountability heads in modern LLMs for the MultiWOZ dataset. We also show that this method enables the agent to self-correct its actions, further boosting its performance by 3%. Finally, we discuss the application of accountability modeling to prevent user overreliance by introducing friction.
ReSpAct: Harmonizing Reasoning, Speaking, and Acting Towards Building Large Language Model-Based Conversational AI Agents
Nov 01, 2024



Large language model (LLM)-based agents have been increasingly used to interact with external environments (e.g., games, APIs, etc.) and solve tasks. However, current frameworks do not enable these agents to work with users and interact with them to align on the details of their tasks and reach user-defined goals; instead, in ambiguous situations, these agents may make decisions based on assumptions. This work introduces ReSpAct (Reason, Speak, and Act), a novel framework that synergistically combines the essential skills for building task-oriented "conversational" agents. ReSpAct addresses this need for agents, expanding on the ReAct approach. The ReSpAct framework enables agents to interpret user instructions, reason about complex tasks, execute appropriate actions, and engage in dynamic dialogue to seek guidance, clarify ambiguities, understand user preferences, resolve problems, and use the intermediate feedback and responses of users to update their plans. We evaluated ReSpAct in environments supporting user interaction, such as task-oriented dialogue (MultiWOZ) and interactive decision-making (AlfWorld, WebShop). ReSpAct is flexible enough to incorporate dynamic user feedback and addresses prevalent issues like error propagation and agents getting stuck in reasoning loops. This results in more interpretable, human-like task-solving trajectories than relying solely on reasoning traces. In two interactive decision-making benchmarks, AlfWorld and WebShop, ReSpAct outperform the strong reasoning-only method ReAct by an absolute success rate of 6% and 4%, respectively. In the task-oriented dialogue benchmark MultiWOZ, ReSpAct improved Inform and Success scores by 5.5% and 3%, respectively.
Confidence Estimation for LLM-Based Dialogue State Tracking
Sep 15, 2024



Estimation of a model's confidence on its outputs is critical for Conversational AI systems based on large language models (LLMs), especially for reducing hallucination and preventing over-reliance. In this work, we provide an exhaustive exploration of methods, including approaches proposed for open- and closed-weight LLMs, aimed at quantifying and leveraging model uncertainty to improve the reliability of LLM-generated responses, specifically focusing on dialogue state tracking (DST) in task-oriented dialogue systems (TODS). Regardless of the model type, well-calibrated confidence scores are essential to handle uncertainties, thereby improving model performance. We evaluate four methods for estimating confidence scores based on softmax, raw token scores, verbalized confidences, and a combination of these methods, using the area under the curve (AUC) metric to assess calibration, with higher AUC indicating better calibration. We also enhance these with a self-probing mechanism, proposed for closed models. Furthermore, we assess these methods using an open-weight model fine-tuned for the task of DST, achieving superior joint goal accuracy (JGA). Our findings also suggest that fine-tuning open-weight LLMs can result in enhanced AUC performance, indicating better confidence score calibration.
Towards Generalized and Explainable Long-Range Context Representation for Dialogue Systems
Oct 12, 2022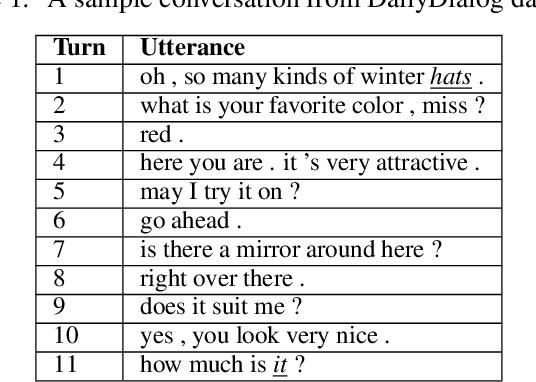


Context representation is crucial to both dialogue understanding and generation. Recently, the most popular method for dialog context representation is to concatenate the last-$k$ previous utterances as context and use a large transformer-based model to generate the next response. However, this method may not be ideal for conversations containing long-range dependencies. In this work, we propose DialoGX, a novel encoder-decoder based framework for conversational response generation with a generalized and explainable context representation that can look beyond the last-$k$ utterances. Hence the method is adaptive to conversations with long-range dependencies. Our proposed solution is based on two key ideas: a) computing a dynamic representation of the entire context, and b) finding the previous utterances that are relevant for generating the next response. Instead of last-$k$ utterances, DialoGX uses the concatenation of the dynamic context vector and encoding of the most relevant utterances as input which enables it to represent conversations of any length in a compact and generalized fashion. We conduct our experiments on DailyDialog, a popular open-domain chit-chat dataset. DialoGX achieves comparable performance with the state-of-the-art models on the automated metrics. We also justify our context representation through the lens of psycholinguistics and show that the relevance score of previous utterances agrees well with human cognition which makes DialoGX explainable as well.
On Text Style Transfer via Style Masked Language Models
Oct 12, 2022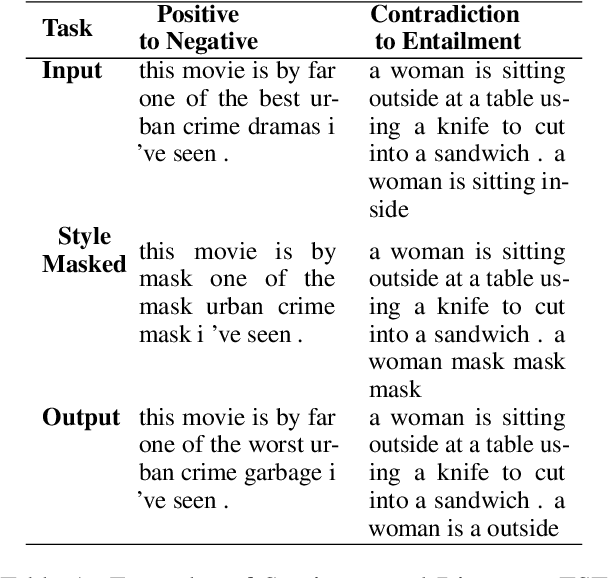
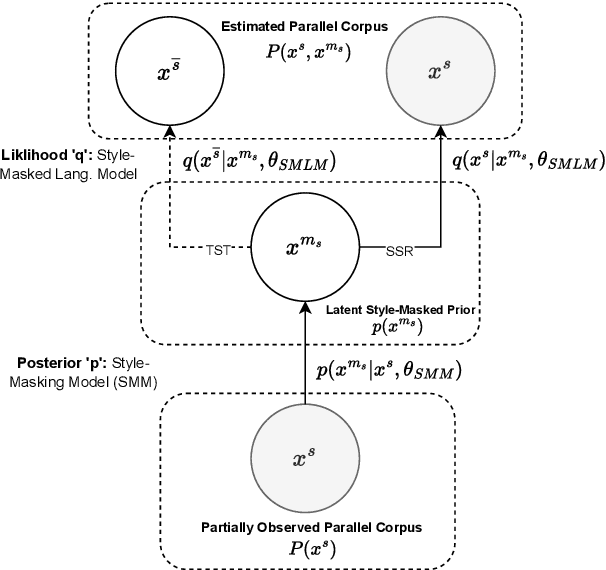

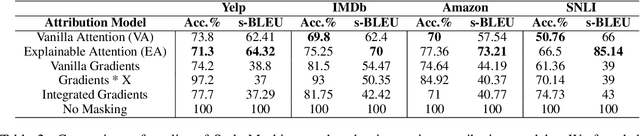
Text Style Transfer (TST) is performable through approaches such as latent space disentanglement, cycle-consistency losses, prototype editing etc. The prototype editing approach, which is known to be quite successful in TST, involves two key phases a) Masking of source style-associated tokens and b) Reconstruction of this source-style masked sentence conditioned with the target style. We follow a similar transduction method, in which we transpose the more difficult direct source to target TST task to a simpler Style-Masked Language Model (SMLM) Task, wherein, similar to BERT \cite{bert}, the goal of our model is now to reconstruct the source sentence from its style-masked version. We arrive at the SMLM mechanism naturally by formulating prototype editing/ transduction methods in a probabilistic framework, where TST resolves into estimating a hypothetical parallel dataset from a partially observed parallel dataset, wherein each domain is assumed to have a common latent style-masked prior. To generate this style-masked prior, we use "Explainable Attention" as our choice of attribution for a more precise style-masking step and also introduce a cost-effective and accurate "Attribution-Surplus" method of determining the position of masks from any arbitrary attribution model in O(1) time. We empirically show that this non-generational approach well suites the "content preserving" criteria for a task like TST, even for a complex style like Discourse Manipulation. Our model, the Style MLM, outperforms strong TST baselines and is on par with state-of-the-art TST models, which use complex architectures and orders of more parameters.
Towards Robust and Semantically Organised Latent Representations for Unsupervised Text Style Transfer
May 04, 2022

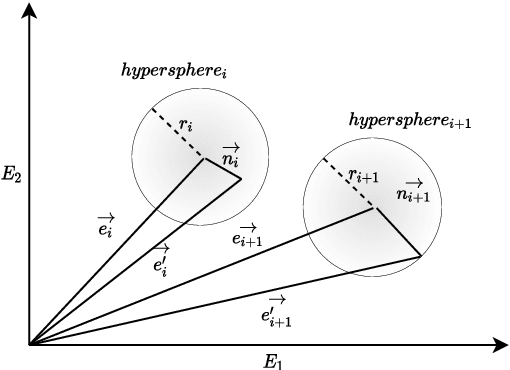
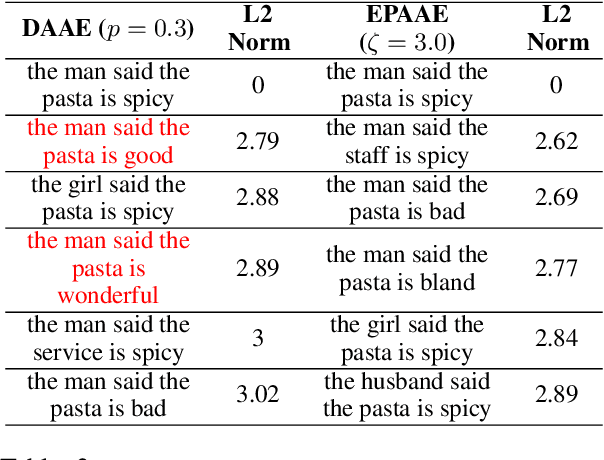
Recent studies show that auto-encoder based approaches successfully perform language generation, smooth sentence interpolation, and style transfer over unseen attributes using unlabelled datasets in a zero-shot manner. The latent space geometry of such models is organised well enough to perform on datasets where the style is "coarse-grained" i.e. a small fraction of words alone in a sentence are enough to determine the overall style label. A recent study uses a discrete token-based perturbation approach to map "similar" sentences ("similar" defined by low Levenshtein distance/ high word overlap) close by in latent space. This definition of "similarity" does not look into the underlying nuances of the constituent words while mapping latent space neighbourhoods and therefore fails to recognise sentences with different style-based semantics while mapping latent neighbourhoods. We introduce EPAAEs (Embedding Perturbed Adversarial AutoEncoders) which completes this perturbation model, by adding a finely adjustable noise component on the continuous embeddings space. We empirically show that this (a) produces a better organised latent space that clusters stylistically similar sentences together, (b) performs best on a diverse set of text style transfer tasks than similar denoising-inspired baselines, and (c) is capable of fine-grained control of Style Transfer strength. We also extend the text style transfer tasks to NLI datasets and show that these more complex definitions of style are learned best by EPAAE. To the best of our knowledge, extending style transfer to NLI tasks has not been explored before.
Towards Fair Evaluation of Dialogue State Tracking by Flexible Incorporation of Turn-level Performances
Apr 07, 2022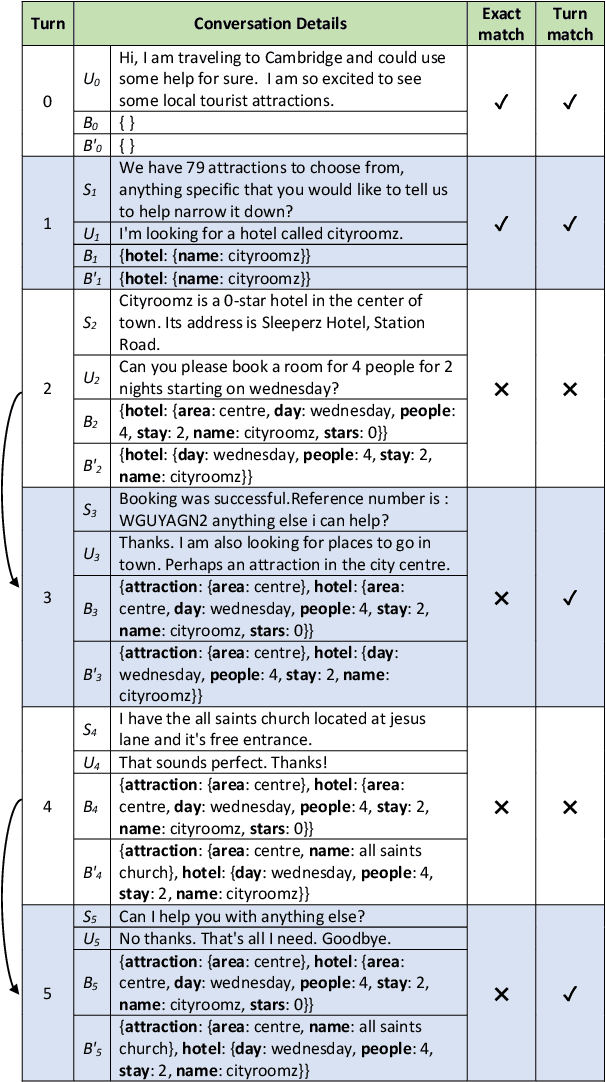

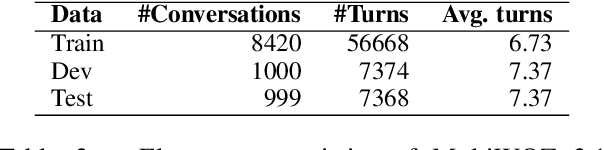

Dialogue State Tracking (DST) is primarily evaluated using Joint Goal Accuracy (JGA) defined as the fraction of turns where the ground-truth dialogue state exactly matches the prediction. Generally in DST, the dialogue state or belief state for a given turn contains all the intents shown by the user till that turn. Due to this cumulative nature of the belief state, it is difficult to get a correct prediction once a misprediction has occurred. Thus, although being a useful metric, it can be harsh at times and underestimate the true potential of a DST model. Moreover, an improvement in JGA can sometimes decrease the performance of turn-level or non-cumulative belief state prediction due to inconsistency in annotations. So, using JGA as the only metric for model selection may not be ideal for all scenarios. In this work, we discuss various evaluation metrics used for DST along with their shortcomings. To address the existing issues, we propose a new evaluation metric named Flexible Goal Accuracy (FGA). FGA is a generalized version of JGA. But unlike JGA, it tries to give penalized rewards to mispredictions that are locally correct i.e. the root cause of the error is an earlier turn. By doing so, FGA considers the performance of both cumulative and turn-level prediction flexibly and provides a better insight than the existing metrics. We also show that FGA is a better discriminator of DST model performance.