 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinked Adapters: Linking Past and Future to Present for Effective Continual Learning
Dec 14, 2024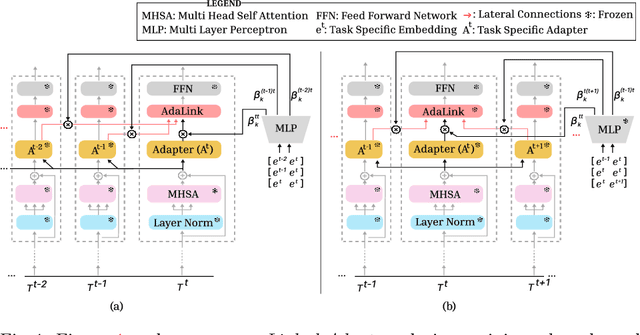
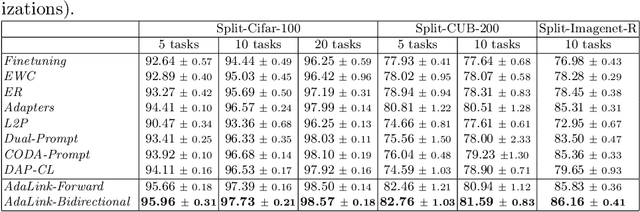

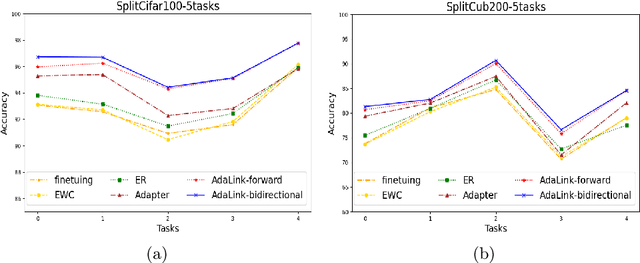
Continual learning allows the system to learn and adapt to new tasks while retaining the knowledge acquired from previous tasks. However, deep learning models suffer from catastrophic forgetting of knowledge learned from earlier tasks while learning a new task. Moreover, retraining large models like transformers from scratch for every new task is costly. An effective approach to address continual learning is to use a large pre-trained model with task-specific adapters to adapt to the new tasks. Though this approach can mitigate catastrophic forgetting, they fail to transfer knowledge across tasks as each task is learning adapters separately. To address this, we propose a novel approach Linked Adapters that allows knowledge transfer through a weighted attention mechanism to other task-specific adapters. Linked adapters use a multi-layer perceptron (MLP) to model the attention weights, which overcomes the challenge of backward knowledge transfer in continual learning in addition to modeling the forward knowledge transfer. During inference, our proposed approach effectively leverages knowledge transfer through MLP-based attention weights across all the lateral task adapters. Through numerous experiments conducted on diverse image classification datasets, we effectively demonstrated the improvement in performance on the continual learning tasks using Linked Adapters.
Transformer based Multitask Learning for Image Captioning and Object Detection
Mar 10, 2024In several real-world scenarios like autonomous navigation and mobility, to obtain a better visual understanding of the surroundings, image captioning and object detection play a crucial role. This work introduces a novel multitask learning framework that combines image captioning and object detection into a joint model. We propose TICOD, Transformer-based Image Captioning and Object detection model for jointly training both tasks by combining the losses obtained from image captioning and object detection networks. By leveraging joint training, the model benefits from the complementary information shared between the two tasks, leading to improved performance for image captioning. Our approach utilizes a transformer-based architecture that enables end-to-end network integration for image captioning and object detection and performs both tasks jointly. We evaluate the effectiveness of our approach through comprehensive experiments on the MS-COCO dataset. Our model outperforms the baselines from image captioning literature by achieving a 3.65% improvement in BERTScore.
Continuous Depth Recurrent Neural Differential Equations
Dec 28, 2022



Recurrent neural networks (RNNs) have brought a lot of advancements in sequence labeling tasks and sequence data. However, their effectiveness is limited when the observations in the sequence are irregularly sampled, where the observations arrive at irregular time intervals. To address this, continuous time variants of the RNNs were introduced based on neural ordinary differential equations (NODE). They learn a better representation of the data using the continuous transformation of hidden states over time, taking into account the time interval between the observations. However, they are still limited in their capability as they use the discrete transformations and a fixed discrete number of layers (depth) over an input in the sequence to produce the output observation. We intend to address this limitation by proposing RNNs based on differential equations which model continuous transformations over both depth and time to predict an output for a given input in the sequence. Specifically, we propose continuous depth recurrent neural differential equations (CDR-NDE) which generalizes RNN models by continuously evolving the hidden states in both the temporal and depth dimensions. CDR-NDE considers two separate differential equations over each of these dimensions and models the evolution in the temporal and depth directions alternatively. We also propose the CDR-NDE-heat model based on partial differential equations which treats the computation of hidden states as solving a heat equation over time. We demonstrate the effectiveness of the proposed models by comparing against the state-of-the-art RNN models on real world sequence labeling problems and data.
Towards Generalized and Explainable Long-Range Context Representation for Dialogue Systems
Oct 12, 2022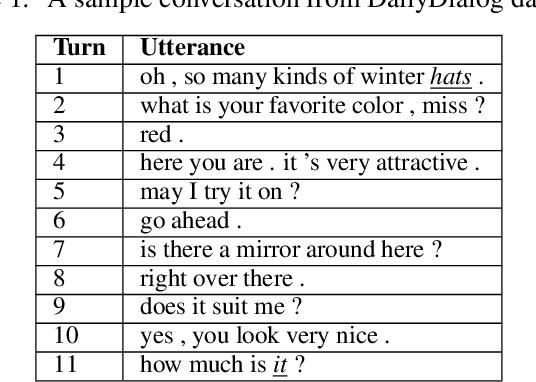


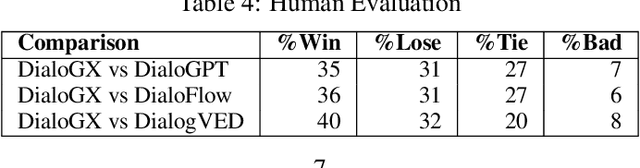
Context representation is crucial to both dialogue understanding and generation. Recently, the most popular method for dialog context representation is to concatenate the last-$k$ previous utterances as context and use a large transformer-based model to generate the next response. However, this method may not be ideal for conversations containing long-range dependencies. In this work, we propose DialoGX, a novel encoder-decoder based framework for conversational response generation with a generalized and explainable context representation that can look beyond the last-$k$ utterances. Hence the method is adaptive to conversations with long-range dependencies. Our proposed solution is based on two key ideas: a) computing a dynamic representation of the entire context, and b) finding the previous utterances that are relevant for generating the next response. Instead of last-$k$ utterances, DialoGX uses the concatenation of the dynamic context vector and encoding of the most relevant utterances as input which enables it to represent conversations of any length in a compact and generalized fashion. We conduct our experiments on DailyDialog, a popular open-domain chit-chat dataset. DialoGX achieves comparable performance with the state-of-the-art models on the automated metrics. We also justify our context representation through the lens of psycholinguistics and show that the relevance score of previous utterances agrees well with human cognition which makes DialoGX explainable as well.
HyperHawkes: Hypernetwork based Neural Temporal Point Process
Oct 01, 2022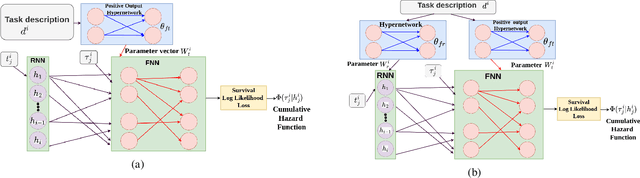


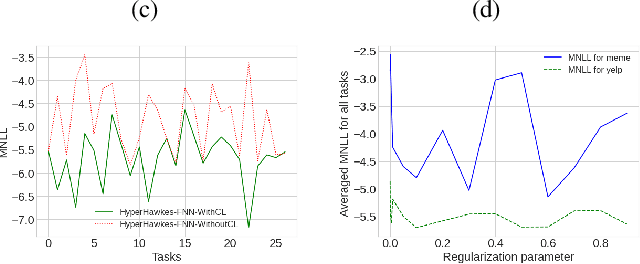
Temporal point process serves as an essential tool for modeling time-to-event data in continuous time space. Despite having massive amounts of event sequence data from various domains like social media, healthcare etc., real world application of temporal point process faces two major challenges: 1) it is not generalizable to predict events from unseen sequences in dynamic environment 2) they are not capable of thriving in continually evolving environment with minimal supervision while retaining previously learnt knowledge. To tackle these issues, we propose \textit{HyperHawkes}, a hypernetwork based temporal point process framework which is capable of modeling time of occurrence of events for unseen sequences. Thereby, we solve the problem of zero-shot learning for time-to-event modeling. We also develop a hypernetwork based continually learning temporal point process for continuous modeling of time-to-event sequences with minimal forgetting. In this way, \textit{HyperHawkes} augments the temporal point process with zero-shot modeling and continual learning capabilities. We demonstrate the application of the proposed framework through our experiments on two real-world datasets. Our results show the efficacy of the proposed approach in terms of predicting future events under zero-shot regime for unseen event sequences. We also show that the proposed model is able to predict sequences continually while retaining information from previous event sequences, hence mitigating catastrophic forgetting for time-to-event data.
Continual Learning with Dependency Preserving Hypernetworks
Sep 16, 2022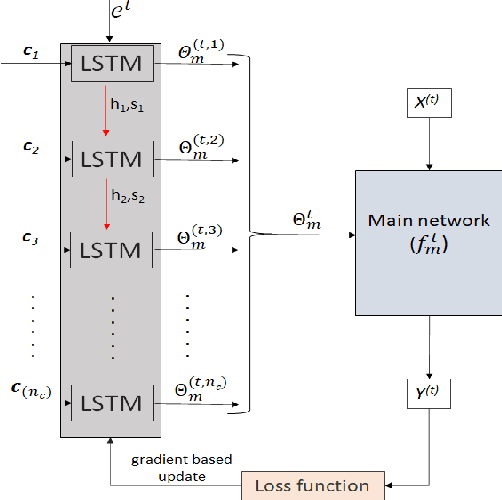
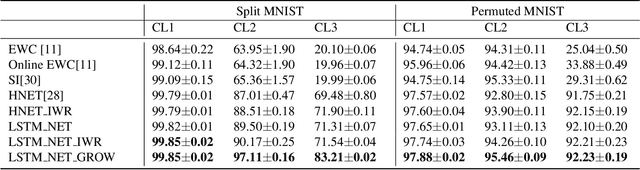
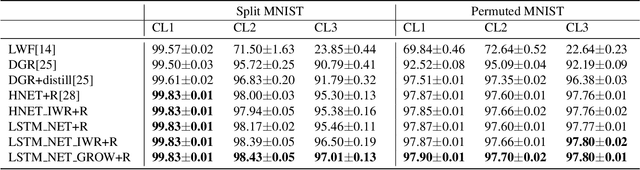
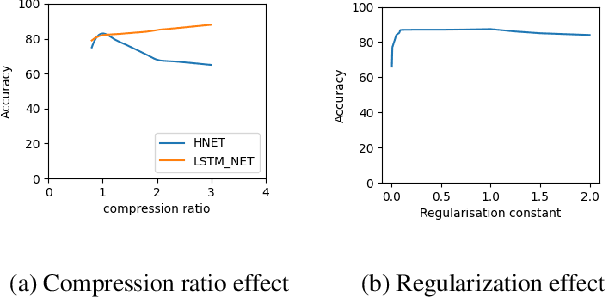
Humans learn continually throughout their lifespan by accumulating diverse knowledge and fine-tuning it for future tasks. When presented with a similar goal, neural networks suffer from catastrophic forgetting if data distributions across sequential tasks are not stationary over the course of learning. An effective approach to address such continual learning (CL) problems is to use hypernetworks which generate task dependent weights for a target network. However, the continual learning performance of existing hypernetwork based approaches are affected by the assumption of independence of the weights across the layers in order to maintain parameter efficiency. To address this limitation, we propose a novel approach that uses a dependency preserving hypernetwork to generate weights for the target network while also maintaining the parameter efficiency. We propose to use recurrent neural network (RNN) based hypernetwork that can generate layer weights efficiently while allowing for dependencies across them. In addition, we propose novel regularisation and network growth techniques for the RNN based hypernetwork to further improve the continual learning performance. To demonstrate the effectiveness of the proposed methods, we conducted experiments on several image classification continual learning tasks and settings. We found that the proposed methods based on the RNN hypernetworks outperformed the baselines in all these CL settings and tasks.
Bayesian Neural Hawkes Process for Event Uncertainty Prediction
Jan 19, 2022



Event data consisting of time of occurrence of the events arises in several real-world applications. Recent works have introduced neural network based point processes for modeling event-times, and were shown to provide state-of-the-art performance in predicting event-times. However, neural point process models lack a good uncertainty quantification capability on predictions. A proper uncertainty quantification over event modeling will help in better decision making for many practical applications. Therefore, we propose a novel point process model, Bayesian Neural Hawkes process (BNHP) which leverages uncertainty modelling capability of Bayesian models and generalization capability of the neural networks to model event occurrence times. We augment the model with spatio-temporal modeling capability where it can consider uncertainty over predicted time and location of the events. Experiments on simulated and real-world datasets show that BNHP significantly improves prediction performance and uncertainty quantification for modelling events.
Bi-Directional Recurrent Neural Ordinary Differential Equations for Social Media Text Classification
Dec 23, 2021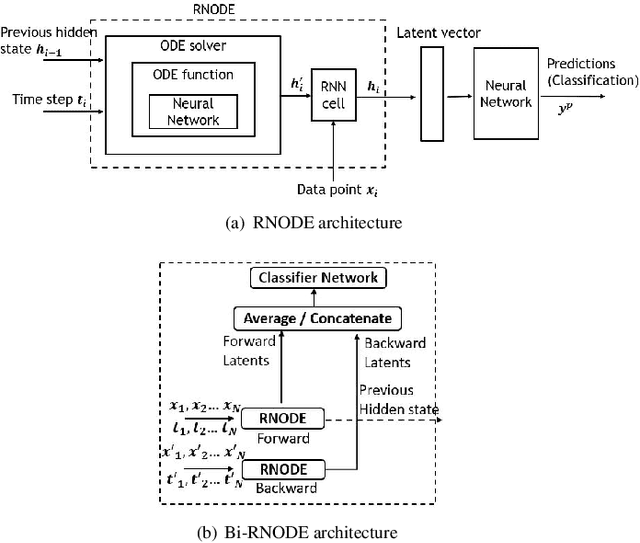
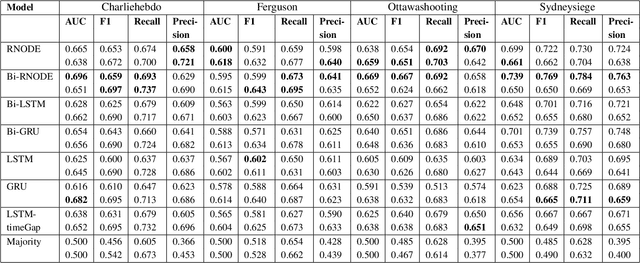
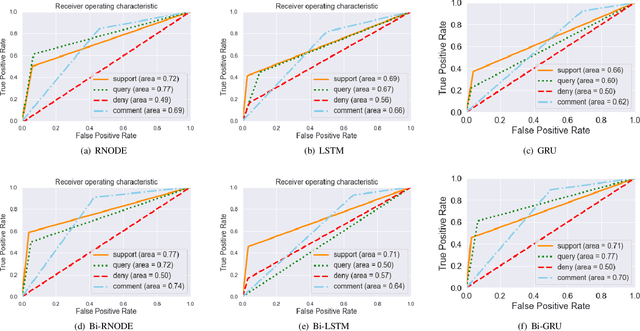
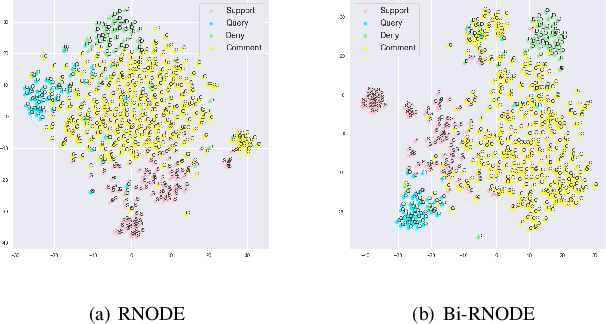
Classification of posts in social media such as Twitter is difficult due to the noisy and short nature of texts. Sequence classification models based on recurrent neural networks (RNN) are popular for classifying posts that are sequential in nature. RNNs assume the hidden representation dynamics to evolve in a discrete manner and do not consider the exact time of the posting. In this work, we propose to use recurrent neural ordinary differential equations (RNODE) for social media post classification which consider the time of posting and allow the computation of hidden representation to evolve in a time-sensitive continuous manner. In addition, we propose a novel model, Bi-directional RNODE (Bi-RNODE), which can consider the information flow in both the forward and backward directions of posting times to predict the post label. Our experiments demonstrate that RNODE and Bi-RNODE are effective for the problem of stance classification of rumours in social media.
Latent Time Neural Ordinary Differential Equations
Dec 23, 2021
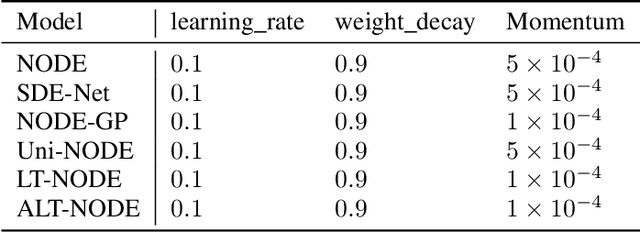


Neural ordinary differential equations (NODE) have been proposed as a continuous depth generalization to popular deep learning models such as Residual networks (ResNets). They provide parameter efficiency and automate the model selection process in deep learning models to some extent. However, they lack the much-required uncertainty modelling and robustness capabilities which are crucial for their use in several real-world applications such as autonomous driving and healthcare. We propose a novel and unique approach to model uncertainty in NODE by considering a distribution over the end-time $T$ of the ODE solver. The proposed approach, latent time NODE (LT-NODE), treats $T$ as a latent variable and apply Bayesian learning to obtain a posterior distribution over $T$ from the data. In particular, we use variational inference to learn an approximate posterior and the model parameters. Prediction is done by considering the NODE representations from different samples of the posterior and can be done efficiently using a single forward pass. As $T$ implicitly defines the depth of a NODE, posterior distribution over $T$ would also help in model selection in NODE. We also propose, adaptive latent time NODE (ALT-NODE), which allow each data point to have a distinct posterior distribution over end-times. ALT-NODE uses amortized variational inference to learn an approximate posterior using inference networks. We demonstrate the effectiveness of the proposed approaches in modelling uncertainty and robustness through experiments on synthetic and several real-world image classification data.
Improving Robustness and Uncertainty Modelling in Neural Ordinary Differential Equations
Dec 23, 2021

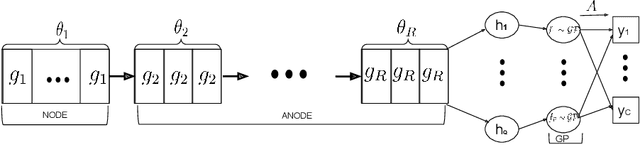

Neural ordinary differential equations (NODE) have been proposed as a continuous depth generalization to popular deep learning models such as Residual networks (ResNets). They provide parameter efficiency and automate the model selection process in deep learning models to some extent. However, they lack the much-required uncertainty modelling and robustness capabilities which are crucial for their use in several real-world applications such as autonomous driving and healthcare. We propose a novel and unique approach to model uncertainty in NODE by considering a distribution over the end-time $T$ of the ODE solver. The proposed approach, latent time NODE (LT-NODE), treats $T$ as a latent variable and apply Bayesian learning to obtain a posterior distribution over $T$ from the data. In particular, we use variational inference to learn an approximate posterior and the model parameters. Prediction is done by considering the NODE representations from different samples of the posterior and can be done efficiently using a single forward pass. As $T$ implicitly defines the depth of a NODE, posterior distribution over $T$ would also help in model selection in NODE. We also propose, adaptive latent time NODE (ALT-NODE), which allow each data point to have a distinct posterior distribution over end-times. ALT-NODE uses amortized variational inference to learn an approximate posterior using inference networks. We demonstrate the effectiveness of the proposed approaches in modelling uncertainty and robustness through experiments on synthetic and several real-world image classification data.
* Winter Conference on Applications of Computer Vision, 2021