 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Dependency Preserving Hypernetworks
Sep 16, 2022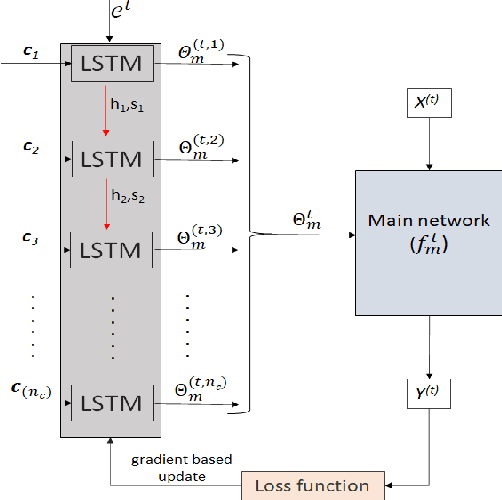
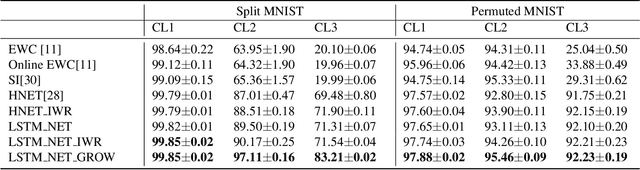
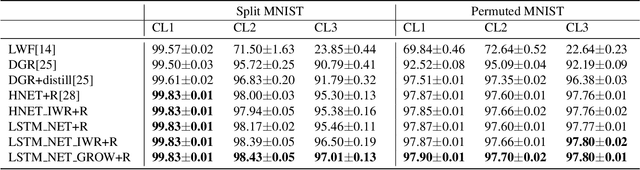
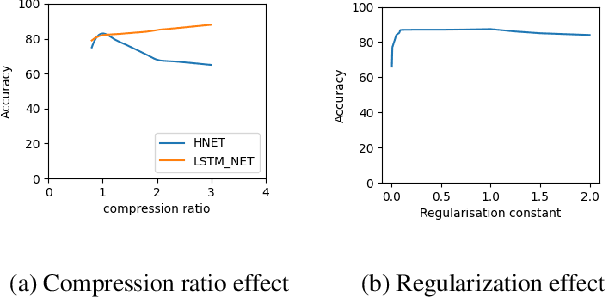
Humans learn continually throughout their lifespan by accumulating diverse knowledge and fine-tuning it for future tasks. When presented with a similar goal, neural networks suffer from catastrophic forgetting if data distributions across sequential tasks are not stationary over the course of learning. An effective approach to address such continual learning (CL) problems is to use hypernetworks which generate task dependent weights for a target network. However, the continual learning performance of existing hypernetwork based approaches are affected by the assumption of independence of the weights across the layers in order to maintain parameter efficiency. To address this limitation, we propose a novel approach that uses a dependency preserving hypernetwork to generate weights for the target network while also maintaining the parameter efficiency. We propose to use recurrent neural network (RNN) based hypernetwork that can generate layer weights efficiently while allowing for dependencies across them. In addition, we propose novel regularisation and network growth techniques for the RNN based hypernetwork to further improve the continual learning performance. To demonstrate the effectiveness of the proposed methods, we conducted experiments on several image classification continual learning tasks and settings. We found that the proposed methods based on the RNN hypernetworks outperformed the baselines in all these CL settings and tasks.
Efficient Continual Adaptation for Generative Adversarial Networks
Mar 06, 2021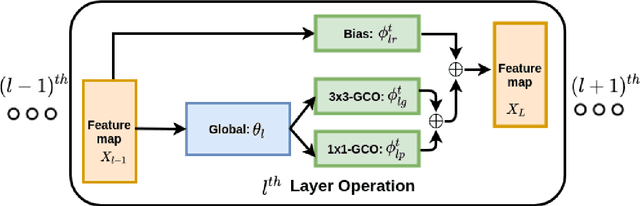

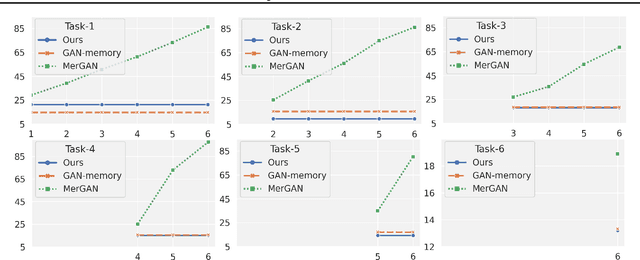

We present a continual learning approach for generative adversarial networks (GANs), by designing and leveraging parameter-efficient feature map transformations. Our approach is based on learning a set of global and task-specific parameters. The global parameters are fixed across tasks whereas the task specific parameters act as local adapters for each task, and help in efficiently transforming the previous task's feature map to the new task's feature map. Moreover, we propose an element-wise residual bias in the transformed feature space which highly stabilizes GAN training. In contrast to the recent approaches for continual GANs, we do not rely on memory replay, regularization towards previous tasks' parameters, or expensive weight transformations. Through extensive experiments on challenging and diverse datasets, we show that the feature-map transformation based approach outperforms state-of-the-art continual GANs methods, with substantially fewer parameters, and also generates high-quality samples that can be used in generative replay based continual learning of discriminative tasks.
AdvGAN++ : Harnessing latent layers for adversary generation
Aug 02, 2019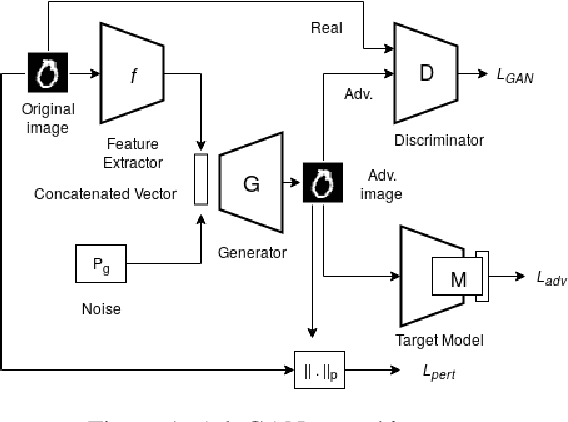
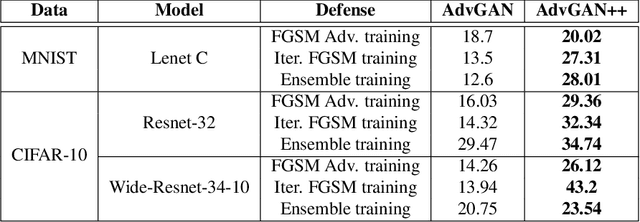
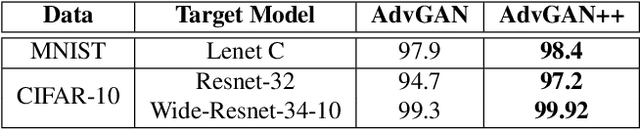

Adversarial examples are fabricated examples, indistinguishable from the original image that mislead neural networks and drastically lower their performance. Recently proposed AdvGAN, a GAN based approach, takes input image as a prior for generating adversaries to target a model. In this work, we show how latent features can serve as better priors than input images for adversary generation by proposing AdvGAN++, a version of AdvGAN that achieves higher attack rates than AdvGAN and at the same time generates perceptually realistic images on MNIST and CIFAR-10 datasets.