 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCUS: Forcing In-Context Object Localization through Visual Support Constraints and Policy Optimization
May 29, 2026In-context localization (ICL) seeks to localize a target object specified by a small set of support examples in a query image, operating on the fly without training or parameter updates. Despite rapid advances in vision-language models (VLMs), achieving category-agnostic and visually grounded ICL remains an open problem, even though it is essential for applications such as image editing, personalized visual search, and retrieval. Existing methods are fragile and rely on explicit category supervision, which not only limits applicability in realistic settings with unnamed or instance-specific objects but also introduces category bias that steers predictions toward semantic priors rather than visual evidence. We introduce a two-stage training framework that explicitly optimizes in-context attention between support bounding boxes and query images without category supervision. We further refine localization via reinforcement learning using Group Relative Policy Optimization (GRPO) to directly minimize localization error. This formulation enforces visual correspondence over semantic priors, yielding robust instance-level localization. Empirically, a 7B-parameter model trained with our objectives outperforms models up to 72B parameters, demonstrating that context-aware localization objectives can surpass scaling alone. Comprehensive ablations validate the contribution of each component.
Efficient Text-Guided Convolutional Adapter for the Diffusion Model
Feb 16, 2026We introduce the Nexus Adapters, novel text-guided efficient adapters to the diffusion-based framework for the Structure Preserving Conditional Generation (SPCG). Recently, structure-preserving methods have achieved promising results in conditional image generation by using a base model for prompt conditioning and an adapter for structure input, such as sketches or depth maps. These approaches are highly inefficient and sometimes require equal parameters in the adapter compared to the base architecture. It is not always possible to train the model since the diffusion model is itself costly, and doubling the parameter is highly inefficient. In these approaches, the adapter is not aware of the input prompt; therefore, it is optimal only for the structural input but not for the input prompt. To overcome the above challenges, we proposed two efficient adapters, Nexus Prime and Slim, which are guided by prompts and structural inputs. Each Nexus Block incorporates cross-attention mechanisms to enable rich multimodal conditioning. Therefore, the proposed adapter has a better understanding of the input prompt while preserving the structure. We conducted extensive experiments on the proposed models and demonstrated that the Nexus Prime adapter significantly enhances performance, requiring only 8M additional parameters compared to the baseline, T2I-Adapter. Furthermore, we also introduced a lightweight Nexus Slim adapter with 18M fewer parameters than the T2I-Adapter, which still achieved state-of-the-art results. Code: https://github.com/arya-domain/Nexus-Adapters
Uncertainty-Aware Vision-Language Segmentation for Medical Imaging
Feb 16, 2026We introduce a novel uncertainty-aware multimodal segmentation framework that leverages both radiological images and associated clinical text for precise medical diagnosis. We propose a Modality Decoding Attention Block (MoDAB) with a lightweight State Space Mixer (SSMix) to enable efficient cross-modal fusion and long-range dependency modelling. To guide learning under ambiguity, we propose the Spectral-Entropic Uncertainty (SEU) Loss, which jointly captures spatial overlap, spectral consistency, and predictive uncertainty in a unified objective. In complex clinical circumstances with poor image quality, this formulation improves model reliability. Extensive experiments on various publicly available medical datasets, QATA-COVID19, MosMed++, and Kvasir-SEG, demonstrate that our method achieves superior segmentation performance while being significantly more computationally efficient than existing State-of-the-Art (SoTA) approaches. Our results highlight the importance of incorporating uncertainty modelling and structured modality alignment in vision-language medical segmentation tasks. Code: https://github.com/arya-domain/UA-VLS
Hyperspectral Image Land Cover Captioning Dataset for Vision Language Models
May 18, 2025We introduce HyperCap, the first large-scale hyperspectral captioning dataset designed to enhance model performance and effectiveness in remote sensing applications. Unlike traditional hyperspectral imaging (HSI) datasets that focus solely on classification tasks, HyperCap integrates spectral data with pixel-wise textual annotations, enabling deeper semantic understanding of hyperspectral imagery. This dataset enhances model performance in tasks like classification and feature extraction, providing a valuable resource for advanced remote sensing applications. HyperCap is constructed from four benchmark datasets and annotated through a hybrid approach combining automated and manual methods to ensure accuracy and consistency. Empirical evaluations using state-of-the-art encoders and diverse fusion techniques demonstrate significant improvements in classification performance. These results underscore the potential of vision-language learning in HSI and position HyperCap as a foundational dataset for future research in the field.
ADROIT: A Self-Supervised Framework for Learning Robust Representations for Active Learning
Mar 10, 2025



Active learning aims to select optimal samples for labeling, minimizing annotation costs. This paper introduces a unified representation learning framework tailored for active learning with task awareness. It integrates diverse sources, comprising reconstruction, adversarial, self-supervised, knowledge-distillation, and classification losses into a unified VAE-based ADROIT approach. The proposed approach comprises three key components - a unified representation generator (VAE), a state discriminator, and a (proxy) task-learner or classifier. ADROIT learns a latent code using both labeled and unlabeled data, incorporating task-awareness by leveraging labeled data with the proxy classifier. Unlike previous approaches, the proxy classifier additionally employs a self-supervised loss on unlabeled data and utilizes knowledge distillation to align with the target task-learner. The state discriminator distinguishes between labeled and unlabeled data, facilitating the selection of informative unlabeled samples. The dynamic interaction between VAE and the state discriminator creates a competitive environment, with the VAE attempting to deceive the discriminator, while the state discriminator learns to differentiate between labeled and unlabeled inputs. Extensive evaluations on diverse datasets and ablation analysis affirm the effectiveness of the proposed model.
MoEMoE: Question Guided Dense and Scalable Sparse Mixture-of-Expert for Multi-source Multi-modal Answering
Mar 08, 2025Question Answering (QA) and Visual Question Answering (VQA) are well-studied problems in the language and vision domain. One challenging scenario involves multiple sources of information, each of a different modality, where the answer to the question may exist in one or more sources. This scenario contains richer information but is highly complex to handle. In this work, we formulate a novel question-answer generation (QAG) framework in an environment containing multi-source, multimodal information. The answer may belong to any or all sources; therefore, selecting the most prominent answer source or an optimal combination of all sources for a given question is challenging. To address this issue, we propose a question-guided attention mechanism that learns attention across multiple sources and decodes this information for robust and unbiased answer generation. To learn attention within each source, we introduce an explicit alignment between questions and various information sources, which facilitates identifying the most pertinent parts of the source information relative to the question. Scalability in handling diverse questions poses a challenge. We address this by extending our model to a sparse mixture-of-experts (sparse-MoE) framework, enabling it to handle thousands of question types. Experiments on T5 and Flan-T5 using three datasets demonstrate the model's efficacy, supported by ablation studies.
Exemplar-Free Continual Transformer with Convolutions
Aug 22, 2023



Continual Learning (CL) involves training a machine learning model in a sequential manner to learn new information while retaining previously learned tasks without the presence of previous training data. Although there has been significant interest in CL, most recent CL approaches in computer vision have focused on convolutional architectures only. However, with the recent success of vision transformers, there is a need to explore their potential for CL. Although there have been some recent CL approaches for vision transformers, they either store training instances of previous tasks or require a task identifier during test time, which can be limiting. This paper proposes a new exemplar-free approach for class/task incremental learning called ConTraCon, which does not require task-id to be explicitly present during inference and avoids the need for storing previous training instances. The proposed approach leverages the transformer architecture and involves re-weighting the key, query, and value weights of the multi-head self-attention layers of a transformer trained on a similar task. The re-weighting is done using convolution, which enables the approach to maintain low parameter requirements per task. Additionally, an image augmentation-based entropic task identification approach is used to predict tasks without requiring task-ids during inference. Experiments on four benchmark datasets demonstrate that the proposed approach outperforms several competitive approaches while requiring fewer parameters.
Streaming LifeLong Learning With Any-Time Inference
Jan 27, 2023Despite rapid advancements in lifelong learning (LLL) research, a large body of research mainly focuses on improving the performance in the existing \textit{static} continual learning (CL) setups. These methods lack the ability to succeed in a rapidly changing \textit{dynamic} environment, where an AI agent needs to quickly learn new instances in a `single pass' from the non-i.i.d (also possibly temporally contiguous/coherent) data streams without suffering from catastrophic forgetting. For practical applicability, we propose a novel lifelong learning approach, which is streaming, i.e., a single input sample arrives in each time step, single pass, class-incremental, and subject to be evaluated at any moment. To address this challenging setup and various evaluation protocols, we propose a Bayesian framework, that enables fast parameter update, given a single training example, and enables any-time inference. We additionally propose an implicit regularizer in the form of snap-shot self-distillation, which effectively minimizes the forgetting further. We further propose an effective method that efficiently selects a subset of samples for online memory rehearsal and employs a new replay buffer management scheme that significantly boosts the overall performance. Our empirical evaluations and ablations demonstrate that the proposed method outperforms the prior works by large margins.
Pushing the Efficiency Limit Using Structured Sparse Convolutions
Oct 23, 2022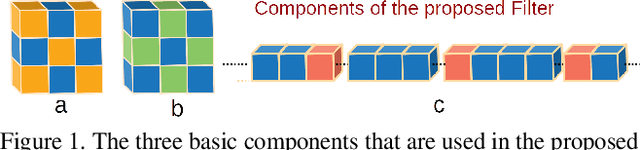
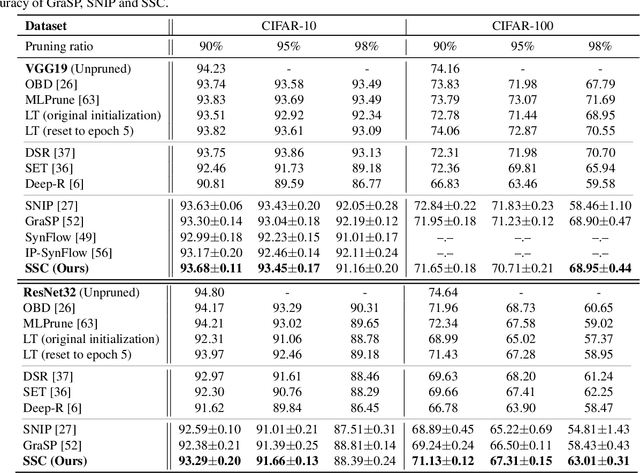
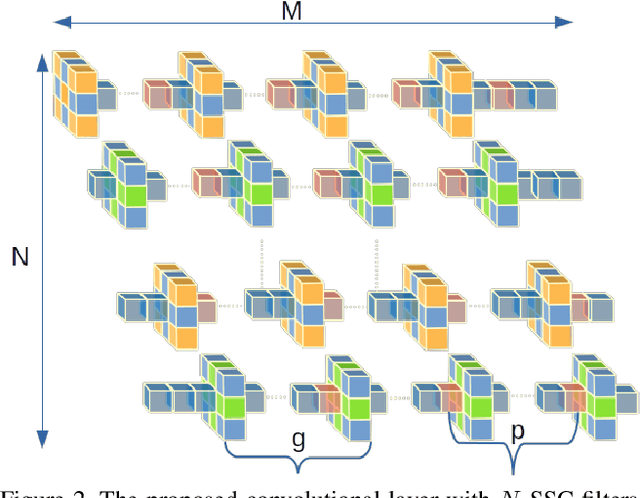
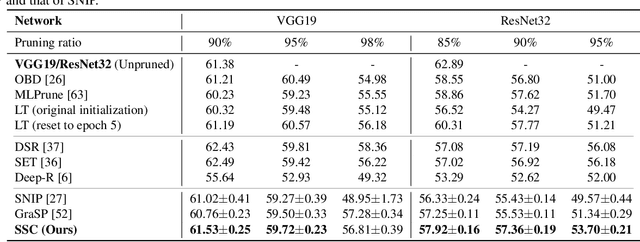
Weight pruning is among the most popular approaches for compressing deep convolutional neural networks. Recent work suggests that in a randomly initialized deep neural network, there exist sparse subnetworks that achieve performance comparable to the original network. Unfortunately, finding these subnetworks involves iterative stages of training and pruning, which can be computationally expensive. We propose Structured Sparse Convolution (SSC), which leverages the inherent structure in images to reduce the parameters in the convolutional filter. This leads to improved efficiency of convolutional architectures compared to existing methods that perform pruning at initialization. We show that SSC is a generalization of commonly used layers (depthwise, groupwise and pointwise convolution) in ``efficient architectures.'' Extensive experiments on well-known CNN models and datasets show the effectiveness of the proposed method. Architectures based on SSC achieve state-of-the-art performance compared to baselines on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet classification benchmarks.
Class Incremental Online Streaming Learning
Oct 20, 2021
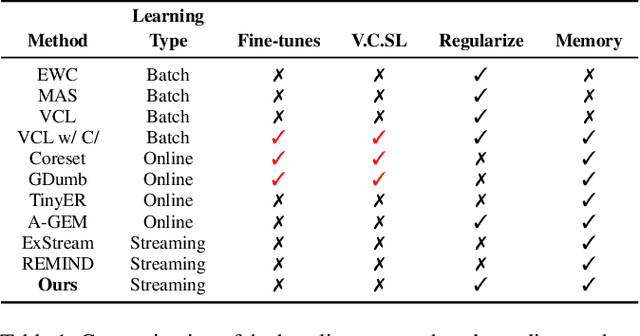

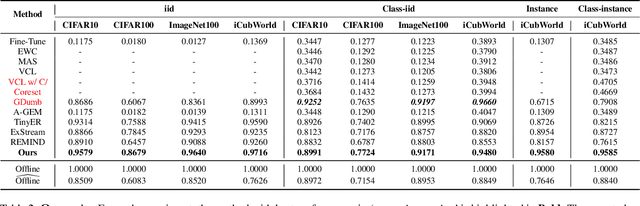
A wide variety of methods have been developed to enable lifelong learning in conventional deep neural networks. However, to succeed, these methods require a `batch' of samples to be available and visited multiple times during training. While this works well in a static setting, these methods continue to suffer in a more realistic situation where data arrives in \emph{online streaming manner}. We empirically demonstrate that the performance of current approaches degrades if the input is obtained as a stream of data with the following restrictions: $(i)$ each instance comes one at a time and can be seen only once, and $(ii)$ the input data violates the i.i.d assumption, i.e., there can be a class-based correlation. We propose a novel approach (CIOSL) for the class-incremental learning in an \emph{online streaming setting} to address these challenges. The proposed approach leverages implicit and explicit dual weight regularization and experience replay. The implicit regularization is leveraged via the knowledge distillation, while the explicit regularization incorporates a novel approach for parameter regularization by learning the joint distribution of the buffer replay and the current sample. Also, we propose an efficient online memory replay and replacement buffer strategy that significantly boosts the model's performance. Extensive experiments and ablation on challenging datasets show the efficacy of the proposed method.