 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA-BED: Conversation-Aware Bayesian Experimental Design
May 31, 2026Large Language Models (LLMs) excel at static reasoning tasks, yet their performance often degrades in interactive scenarios where information must be actively acquired through questioning. A key challenge lies in selecting questions that reduce uncertainty while incorporating responses that may be ambiguous or only partially informative. To address this, we propose Conversation-Aware Bayesian Experimental Design (CA-BED), an inference-time probabilistic dialog planning framework that integrates Bayesian Experimental Design with LLM-based likelihood estimation to optimize question selection over multiple conversational turns. CA-BED maintains a belief distribution over hypotheses, anticipates possible answers, and propagates expected information gain through a simulated conversation tree. Across two structured entity-deduction benchmarks, CA-BED yields an average 21.8% improvement in success rates over direct prompting, with comparable gains relative to alternative information-seeking methods. It achieves these gains with an average increase of only 1.8 conversational turns compared to direct prompting.
MoEMoE: Question Guided Dense and Scalable Sparse Mixture-of-Expert for Multi-source Multi-modal Answering
Mar 08, 2025Question Answering (QA) and Visual Question Answering (VQA) are well-studied problems in the language and vision domain. One challenging scenario involves multiple sources of information, each of a different modality, where the answer to the question may exist in one or more sources. This scenario contains richer information but is highly complex to handle. In this work, we formulate a novel question-answer generation (QAG) framework in an environment containing multi-source, multimodal information. The answer may belong to any or all sources; therefore, selecting the most prominent answer source or an optimal combination of all sources for a given question is challenging. To address this issue, we propose a question-guided attention mechanism that learns attention across multiple sources and decodes this information for robust and unbiased answer generation. To learn attention within each source, we introduce an explicit alignment between questions and various information sources, which facilitates identifying the most pertinent parts of the source information relative to the question. Scalability in handling diverse questions poses a challenge. We address this by extending our model to a sparse mixture-of-experts (sparse-MoE) framework, enabling it to handle thousands of question types. Experiments on T5 and Flan-T5 using three datasets demonstrate the model's efficacy, supported by ablation studies.
Large Scale Generative Multimodal Attribute Extraction for E-commerce Attributes
Jun 01, 2023E-commerce websites (e.g. Amazon) have a plethora of structured and unstructured information (text and images) present on the product pages. Sellers often either don't label or mislabel values of the attributes (e.g. color, size etc.) for their products. Automatically identifying these attribute values from an eCommerce product page that contains both text and images is a challenging task, especially when the attribute value is not explicitly mentioned in the catalog. In this paper, we present a scalable solution for this problem where we pose attribute extraction problem as a question-answering task, which we solve using \textbf{MXT}, consisting of three key components: (i) \textbf{M}AG (Multimodal Adaptation Gate), (ii) \textbf{X}ception network, and (iii) \textbf{T}5 encoder-decoder. Our system consists of a generative model that \emph{generates} attribute-values for a given product by using both textual and visual characteristics (e.g. images) of the product. We show that our system is capable of handling zero-shot attribute prediction (when attribute value is not seen in training data) and value-absent prediction (when attribute value is not mentioned in the text) which are missing in traditional classification-based and NER-based models respectively. We have trained our models using distant supervision, removing dependency on human labeling, thus making them practical for real-world applications. With this framework, we are able to train a single model for 1000s of (product-type, attribute) pairs, thus reducing the overhead of training and maintaining separate models. Extensive experiments on two real world datasets show that our framework improves the absolute recall@90P by 10.16\% and 6.9\% from the existing state of the art models. In a popular e-commerce store, we have deployed our models for 1000s of (product-type, attribute) pairs.
Transformer-based Flood Scene Segmentation for Developing Countries
Oct 09, 2022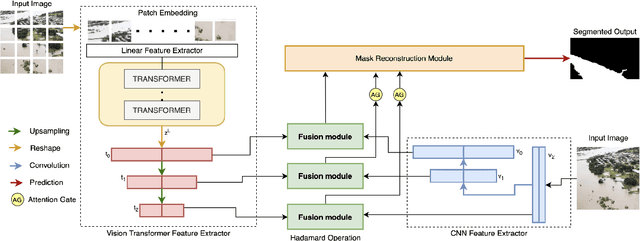
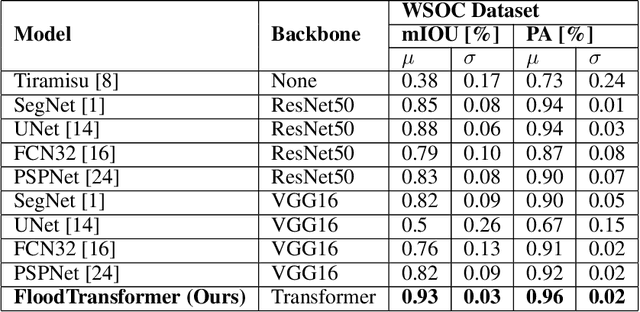


Floods are large-scale natural disasters that often induce a massive number of deaths, extensive material damage, and economic turmoil. The effects are more extensive and longer-lasting in high-population and low-resource developing countries. Early Warning Systems (EWS) constantly assess water levels and other factors to forecast floods, to help minimize damage. Post-disaster, disaster response teams undertake a Post Disaster Needs Assessment (PDSA) to assess structural damage and determine optimal strategies to respond to highly affected neighbourhoods. However, even today in developing countries, EWS and PDSA analysis of large volumes of image and video data is largely a manual process undertaken by first responders and volunteers. We propose FloodTransformer, which to the best of our knowledge, is the first visual transformer-based model to detect and segment flooded areas from aerial images at disaster sites. We also propose a custom metric, Flood Capacity (FC) to measure the spatial extent of water coverage and quantify the segmented flooded area for EWS and PDSA analyses. We use the SWOC Flood segmentation dataset and achieve 0.93 mIoU, outperforming all other methods. We further show the robustness of this approach by validating across unseen flood images from other flood data sources.
End-to-End Code Switching Language Models for Automatic Speech Recognition
Jun 16, 2020
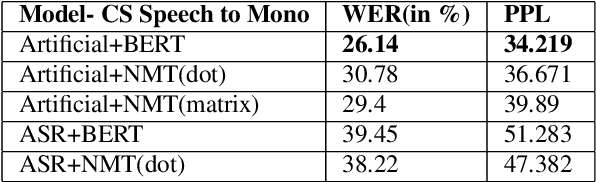

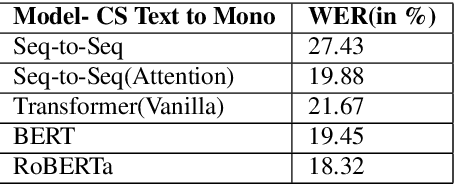
In this paper, we particularly work on the code-switched text, one of the most common occurrences in the bilingual communities across the world. Due to the discrepancies in the extraction of code-switched text from an Automated Speech Recognition(ASR) module, and thereby extracting the monolingual text from the code-switched text, we propose an approach for extracting monolingual text using Deep Bi-directional Language Models(LM) such as BERT and other Machine Translation models, and also explore different ways of extracting code-switched text from the ASR model. We also explain the robustness of the model by comparing the results of Perplexity and other different metrics like WER, to the standard bi-lingual text output without any external information.