 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEMoE: Question Guided Dense and Scalable Sparse Mixture-of-Expert for Multi-source Multi-modal Answering
Mar 08, 2025Question Answering (QA) and Visual Question Answering (VQA) are well-studied problems in the language and vision domain. One challenging scenario involves multiple sources of information, each of a different modality, where the answer to the question may exist in one or more sources. This scenario contains richer information but is highly complex to handle. In this work, we formulate a novel question-answer generation (QAG) framework in an environment containing multi-source, multimodal information. The answer may belong to any or all sources; therefore, selecting the most prominent answer source or an optimal combination of all sources for a given question is challenging. To address this issue, we propose a question-guided attention mechanism that learns attention across multiple sources and decodes this information for robust and unbiased answer generation. To learn attention within each source, we introduce an explicit alignment between questions and various information sources, which facilitates identifying the most pertinent parts of the source information relative to the question. Scalability in handling diverse questions poses a challenge. We address this by extending our model to a sparse mixture-of-experts (sparse-MoE) framework, enabling it to handle thousands of question types. Experiments on T5 and Flan-T5 using three datasets demonstrate the model's efficacy, supported by ablation studies.
Large Scale Generative Multimodal Attribute Extraction for E-commerce Attributes
Jun 01, 2023E-commerce websites (e.g. Amazon) have a plethora of structured and unstructured information (text and images) present on the product pages. Sellers often either don't label or mislabel values of the attributes (e.g. color, size etc.) for their products. Automatically identifying these attribute values from an eCommerce product page that contains both text and images is a challenging task, especially when the attribute value is not explicitly mentioned in the catalog. In this paper, we present a scalable solution for this problem where we pose attribute extraction problem as a question-answering task, which we solve using \textbf{MXT}, consisting of three key components: (i) \textbf{M}AG (Multimodal Adaptation Gate), (ii) \textbf{X}ception network, and (iii) \textbf{T}5 encoder-decoder. Our system consists of a generative model that \emph{generates} attribute-values for a given product by using both textual and visual characteristics (e.g. images) of the product. We show that our system is capable of handling zero-shot attribute prediction (when attribute value is not seen in training data) and value-absent prediction (when attribute value is not mentioned in the text) which are missing in traditional classification-based and NER-based models respectively. We have trained our models using distant supervision, removing dependency on human labeling, thus making them practical for real-world applications. With this framework, we are able to train a single model for 1000s of (product-type, attribute) pairs, thus reducing the overhead of training and maintaining separate models. Extensive experiments on two real world datasets show that our framework improves the absolute recall@90P by 10.16\% and 6.9\% from the existing state of the art models. In a popular e-commerce store, we have deployed our models for 1000s of (product-type, attribute) pairs.
Distantly Supervised Transformers For E-Commerce Product QA
Apr 07, 2021
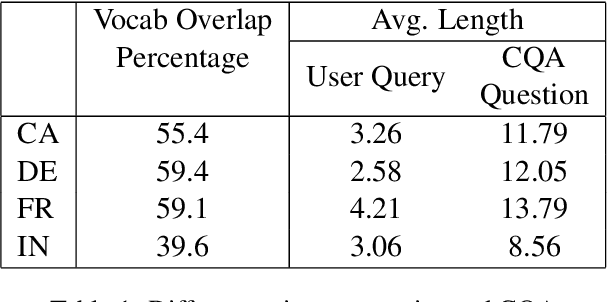
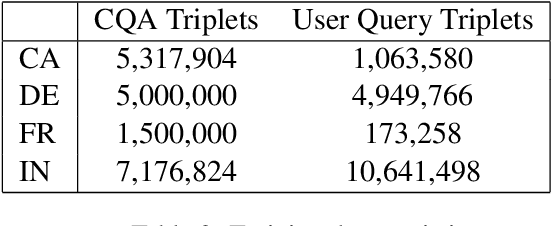
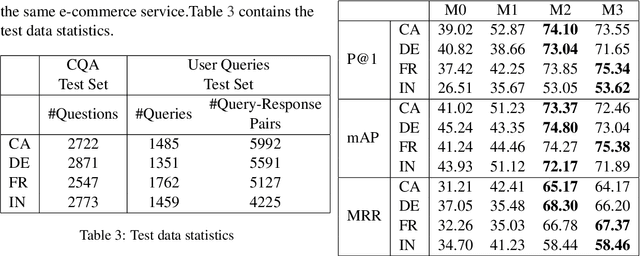
We propose a practical instant question answering (QA) system on product pages of ecommerce services, where for each user query, relevant community question answer (CQA) pairs are retrieved. User queries and CQA pairs differ significantly in language characteristics making relevance learning difficult. Our proposed transformer-based model learns a robust relevance function by jointly learning unified syntactic and semantic representations without the need for human labeled data. This is achieved by distantly supervising our model by distilling from predictions of a syntactic matching system on user queries and simultaneously training with CQA pairs. Training with CQA pairs helps our model learning semantic QA relevance and distant supervision enables learning of syntactic features as well as the nuances of user querying language. Additionally, our model encodes queries and candidate responses independently allowing offline candidate embedding generation thereby minimizing the need for real-time transformer model execution. Consequently, our framework is able to scale to large e-commerce QA traffic. Extensive evaluation on user queries shows that our framework significantly outperforms both syntactic and semantic baselines in offline as well as large scale online A/B setups of a popular e-commerce service.
Lifted Marginal MAP Inference
Jul 08, 2018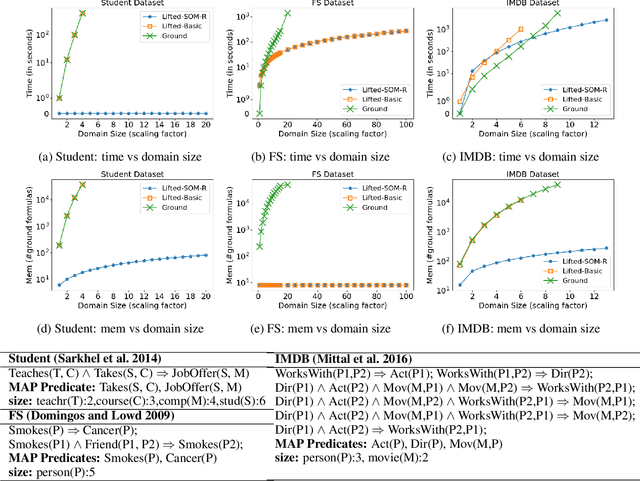
Lifted inference reduces the complexity of inference in relational probabilistic models by identifying groups of constants (or atoms) which behave symmetric to each other. A number of techniques have been proposed in the literature for lifting marginal as well MAP inference. We present the first application of lifting rules for marginal-MAP (MMAP), an important inference problem in models having latent (random) variables. Our main contribution is two fold: (1) we define a new equivalence class of (logical) variables, called Single Occurrence for MAX (SOM), and show that solution lies at extreme with respect to the SOM variables, i.e., predicate groundings differing only in the instantiation of the SOM variables take the same truth value (2) we define a sub-class {\em SOM-R} (SOM Reduce) and exploit properties of extreme assignments to show that MMAP inference can be performed by reducing the domain of SOM-R variables to a single constant.We refer to our lifting technique as the {\em SOM-R} rule for lifted MMAP. Combined with existing rules such as decomposer and binomial, this results in a powerful framework for lifted MMAP. Experiments on three benchmark domains show significant gains in both time and memory compared to ground inference as well as lifted approaches not using SOM-R.
Domain Aware Markov Logic Networks
Jul 07, 2018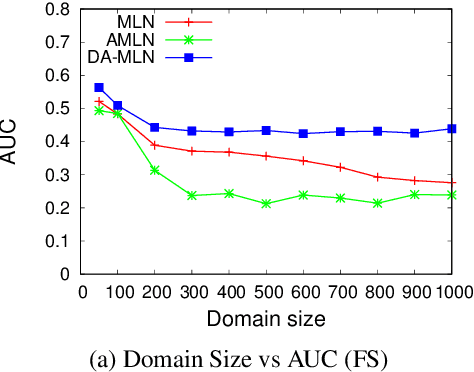
Combining logic and probability has been a long stand- ing goal of AI research. Markov Logic Networks (MLNs) achieve this by attaching weights to formulas in first-order logic, and can be seen as templates for constructing features for ground Markov networks. Most techniques for learning weights of MLNs are domain-size agnostic, i.e., the size of the domain is not explicitly taken into account while learn- ing the parameters of the model. This often results in ex- treme probabilities when testing on domain sizes different from those seen during training. In this paper, we propose Domain Aware Markov logic Networks (DA-MLNs) which present a principled solution to this problem. While defin- ing the ground network distribution, DA-MLNs divide the ground feature weight by a scaling factor which is a function of the number of connections the ground atoms appearing in the feature are involved in. We show that standard MLNs fall out as a special case of our formalism when this func- tion evaluates to a constant equal to 1. Experiments on the benchmark Friends & Smokers domain show that our ap- proach results in significantly higher accuracies compared to existing methods when testing on domains whose sizes different from those seen during training.