 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmory: Building Coherent Narrative-Driven Agent Memory through Agentic Reasoning
Jan 09, 2026Long-term conversational agents face a fundamental scalability challenge as interactions extend over time: repeatedly processing entire conversation histories becomes computationally prohibitive. Current approaches attempt to solve this through memory frameworks that predominantly fragment conversations into isolated embeddings or graph representations and retrieve relevant ones in a RAG style. While computationally efficient, these methods often treat memory formation minimally and fail to capture the subtlety and coherence of human memory. We introduce Amory, a working memory framework that actively constructs structured memory representations through enhancing agentic reasoning during offline time. Amory organizes conversational fragments into episodic narratives, consolidates memories with momentum, and semanticizes peripheral facts into semantic memory. At retrieval time, the system employs coherence-driven reasoning over narrative structures. Evaluated on the LOCOMO benchmark for long-term reasoning, Amory achieves considerable improvements over previous state-of-the-art, with performance comparable to full context reasoning while reducing response time by 50%. Analysis shows that momentum-aware consolidation significantly enhances response quality, while coherence-driven retrieval provides superior memory coverage compared to embedding-based approaches.
LLM-based Weak Supervision Framework for Query Intent Classification in Video Search
Sep 13, 2024


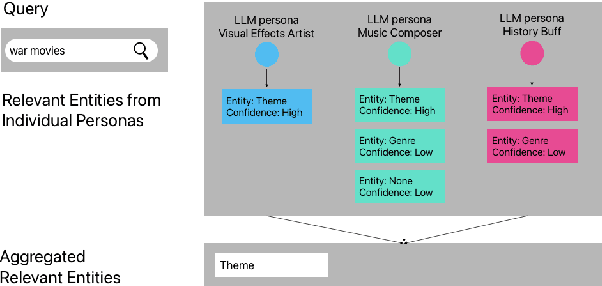
Streaming services have reshaped how we discover and engage with digital entertainment. Despite these advancements, effectively understanding the wide spectrum of user search queries continues to pose a significant challenge. An accurate query understanding system that can handle a variety of entities that represent different user intents is essential for delivering an enhanced user experience. We can build such a system by training a natural language understanding (NLU) model; however, obtaining high-quality labeled training data in this specialized domain is a substantial obstacle. Manual annotation is costly and impractical for capturing users' vast vocabulary variations. To address this, we introduce a novel approach that leverages large language models (LLMs) through weak supervision to automatically annotate a vast collection of user search queries. Using prompt engineering and a diverse set of LLM personas, we generate training data that matches human annotator expectations. By incorporating domain knowledge via Chain of Thought and In-Context Learning, our approach leverages the labeled data to train low-latency models optimized for real-time inference. Extensive evaluations demonstrated that our approach outperformed the baseline with an average relative gain of 113% in recall. Furthermore, our novel prompt engineering framework yields higher quality LLM-generated data to be used for weak supervision; we observed 47.60% improvement over baseline in agreement rate between LLM predictions and human annotations with respect to F1 score, weighted according to the distribution of occurrences of the search queries. Our persona selection routing mechanism further adds an additional 3.67% increase in weighted F1 score on top of our novel prompt engineering framework.
Distantly Supervised Transformers For E-Commerce Product QA
Apr 07, 2021
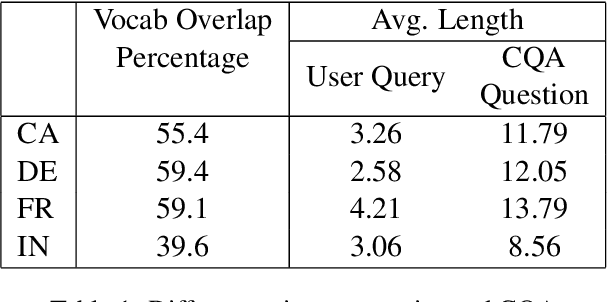
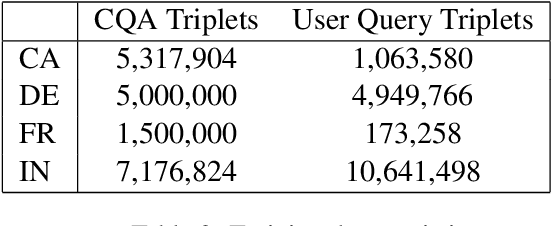
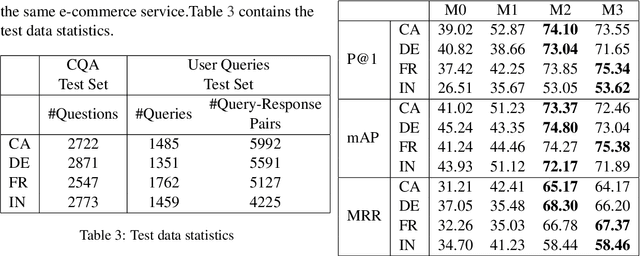
We propose a practical instant question answering (QA) system on product pages of ecommerce services, where for each user query, relevant community question answer (CQA) pairs are retrieved. User queries and CQA pairs differ significantly in language characteristics making relevance learning difficult. Our proposed transformer-based model learns a robust relevance function by jointly learning unified syntactic and semantic representations without the need for human labeled data. This is achieved by distantly supervising our model by distilling from predictions of a syntactic matching system on user queries and simultaneously training with CQA pairs. Training with CQA pairs helps our model learning semantic QA relevance and distant supervision enables learning of syntactic features as well as the nuances of user querying language. Additionally, our model encodes queries and candidate responses independently allowing offline candidate embedding generation thereby minimizing the need for real-time transformer model execution. Consequently, our framework is able to scale to large e-commerce QA traffic. Extensive evaluation on user queries shows that our framework significantly outperforms both syntactic and semantic baselines in offline as well as large scale online A/B setups of a popular e-commerce service.