 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeBaTeR: Denoising Bipartite Temporal Graph for Recommendation
Nov 14, 2024



Due to the difficulty of acquiring large-scale explicit user feedback, implicit feedback (e.g., clicks or other interactions) is widely applied as an alternative source of data, where user-item interactions can be modeled as a bipartite graph. Due to the noisy and biased nature of implicit real-world user-item interactions, identifying and rectifying noisy interactions are vital to enhance model performance and robustness. Previous works on purifying user-item interactions in collaborative filtering mainly focus on mining the correlation between user/item embeddings and noisy interactions, neglecting the benefit of temporal patterns in determining noisy interactions. Time information, while enhancing the model utility, also bears its natural advantage in helping to determine noisy edges, e.g., if someone usually watches horror movies at night and talk shows in the morning, a record of watching a horror movie in the morning is more likely to be noisy interaction. Armed with this observation, we introduce a simple yet effective mechanism for generating time-aware user/item embeddings and propose two strategies for denoising bipartite temporal graph in recommender systems (DeBaTeR): the first is through reweighting the adjacency matrix (DeBaTeR-A), where a reliability score is defined to reweight the edges through both soft assignment and hard assignment; the second is through reweighting the loss function (DeBaTeR-L), where weights are generated to reweight user-item samples in the losses. Extensive experiments have been conducted to demonstrate the efficacy of our methods and illustrate how time information indeed helps identifying noisy edges.
LLM-based Weak Supervision Framework for Query Intent Classification in Video Search
Sep 13, 2024


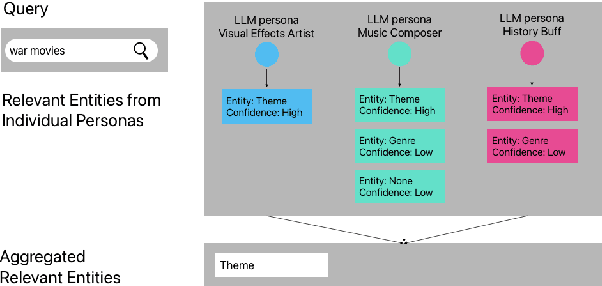
Streaming services have reshaped how we discover and engage with digital entertainment. Despite these advancements, effectively understanding the wide spectrum of user search queries continues to pose a significant challenge. An accurate query understanding system that can handle a variety of entities that represent different user intents is essential for delivering an enhanced user experience. We can build such a system by training a natural language understanding (NLU) model; however, obtaining high-quality labeled training data in this specialized domain is a substantial obstacle. Manual annotation is costly and impractical for capturing users' vast vocabulary variations. To address this, we introduce a novel approach that leverages large language models (LLMs) through weak supervision to automatically annotate a vast collection of user search queries. Using prompt engineering and a diverse set of LLM personas, we generate training data that matches human annotator expectations. By incorporating domain knowledge via Chain of Thought and In-Context Learning, our approach leverages the labeled data to train low-latency models optimized for real-time inference. Extensive evaluations demonstrated that our approach outperformed the baseline with an average relative gain of 113% in recall. Furthermore, our novel prompt engineering framework yields higher quality LLM-generated data to be used for weak supervision; we observed 47.60% improvement over baseline in agreement rate between LLM predictions and human annotations with respect to F1 score, weighted according to the distribution of occurrences of the search queries. Our persona selection routing mechanism further adds an additional 3.67% increase in weighted F1 score on top of our novel prompt engineering framework.
Automated Data Denoising for Recommendation
May 26, 2023In real-world scenarios, most platforms collect both large-scale, naturally noisy implicit feedback and small-scale yet highly relevant explicit feedback. Due to the issue of data sparsity, implicit feedback is often the default choice for training recommender systems (RS), however, such data could be very noisy due to the randomness and diversity of user behaviors. For instance, a large portion of clicks may not reflect true user preferences and many purchases may result in negative reviews or returns. Fortunately, by utilizing the strengths of both types of feedback to compensate for the weaknesses of the other, we can mitigate the above issue at almost no cost. In this work, we propose an Automated Data Denoising framework, \textbf{\textit{AutoDenoise}}, for recommendation, which uses a small number of explicit data as validation set to guide the recommender training. Inspired by the generalized definition of curriculum learning (CL), AutoDenoise learns to automatically and dynamically assign the most appropriate (discrete or continuous) weights to each implicit data sample along the training process under the guidance of the validation performance. Specifically, we use a delicately designed controller network to generate the weights, combine the weights with the loss of each input data to train the recommender system, and optimize the controller with reinforcement learning to maximize the expected accuracy of the trained RS on the noise-free validation set. Thorough experiments indicate that AutoDenoise is able to boost the performance of the state-of-the-art recommendation algorithms on several public benchmark datasets.
Sense Beyond Expressions: Cuteness
Aug 17, 2015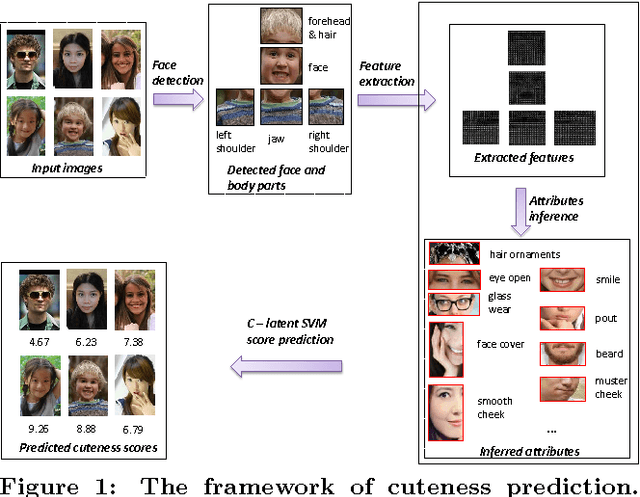



With the development of Internet culture, cuteness has become a popular concept. Many people are curious about what factors making a person look cute. However, there is rare research to answer this interesting question. In this work, we construct a dataset of personal images with comprehensively annotated cuteness scores and facial attributes to investigate this high-level concept in depth. Based on this dataset, through an automatic attributes mining process, we find several critical attributes determining the cuteness of a person. We also develop a novel Continuous Latent Support Vector Machine (C-LSVM) method to predict the cuteness score of one person given only his image. Extensive evaluations validate the effectiveness of the proposed method for cuteness prediction.
Salient Object Detection via Augmented Hypotheses
May 29, 2015



In this paper, we propose using \textit{augmented hypotheses} which consider objectness, foreground and compactness for salient object detection. Our algorithm consists of four basic steps. First, our method generates the objectness map via objectness hypotheses. Based on the objectness map, we estimate the foreground margin and compute the corresponding foreground map which prefers the foreground objects. From the objectness map and the foreground map, the compactness map is formed to favor the compact objects. We then derive a saliency measure that produces a pixel-accurate saliency map which uniformly covers the objects of interest and consistently separates fore- and background. We finally evaluate the proposed framework on two challenging datasets, MSRA-1000 and iCoSeg. Our extensive experimental results show that our method outperforms state-of-the-art approaches.
Adaptive Nonparametric Image Parsing
May 07, 2015

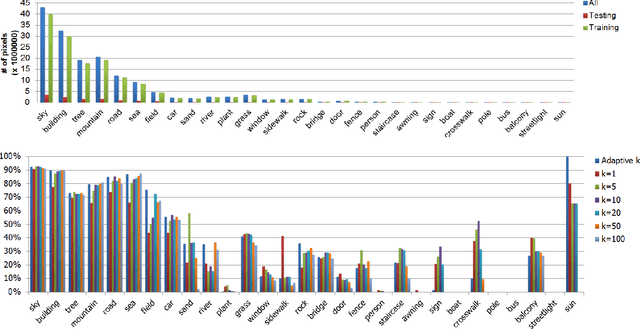
In this paper, we present an adaptive nonparametric solution to the image parsing task, namely annotating each image pixel with its corresponding category label. For a given test image, first, a locality-aware retrieval set is extracted from the training data based on super-pixel matching similarities, which are augmented with feature extraction for better differentiation of local super-pixels. Then, the category of each super-pixel is initialized by the majority vote of the $k$-nearest-neighbor super-pixels in the retrieval set. Instead of fixing $k$ as in traditional non-parametric approaches, here we propose a novel adaptive nonparametric approach which determines the sample-specific k for each test image. In particular, $k$ is adaptively set to be the number of the fewest nearest super-pixels which the images in the retrieval set can use to get the best category prediction. Finally, the initial super-pixel labels are further refined by contextual smoothing. Extensive experiments on challenging datasets demonstrate the superiority of the new solution over other state-of-the-art nonparametric solutions.