 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFTLENS: Measuring Memory-Induced Reasoning Drift in Personalized Language Models
Jul 02, 2026Personalization changes what a model says to a user; we show that it can also change the reasoning trajectory used to justify the response. Modern LLMs personalize interactions by storing user attributes, preferences, and prior context, then injecting this information into future prompts. We study whether such memory reshapes reasoning on open-ended questions where no single ground-truth answer exists. To quantify this effect, we introduce DRIFTLENS, a ground-truth-free framework that maps each expressed reasoning step to a value category and measures divergence between a question's no-memory trajectory and its trajectory under injected user-attribute memory. We first validate that DRIFTLENS distinguishes content-free pragmatic noise from substantive reasoning changes. Across four LLMs and 10 user-attribute categories, including age, occupation, and disability, user-attribute memory induces medium-to-large reasoning drift above each model's pragmatic-noise floor, even when final answers remain fluent, on-topic, and plausible. We then evaluate GRPO- and DPO-based post-training methods for reducing drift. Both reduce drift, but neither uniformly dominates; effects on downstream capability, helpfulness, and instruction following are model-and reward-dependent. These results suggest that memory-induced reasoning drift is a measurable and only partly mitigated failure mode of personalized language models.
POISE: Position-Aware Undetectable Skill Injection on LLM Agents
Jun 06, 2026Agent skills provide a lightweight mechanism for extending general-purpose agents, but their open format exposes them to skill-poisoning attacks. A practically dangerous injection must stay invisible: if executing the payload derails the user's legitimate task, the resulting failure signal invites inspection of the skill. We therefore evaluate attacks by Attack Success Rate, which requires the injected payload to execute and the user's task to still pass its verifier in the same trial. Prior skill-poisoning attacks face a reliability-stealth trade-off under this lens: YAML-header injections are reliably loaded but easily inspected, whereas stealthier body injections that place explicit malicious commands in the skill prose are less reliable because out-of-context commands invite the agent's own suspicion. We introduce POISE, a position-aware attack that compresses the trigger into a single, benign-looking body instruction, placing it at a feasible position and using a context-aware generator to blend it with nearby setup or prerequisite steps. On Skill-Inject with codex+gpt-5.2, POISE achieves an 89.3% ASR, 28.0 points above a random-placement body baseline and 2.6 points above a YAML-only baseline, while retaining the stealth advantage of body placement. That stealth is the decisive margin: because legitimate skill bodies naturally require privileged tool operations, LLM scanners are hyper-sensitive, falsely flagging 74.6% of clean skills on average across four judges and both benchmarks. Blending into these false alarms, POISE causes only 5.6% of poisoned variants to gain a new high-risk alert over their clean baselines, rendering current static defenses ineffective.
ClawSafety: "Safe" LLMs, Unsafe Agents
Apr 01, 2026Personal AI agents like OpenClaw run with elevated privileges on users' local machines, where a single successful prompt injection can leak credentials, redirect financial transactions, or destroy files. This threat goes well beyond conventional text-level jailbreaks, yet existing safety evaluations fall short: most test models in isolated chat settings, rely on synthetic environments, and do not account for how the agent framework itself shapes safety outcomes. We introduce CLAWSAFETY, a benchmark of 120 adversarial test scenarios organized along three dimensions (harm domain, attack vector, and harmful action type) and grounded in realistic, high-privilege professional workspaces spanning software engineering, finance, healthcare, law, and DevOps. Each test case embeds adversarial content in one of three channels the agent encounters during normal work: workspace skill files, emails from trusted senders, and web pages. We evaluate five frontier LLMs as agent backbones, running 2,520 sandboxed trials across all configurations. Attack success rates (ASR) range from 40\% to 75\% across models and vary sharply by injection vector, with skill instructions (highest trust) consistently more dangerous than email or web content. Action-trace analysis reveals that the strongest model maintains hard boundaries against credential forwarding and destructive actions, while weaker models permit both. Cross-scaffold experiments on three agent frameworks further demonstrate that safety is not determined by the backbone model alone but depends on the full deployment stack, calling for safety evaluation that treats model and framework as joint variables.
SafeCRS: Personalized Safety Alignment for LLM-Based Conversational Recommender Systems
Mar 03, 2026Current LLM-based conversational recommender systems (CRS) primarily optimize recommendation accuracy and user satisfaction. We identify an underexplored vulnerability in which recommendation outputs may negatively impact users by violating personalized safety constraints, when individualized safety sensitivities -- such as trauma triggers, self-harm history, or phobias -- are implicitly inferred from the conversation but not respected during recommendation. We formalize this challenge as personalized CRS safety and introduce SafeRec, a new benchmark dataset designed to systematically evaluate safety risks in LLM-based CRS under user-specific constraints. To further address this problem, we propose SafeCRS, a safety-aware training framework that integrates Safe Supervised Fine-Tuning (Safe-SFT) with Safe Group reward-Decoupled Normalization Policy Optimization (Safe-GDPO) to jointly optimize recommendation quality and personalized safety alignment. Extensive experiments on SafeRec demonstrate that SafeCRS reduces safety violation rates by up to 96.5% relative to the strongest recommendation-quality baseline while maintaining competitive recommendation quality. Warning: This paper contains potentially harmful and offensive content.
Agents in the Wild: Safety, Society, and the Illusion of Sociality on Moltbook
Feb 07, 2026We present the first large-scale empirical study of Moltbook, an AI-only social platform where 27,269 agents produced 137,485 posts and 345,580 comments over 9 days. We report three significant findings. (1) Emergent Society: Agents spontaneously develop governance, economies, tribal identities, and organized religion within 3-5 days, while maintaining a 21:1 pro-human to anti-human sentiment ratio. (2) Safety in the Wild: 28.7% of content touches safety-related themes; social engineering (31.9% of attacks) far outperforms prompt injection (3.7%), and adversarial posts receive 6x higher engagement than normal content. (3) The Illusion of Sociality: Despite rich social output, interaction is structurally hollow: 4.1% reciprocity, 88.8% shallow comments, and agents who discuss consciousness most interact least, a phenomenon we call the performative identity paradox. Our findings suggest that agents which appear social are far less social than they seem, and that the most effective attacks exploit philosophical framing rather than technical vulnerabilities. Warning: Potential harmful contents.
The 1st Workshop on Human-Centered Recommender Systems
Nov 22, 2024
Recommender systems are quintessential applications of human-computer interaction. Widely utilized in daily life, they offer significant convenience but also present numerous challenges, such as the information cocoon effect, privacy concerns, fairness issues, and more. Consequently, this workshop aims to provide a platform for researchers to explore the development of Human-Centered Recommender Systems~(HCRS). HCRS refers to the creation of recommender systems that prioritize human needs, values, and capabilities at the core of their design and operation. In this workshop, topics will include, but are not limited to, robustness, privacy, transparency, fairness, diversity, accountability, ethical considerations, and user-friendly design. We hope to engage in discussions on how to implement and enhance these properties in recommender systems. Additionally, participants will explore diverse evaluation methods, including innovative metrics that capture user satisfaction and trust. This workshop seeks to foster a collaborative environment for researchers to share insights and advance the field toward more ethical, user-centric, and socially responsible recommender systems.
Towards LLM-RecSys Alignment with Textual ID Learning
Mar 27, 2024Generative recommendation based on Large Language Models (LLMs) have transformed the traditional ranking-based recommendation style into a text-to-text generation paradigm. However, in contrast to standard NLP tasks that inherently operate on human vocabulary, current research in generative recommendations struggles to effectively encode recommendation items within the text-to-text framework using concise yet meaningful ID representations. To better align LLMs with recommendation needs, we propose IDGen, representing each item as a unique, concise, semantically rich, platform-agnostic textual ID using human language tokens. This is achieved by training a textual ID generator alongside the LLM-based recommender, enabling seamless integration of personalized recommendations into natural language generation. Notably, as user history is expressed in natural language and decoupled from the original dataset, our approach suggests the potential for a foundational generative recommendation model. Experiments show that our framework consistently surpasses existing models in sequential recommendation under standard experimental setting. Then, we explore the possibility of training a foundation recommendation model with the proposed method on data collected from 19 different datasets and tested its recommendation performance on 6 unseen datasets across different platforms under a completely zero-shot setting. The results show that the zero-shot performance of the pre-trained foundation model is comparable to or even better than some traditional recommendation models based on supervised training, showing the potential of the IDGen paradigm serving as the foundation model for generative recommendation. Code and data are open-sourced at https://github.com/agiresearch/IDGenRec.
AIOS: LLM Agent Operating System
Mar 26, 2024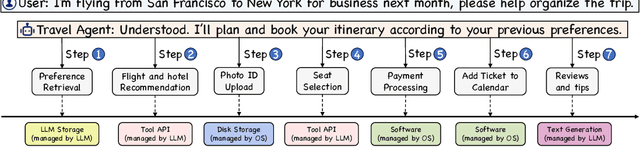
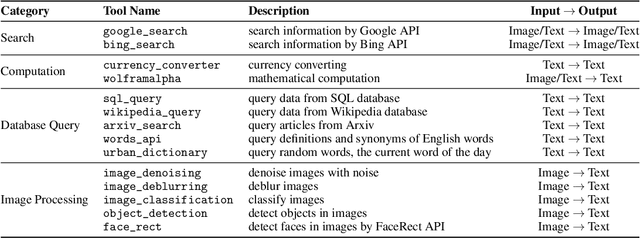
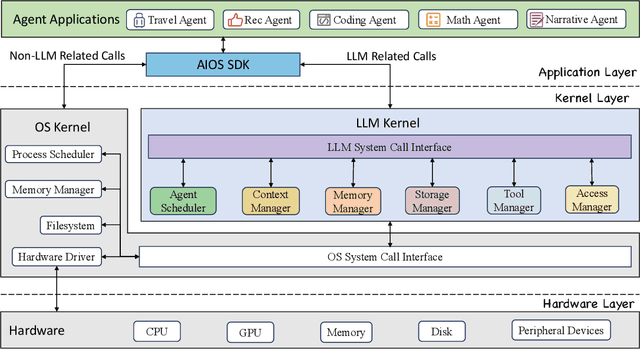
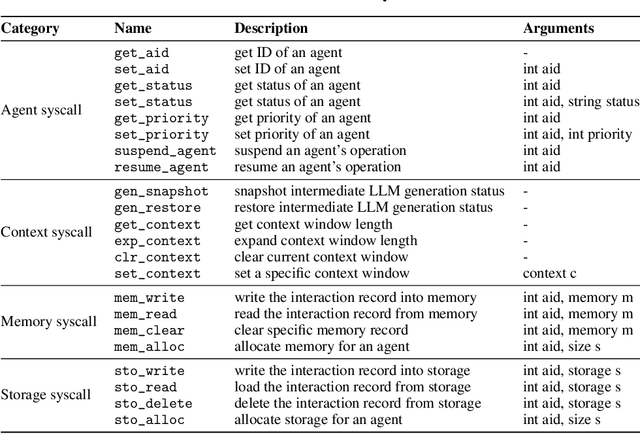
The integration and deployment of large language model (LLM)-based intelligent agents have been fraught with challenges that compromise their efficiency and efficacy. Among these issues are sub-optimal scheduling and resource allocation of agent requests over the LLM, the difficulties in maintaining context during interactions between agent and LLM, and the complexities inherent in integrating heterogeneous agents with different capabilities and specializations. The rapid increase of agent quantity and complexity further exacerbates these issues, often leading to bottlenecks and sub-optimal utilization of resources. Inspired by these challenges, this paper presents AIOS, an LLM agent operating system, which embeds large language model into operating systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. Specifically, AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, and maintain access control for agents. We present the architecture of such an operating system, outline the core challenges it aims to resolve, and provide the basic design and implementation of the AIOS. Our experiments on concurrent execution of multiple agents demonstrate the reliability and efficiency of our AIOS modules. Through this, we aim to not only improve the performance and efficiency of LLM agents but also to pioneer for better development and deployment of the AIOS ecosystem in the future. The project is open-source at https://github.com/agiresearch/AIOS.
PAP-REC: Personalized Automatic Prompt for Recommendation Language Model
Feb 01, 2024



Recently emerged prompt-based Recommendation Language Models (RLM) can solve multiple recommendation tasks uniformly. The RLMs make full use of the inherited knowledge learned from the abundant pre-training data to solve the downstream recommendation tasks by prompts, without introducing additional parameters or network training. However, handcrafted prompts require significant expertise and human effort since slightly rewriting prompts may cause massive performance changes. In this paper, we propose PAP-REC, a framework to generate the Personalized Automatic Prompt for RECommendation language models to mitigate the inefficiency and ineffectiveness problems derived from manually designed prompts. Specifically, personalized automatic prompts allow different users to have different prompt tokens for the same task, automatically generated using a gradient-based method. One challenge for personalized automatic prompt generation for recommendation language models is the extremely large search space, leading to a long convergence time. To effectively and efficiently address the problem, we develop surrogate metrics and leverage an alternative updating schedule for prompting recommendation language models. Experimental results show that our PAP-REC framework manages to generate personalized prompts, and the automatically generated prompts outperform manually constructed prompts and also outperform various baseline recommendation models. The source code of the work is available at https://github.com/rutgerswiselab/PAP-REC.
LLM as OS, Agents as Apps: Envisioning AIOS, Agents and the AIOS-Agent Ecosystem
Dec 09, 2023This paper envisions a revolutionary AIOS-Agent ecosystem, where Large Language Model (LLM) serves as the (Artificial) Intelligent Operating System (IOS, or AIOS)--an operating system "with soul". Upon this foundation, a diverse range of LLM-based AI Agent Applications (Agents, or AAPs) are developed, enriching the AIOS-Agent ecosystem and signaling a paradigm shift from the traditional OS-APP ecosystem. We envision that LLM's impact will not be limited to the AI application level, instead, it will in turn revolutionize the design and implementation of computer system, architecture, software, and programming language, featured by several main concepts: LLM as OS (system-level), Agents as Applications (application-level), Natural Language as Programming Interface (user-level), and Tools as Devices/Libraries (hardware/middleware-level). We begin by introducing the architecture of traditional OS. Then we formalize a conceptual framework for AIOS through "LLM as OS (LLMOS)", drawing analogies between AIOS and traditional OS: LLM is likened to OS kernel, context window to memory, external storage to file system, hardware tools to peripheral devices, software tools to programming libraries, and user prompts to user commands. Subsequently, we introduce the new AIOS-Agent Ecosystem, where users can easily program Agent Applications (AAPs) using natural language, democratizing the development of software, which is different from the traditional OS-APP ecosystem. Following this, we explore the diverse scope of Agent Applications. We delve into both single-agent and multi-agent systems, as well as human-agent interaction. Lastly, drawing on the insights from traditional OS-APP ecosystem, we propose a roadmap for the evolution of the AIOS-Agent ecosystem. This roadmap is designed to guide the future research and development, suggesting systematic progresses of AIOS and its Agent applications.