 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIT: A Dynamic Personalized Item Tokenizer for End-to-End Generative Recommendation
Feb 09, 2026Generative Recommendation has revolutionized recommender systems by reformulating retrieval as a sequence generation task over discrete item identifiers. Despite the progress, existing approaches typically rely on static, decoupled tokenization that ignores collaborative signals. While recent methods attempt to integrate collaborative signals into item identifiers either during index construction or through end-to-end modeling, they encounter significant challenges in real-world production environments. Specifically, the volatility of collaborative signals leads to unstable tokenization, and current end-to-end strategies often devolve into suboptimal two-stage training rather than achieving true co-evolution. To bridge this gap, we propose PIT, a dynamic Personalized Item Tokenizer framework for end-to-end generative recommendation, which employs a co-generative architecture that harmonizes collaborative patterns through collaborative signal alignment and synchronizes item tokenizer with generative recommender via a co-evolution learning. This enables the dynamic, joint, end-to-end evolution of both index construction and recommendation. Furthermore, a one-to-many beam index ensures scalability and robustness, facilitating seamless integration into large-scale industrial deployments. Extensive experiments on real-world datasets demonstrate that PIT consistently outperforms competitive baselines. In a large-scale deployment at Kuaishou, an online A/B test yielded a substantial 0.402% uplift in App Stay Time, validating the framework's effectiveness in dynamic industrial environments.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025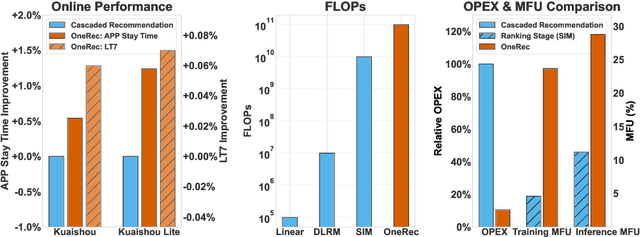

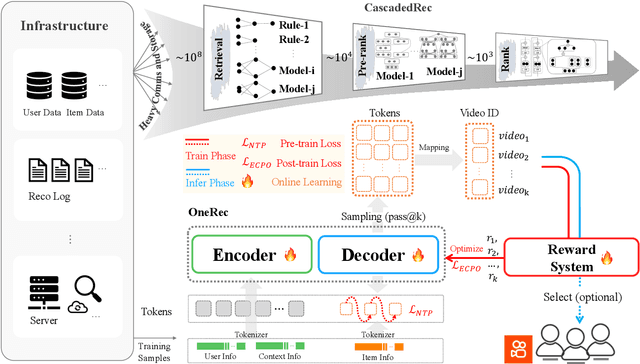

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
ABCDWaveNet: Advancing Robust Road Ponding Detection in Fog through Dynamic Frequency-Spatial Synergy
Apr 07, 2025Road ponding presents a significant threat to vehicle safety, particularly in adverse fog conditions, where reliable detection remains a persistent challenge for Advanced Driver Assistance Systems (ADAS). To address this, we propose ABCDWaveNet, a novel deep learning framework leveraging Dynamic Frequency-Spatial Synergy for robust ponding detection in fog. The core of ABCDWaveNet achieves this synergy by integrating dynamic convolution for adaptive feature extraction across varying visibilities with a wavelet-based module for synergistic frequency-spatial feature enhancement, significantly improving robustness against fog interference. Building on this foundation, ABCDWaveNet captures multi-scale structural and contextual information, subsequently employing an Adaptive Attention Coupling Gate (AACG) to adaptively fuse global and local features for enhanced accuracy. To facilitate realistic evaluations under combined adverse conditions, we introduce the Foggy Low-Light Puddle dataset. Extensive experiments demonstrate that ABCDWaveNet establishes new state-of-the-art performance, achieving significant Intersection over Union (IoU) gains of 3.51%, 1.75%, and 1.03% on the Foggy-Puddle, Puddle-1000, and our Foggy Low-Light Puddle datasets, respectively. Furthermore, its processing speed of 25.48 FPS on an NVIDIA Jetson AGX Orin confirms its suitability for ADAS deployment. These findings underscore the effectiveness of the proposed Dynamic Frequency-Spatial Synergy within ABCDWaveNet, offering valuable insights for developing proactive road safety solutions capable of operating reliably in challenging weather conditions.
YOLO-LLTS: Real-Time Low-Light Traffic Sign Detection via Prior-Guided Enhancement and Multi-Branch Feature Interaction
Mar 18, 2025Detecting traffic signs effectively under low-light conditions remains a significant challenge. To address this issue, we propose YOLO-LLTS, an end-to-end real-time traffic sign detection algorithm specifically designed for low-light environments. Firstly, we introduce the High-Resolution Feature Map for Small Object Detection (HRFM-TOD) module to address indistinct small-object features in low-light scenarios. By leveraging high-resolution feature maps, HRFM-TOD effectively mitigates the feature dilution problem encountered in conventional PANet frameworks, thereby enhancing both detection accuracy and inference speed. Secondly, we develop the Multi-branch Feature Interaction Attention (MFIA) module, which facilitates deep feature interaction across multiple receptive fields in both channel and spatial dimensions, significantly improving the model's information extraction capabilities. Finally, we propose the Prior-Guided Enhancement Module (PGFE) to tackle common image quality challenges in low-light environments, such as noise, low contrast, and blurriness. This module employs prior knowledge to enrich image details and enhance visibility, substantially boosting detection performance. To support this research, we construct a novel dataset, the Chinese Nighttime Traffic Sign Sample Set (CNTSSS), covering diverse nighttime scenarios, including urban, highway, and rural environments under varying weather conditions. Experimental evaluations demonstrate that YOLO-LLTS achieves state-of-the-art performance, outperforming the previous best methods by 2.7% mAP50 and 1.6% mAP50:95 on TT100K-night, 1.3% mAP50 and 1.9% mAP50:95 on CNTSSS, and achieving superior results on the CCTSDB2021 dataset. Moreover, deployment experiments on edge devices confirm the real-time applicability and effectiveness of our proposed approach.
The 1st Workshop on Human-Centered Recommender Systems
Nov 22, 2024
Recommender systems are quintessential applications of human-computer interaction. Widely utilized in daily life, they offer significant convenience but also present numerous challenges, such as the information cocoon effect, privacy concerns, fairness issues, and more. Consequently, this workshop aims to provide a platform for researchers to explore the development of Human-Centered Recommender Systems~(HCRS). HCRS refers to the creation of recommender systems that prioritize human needs, values, and capabilities at the core of their design and operation. In this workshop, topics will include, but are not limited to, robustness, privacy, transparency, fairness, diversity, accountability, ethical considerations, and user-friendly design. We hope to engage in discussions on how to implement and enhance these properties in recommender systems. Additionally, participants will explore diverse evaluation methods, including innovative metrics that capture user satisfaction and trust. This workshop seeks to foster a collaborative environment for researchers to share insights and advance the field toward more ethical, user-centric, and socially responsible recommender systems.
Improving the Shortest Plank: Vulnerability-Aware Adversarial Training for Robust Recommender System
Sep 26, 2024



Recommender systems play a pivotal role in mitigating information overload in various fields. Nonetheless, the inherent openness of these systems introduces vulnerabilities, allowing attackers to insert fake users into the system's training data to skew the exposure of certain items, known as poisoning attacks. Adversarial training has emerged as a notable defense mechanism against such poisoning attacks within recommender systems. Existing adversarial training methods apply perturbations of the same magnitude across all users to enhance system robustness against attacks. Yet, in reality, we find that attacks often affect only a subset of users who are vulnerable. These perturbations of indiscriminate magnitude make it difficult to balance effective protection for vulnerable users without degrading recommendation quality for those who are not affected. To address this issue, our research delves into understanding user vulnerability. Considering that poisoning attacks pollute the training data, we note that the higher degree to which a recommender system fits users' training data correlates with an increased likelihood of users incorporating attack information, indicating their vulnerability. Leveraging these insights, we introduce the Vulnerability-aware Adversarial Training (VAT), designed to defend against poisoning attacks in recommender systems. VAT employs a novel vulnerability-aware function to estimate users' vulnerability based on the degree to which the system fits them. Guided by this estimation, VAT applies perturbations of adaptive magnitude to each user, not only reducing the success ratio of attacks but also preserving, and potentially enhancing, the quality of recommendations. Comprehensive experiments confirm VAT's superior defensive capabilities across different recommendation models and against various types of attacks.
Accelerating the Surrogate Retraining for Poisoning Attacks against Recommender Systems
Aug 20, 2024



Recent studies have demonstrated the vulnerability of recommender systems to data poisoning attacks, where adversaries inject carefully crafted fake user interactions into the training data of recommenders to promote target items. Current attack methods involve iteratively retraining a surrogate recommender on the poisoned data with the latest fake users to optimize the attack. However, this repetitive retraining is highly time-consuming, hindering the efficient assessment and optimization of fake users. To mitigate this computational bottleneck and develop a more effective attack in an affordable time, we analyze the retraining process and find that a change in the representation of one user/item will cause a cascading effect through the user-item interaction graph. Under theoretical guidance, we introduce \emph{Gradient Passing} (GP), a novel technique that explicitly passes gradients between interacted user-item pairs during backpropagation, thereby approximating the cascading effect and accelerating retraining. With just a single update, GP can achieve effects comparable to multiple original training iterations. Under the same number of retraining epochs, GP enables a closer approximation of the surrogate recommender to the victim. This more accurate approximation provides better guidance for optimizing fake users, ultimately leading to enhanced data poisoning attacks. Extensive experiments on real-world datasets demonstrate the efficiency and effectiveness of our proposed GP.
LoRec: Large Language Model for Robust Sequential Recommendation against Poisoning Attacks
Jan 31, 2024



Sequential recommender systems stand out for their ability to capture users' dynamic interests and the patterns of item-to-item transitions. However, the inherent openness of sequential recommender systems renders them vulnerable to poisoning attacks, where fraudulent users are injected into the training data to manipulate learned patterns. Traditional defense strategies predominantly depend on predefined assumptions or rules extracted from specific known attacks, limiting their generalizability to unknown attack types. To solve the above problems, considering the rich open-world knowledge encapsulated in Large Language Models (LLMs), our research initially focuses on the capabilities of LLMs in the detection of unknown fraudulent activities within recommender systems, a strategy we denote as LLM4Dec. Empirical evaluations demonstrate the substantial capability of LLMs in identifying unknown fraudsters, leveraging their expansive, open-world knowledge. Building upon this, we propose the integration of LLMs into defense strategies to extend their effectiveness beyond the confines of known attacks. We propose LoRec, an advanced framework that employs LLM-Enhanced Calibration to strengthen the robustness of sequential recommender systems against poisoning attacks. LoRec integrates an LLM-enhanced CalibraTor (LCT) that refines the training process of sequential recommender systems with knowledge derived from LLMs, applying a user-wise reweighting to diminish the impact of fraudsters injected by attacks. By incorporating LLMs' open-world knowledge, the LCT effectively converts the limited, specific priors or rules into a more general pattern of fraudsters, offering improved defenses against poisoning attacks. Our comprehensive experiments validate that LoRec, as a general framework, significantly strengthens the robustness of sequential recommender systems.