 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
A Robust Real-Time Lane Detection Method with Fog-Enhanced Feature Fusion for Foggy Conditions
Apr 08, 2025Lane detection is a critical component of Advanced Driver Assistance Systems (ADAS). Existing lane detection algorithms generally perform well under favorable weather conditions. However, their performance degrades significantly in adverse conditions, such as fog, which increases the risk of traffic accidents. This challenge is compounded by the lack of specialized datasets and methods designed for foggy environments. To address this, we introduce the FoggyLane dataset, captured in real-world foggy scenarios, and synthesize two additional datasets, FoggyCULane and FoggyTusimple, from existing popular lane detection datasets. Furthermore, we propose a robust Fog-Enhanced Network for lane detection, incorporating a Global Feature Fusion Module (GFFM) to capture global relationships in foggy images, a Kernel Feature Fusion Module (KFFM) to model the structural and positional relationships of lane instances, and a Low-level Edge Enhanced Module (LEEM) to address missing edge details in foggy conditions. Comprehensive experiments demonstrate that our method achieves state-of-the-art performance, with F1-scores of 95.04 on FoggyLane, 79.85 on FoggyCULane, and 96.95 on FoggyTusimple. Additionally, with TensorRT acceleration, the method reaches a processing speed of 38.4 FPS on the NVIDIA Jetson AGX Orin, confirming its real-time capabilities and robustness in foggy environments.
ABCDWaveNet: Advancing Robust Road Ponding Detection in Fog through Dynamic Frequency-Spatial Synergy
Apr 07, 2025Road ponding presents a significant threat to vehicle safety, particularly in adverse fog conditions, where reliable detection remains a persistent challenge for Advanced Driver Assistance Systems (ADAS). To address this, we propose ABCDWaveNet, a novel deep learning framework leveraging Dynamic Frequency-Spatial Synergy for robust ponding detection in fog. The core of ABCDWaveNet achieves this synergy by integrating dynamic convolution for adaptive feature extraction across varying visibilities with a wavelet-based module for synergistic frequency-spatial feature enhancement, significantly improving robustness against fog interference. Building on this foundation, ABCDWaveNet captures multi-scale structural and contextual information, subsequently employing an Adaptive Attention Coupling Gate (AACG) to adaptively fuse global and local features for enhanced accuracy. To facilitate realistic evaluations under combined adverse conditions, we introduce the Foggy Low-Light Puddle dataset. Extensive experiments demonstrate that ABCDWaveNet establishes new state-of-the-art performance, achieving significant Intersection over Union (IoU) gains of 3.51%, 1.75%, and 1.03% on the Foggy-Puddle, Puddle-1000, and our Foggy Low-Light Puddle datasets, respectively. Furthermore, its processing speed of 25.48 FPS on an NVIDIA Jetson AGX Orin confirms its suitability for ADAS deployment. These findings underscore the effectiveness of the proposed Dynamic Frequency-Spatial Synergy within ABCDWaveNet, offering valuable insights for developing proactive road safety solutions capable of operating reliably in challenging weather conditions.
EMDFNet: Efficient Multi-scale and Diverse Feature Network for Traffic Sign Detection
Aug 26, 2024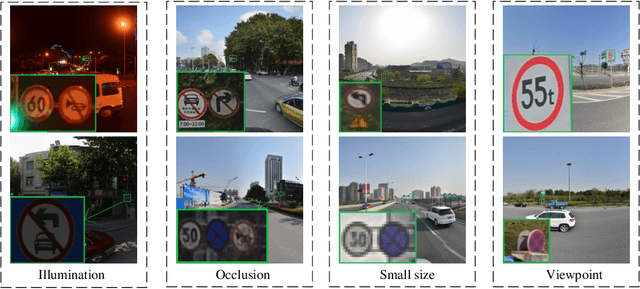
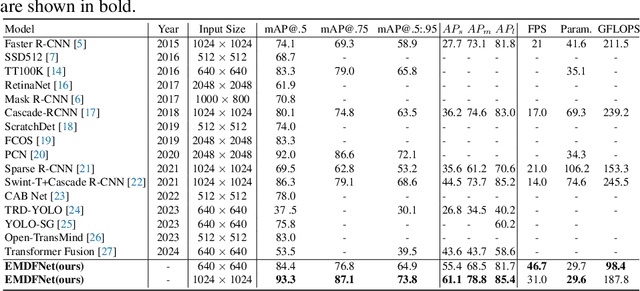
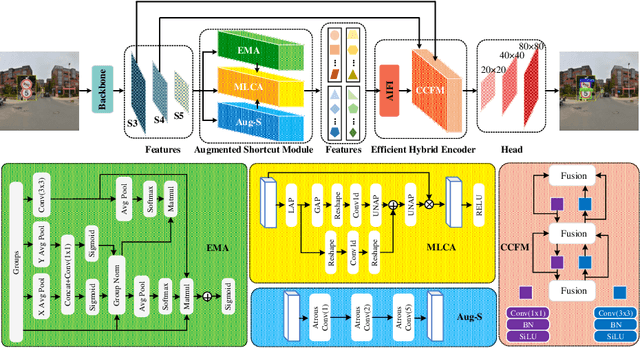
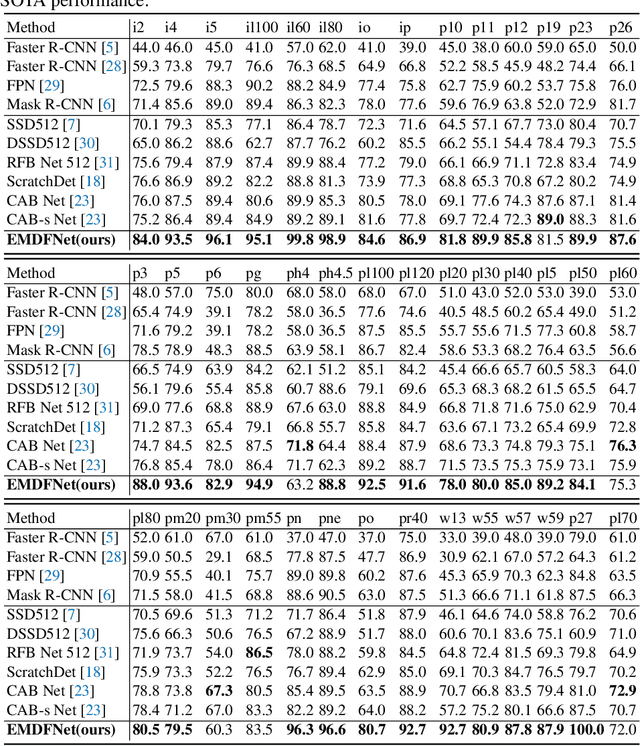
The detection of small objects, particularly traffic signs, is a critical subtask within object detection and autonomous driving. Despite the notable achievements in previous research, two primary challenges persist. Firstly, the main issue is the singleness of feature extraction. Secondly, the detection process fails to effectively integrate with objects of varying sizes or scales. These issues are also prevalent in generic object detection. Motivated by these challenges, in this paper, we propose a novel object detection network named Efficient Multi-scale and Diverse Feature Network (EMDFNet) for traffic sign detection that integrates an Augmented Shortcut Module and an Efficient Hybrid Encoder to address the aforementioned issues simultaneously. Specifically, the Augmented Shortcut Module utilizes multiple branches to integrate various spatial semantic information and channel semantic information, thereby enhancing feature diversity. The Efficient Hybrid Encoder utilizes global feature fusion and local feature interaction based on various features to generate distinctive classification features by integrating feature information in an adaptable manner. Extensive experiments on the Tsinghua-Tencent 100K (TT100K) benchmark and the German Traffic Sign Detection Benchmark (GTSDB) demonstrate that our EMDFNet outperforms other state-of-the-art detectors in performance while retaining the real-time processing capabilities of single-stage models. This substantiates the effectiveness of EMDFNet in detecting small traffic signs.
A Classifier-Free Incremental Learning Framework for Scalable Medical Image Segmentation
May 25, 2024



Current methods for developing foundation models in medical image segmentation rely on two primary assumptions: a fixed set of classes and the immediate availability of a substantial and diverse training dataset. However, this can be impractical due to the evolving nature of imaging technology and patient demographics, as well as labor-intensive data curation, limiting their practical applicability and scalability. To address these challenges, we introduce a novel segmentation paradigm enabling the segmentation of a variable number of classes within a single classifier-free network, featuring an architecture independent of class number. This network is trained using contrastive learning and produces discriminative feature representations that facilitate straightforward interpretation. Additionally, we integrate this strategy into a knowledge distillation-based incremental learning framework, facilitating the gradual assimilation of new information from non-stationary data streams while avoiding catastrophic forgetting. Our approach provides a unified solution for tackling both class- and domain-incremental learning scenarios. We demonstrate the flexibility of our method in handling varying class numbers within a unified network and its capacity for incremental learning. Experimental results on an incompletely annotated, multi-modal, multi-source dataset for medical image segmentation underscore its superiority over state-of-the-art alternative approaches.
Evaluating Deep Vs. Wide & Deep Learners As Contextual Bandits For Personalized Email Promo Recommendations
Jan 31, 2022



Personalization enables businesses to learn customer preferences from past interactions and thus to target individual customers with more relevant content. We consider the problem of predicting the optimal promotional offer for a given customer out of several options as a contextual bandit problem. Identifying information for the customer and/or the campaign can be used to deduce unknown customer/campaign features that improve optimal offer prediction. Using a generated synthetic email promo dataset, we demonstrate similar prediction accuracies for (a) a wide and deep network that takes identifying information (or other categorical features) as input to the wide part and (b) a deep-only neural network that includes embeddings of categorical features in the input. Improvements in accuracy from including categorical features depends on the variability of the unknown numerical features for each category. We also show that selecting options using upper confidence bound or Thompson sampling, approximated via Monte Carlo dropout layers in the wide and deep models, slightly improves model performance.
A New Many-Objective Evolutionary Algorithm Based on Determinantal Point Processes
Dec 15, 2020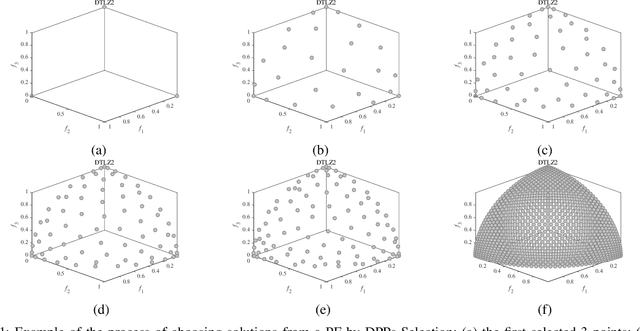
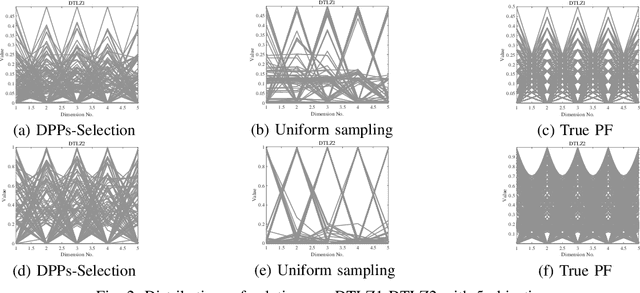
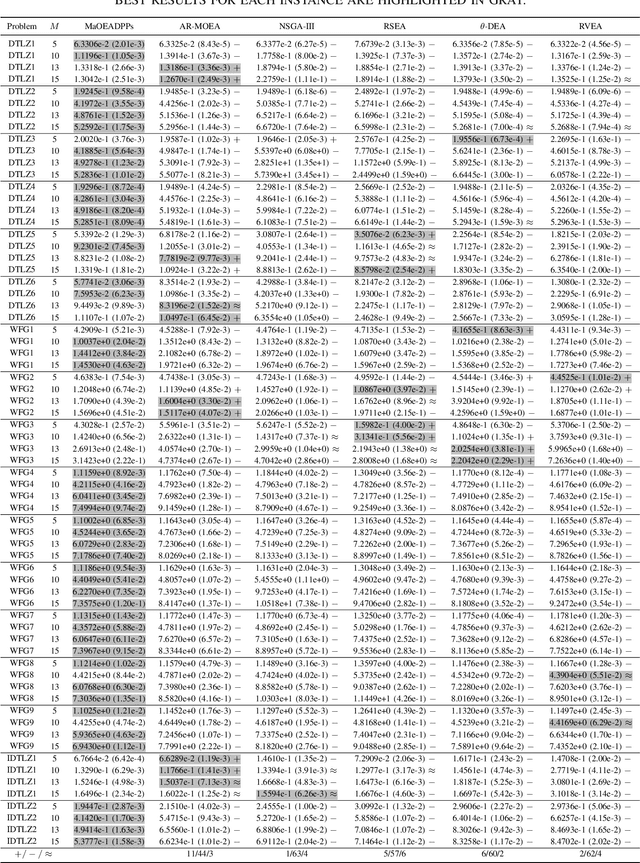
To handle different types of Many-Objective Optimization Problems (MaOPs), Many-Objective Evolutionary Algorithms (MaOEAs) need to simultaneously maintain convergence and population diversity in the high-dimensional objective space. In order to balance the relationship between diversity and convergence, we introduce a Kernel Matrix and probability model called Determinantal Point Processes (DPPs). Our Many-Objective Evolutionary Algorithm with Determinantal Point Processes (MaOEADPPs) is presented and compared with several state-of-the-art algorithms on various types of MaOPs \textcolor{blue}{with different numbers of objectives}. The experimental results demonstrate that MaOEADPPs is competitive.
Likelihood Adaptively Modified Penalties
Aug 23, 2013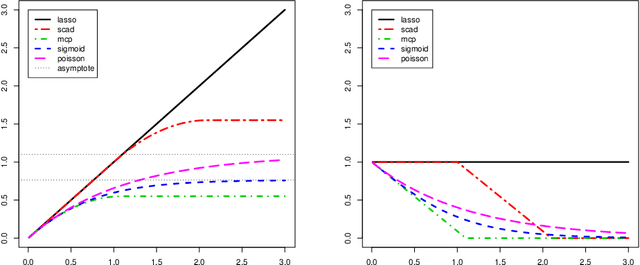
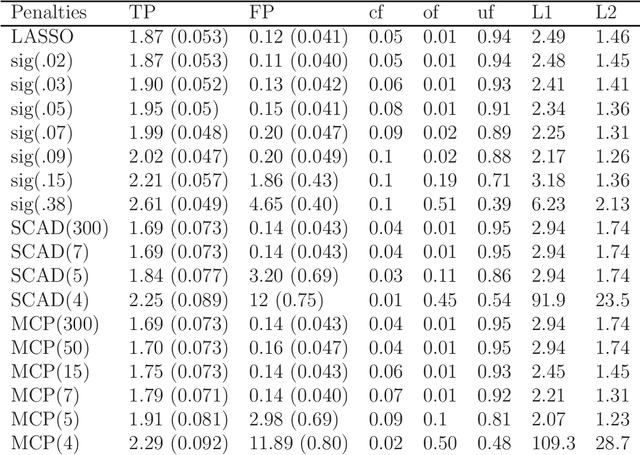
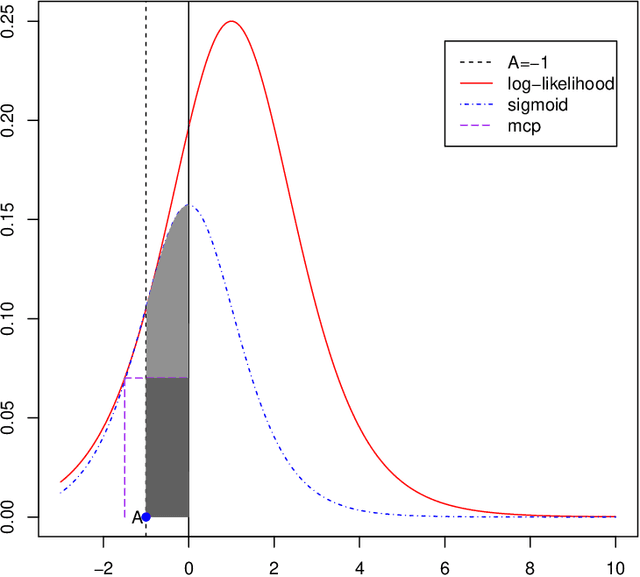
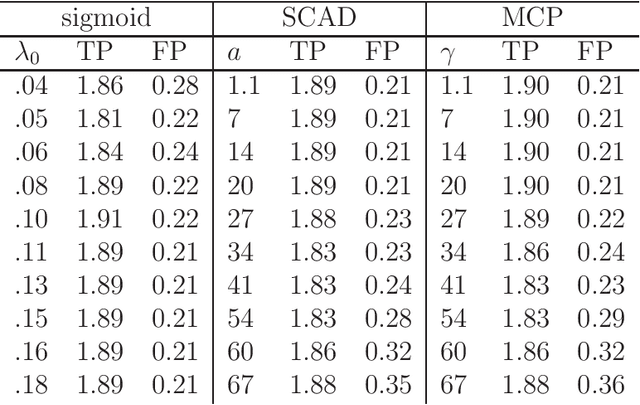
A new family of penalty functions, adaptive to likelihood, is introduced for model selection in general regression models. It arises naturally through assuming certain types of prior distribution on the regression parameters. To study stability properties of the penalized maximum likelihood estimator, two types of asymptotic stability are defined. Theoretical properties, including the parameter estimation consistency, model selection consistency, and asymptotic stability, are established under suitable regularity conditions. An efficient coordinate-descent algorithm is proposed. Simulation results and real data analysis show that the proposed method has competitive performance in comparison with existing ones.