 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Deep Vs. Wide & Deep Learners As Contextual Bandits For Personalized Email Promo Recommendations
Jan 31, 2022



Personalization enables businesses to learn customer preferences from past interactions and thus to target individual customers with more relevant content. We consider the problem of predicting the optimal promotional offer for a given customer out of several options as a contextual bandit problem. Identifying information for the customer and/or the campaign can be used to deduce unknown customer/campaign features that improve optimal offer prediction. Using a generated synthetic email promo dataset, we demonstrate similar prediction accuracies for (a) a wide and deep network that takes identifying information (or other categorical features) as input to the wide part and (b) a deep-only neural network that includes embeddings of categorical features in the input. Improvements in accuracy from including categorical features depends on the variability of the unknown numerical features for each category. We also show that selecting options using upper confidence bound or Thompson sampling, approximated via Monte Carlo dropout layers in the wide and deep models, slightly improves model performance.
Why Are You Weird? Infusing Interpretability in Isolation Forest for Anomaly Detection
Dec 13, 2021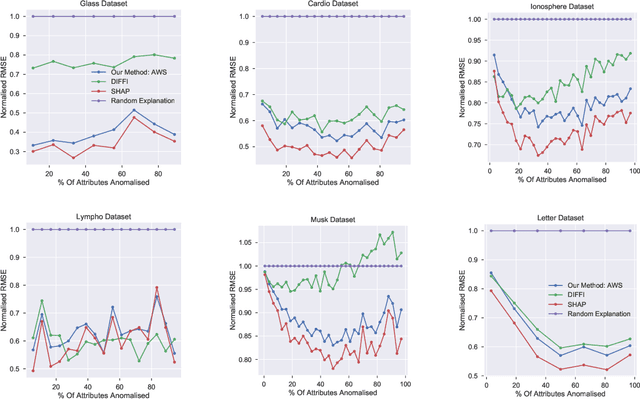
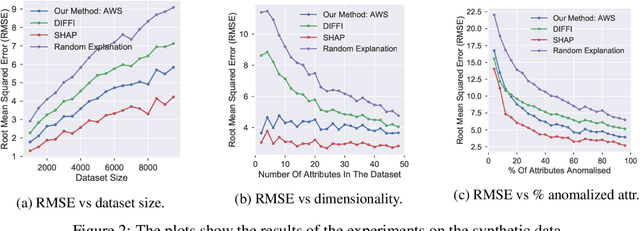
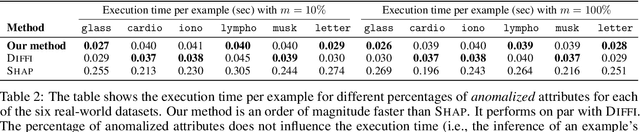
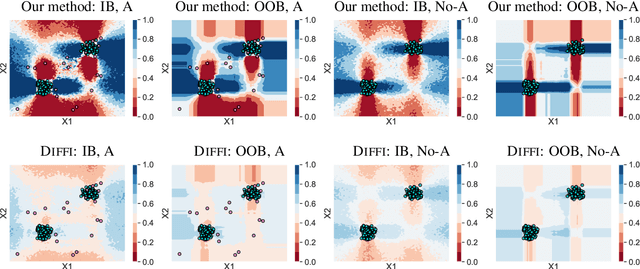
Anomaly detection is concerned with identifying examples in a dataset that do not conform to the expected behaviour. While a vast amount of anomaly detection algorithms exist, little attention has been paid to explaining why these algorithms flag certain examples as anomalies. However, such an explanation could be extremely useful to anyone interpreting the algorithms' output. This paper develops a method to explain the anomaly predictions of the state-of-the-art Isolation Forest anomaly detection algorithm. The method outputs an explanation vector that captures how important each attribute of an example is to identifying it as anomalous. A thorough experimental evaluation on both synthetic and real-world datasets shows that our method is more accurate and more efficient than most contemporary state-of-the-art explainability methods.