 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Are You Weird? Infusing Interpretability in Isolation Forest for Anomaly Detection
Dec 13, 2021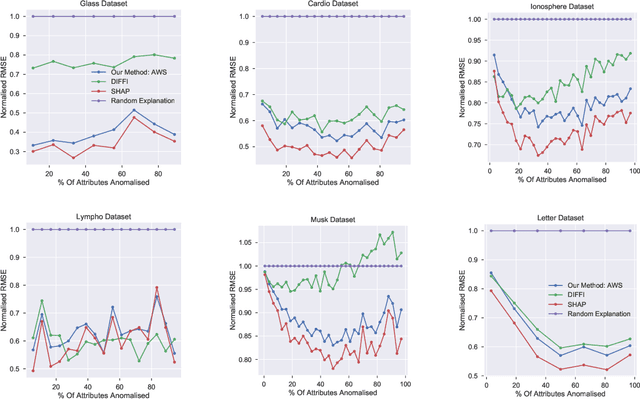
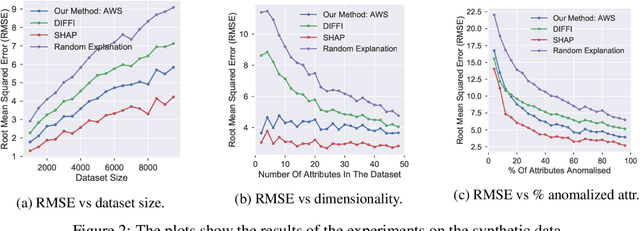
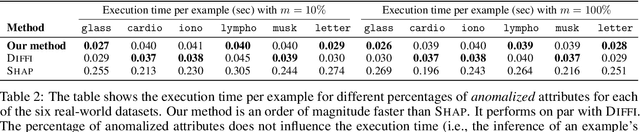
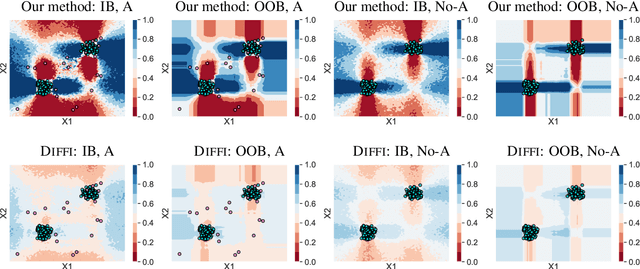
Anomaly detection is concerned with identifying examples in a dataset that do not conform to the expected behaviour. While a vast amount of anomaly detection algorithms exist, little attention has been paid to explaining why these algorithms flag certain examples as anomalies. However, such an explanation could be extremely useful to anyone interpreting the algorithms' output. This paper develops a method to explain the anomaly predictions of the state-of-the-art Isolation Forest anomaly detection algorithm. The method outputs an explanation vector that captures how important each attribute of an example is to identifying it as anomalous. A thorough experimental evaluation on both synthetic and real-world datasets shows that our method is more accurate and more efficient than most contemporary state-of-the-art explainability methods.
Human-Machine Collaboration for Democratizing Data Science
Apr 23, 2020
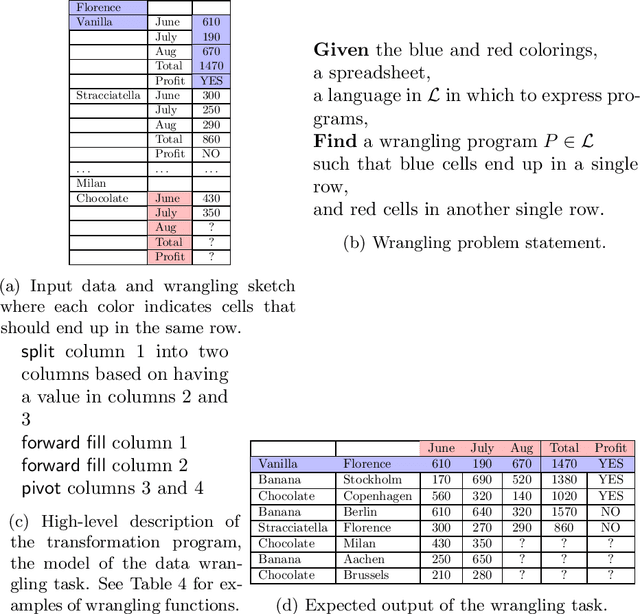
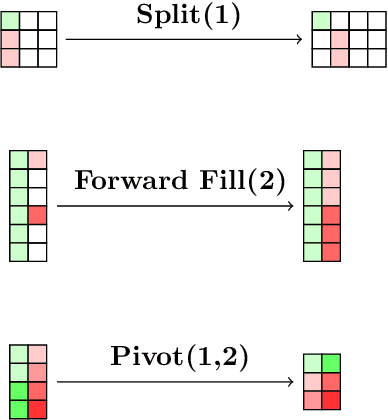
Everybody wants to analyse their data, but only few posses the data science expertise to to this. Motivated by this observation we introduce a novel framework and system \textsc{VisualSynth} for human-machine collaboration in data science. It wants to democratize data science by allowing users to interact with standard spreadsheet software in order to perform and automate various data analysis tasks ranging from data wrangling, data selection, clustering, constraint learning, predictive modeling and auto-completion. \textsc{VisualSynth} relies on the user providing colored sketches, i.e., coloring parts of the spreadsheet, to partially specify data science tasks, which are then determined and executed using artificial intelligence techniques.