 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Validating Synthetic Data for Formula Generation
Jul 15, 2024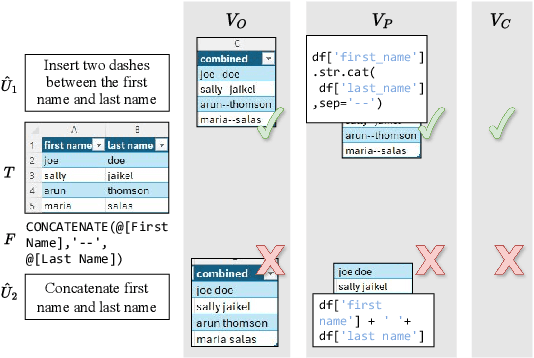
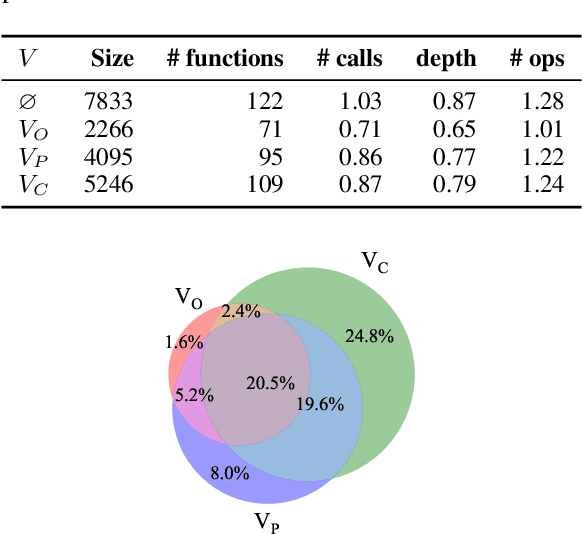
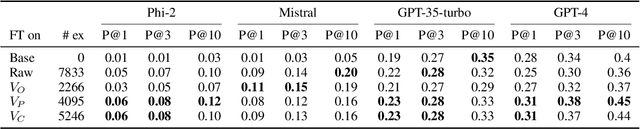
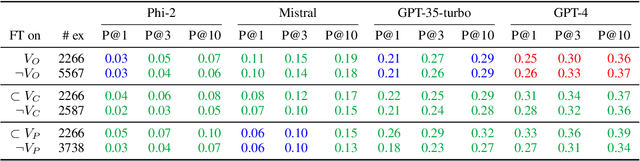
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
Assessing GPT4-V on Structured Reasoning Tasks
Dec 13, 2023Multi-modality promises to unlock further uses for large language models. Recently, the state-of-the-art language model GPT-4 was enhanced with vision capabilities. We carry out a prompting evaluation of GPT-4V and five other baselines on structured reasoning tasks, such as mathematical reasoning, visual data analysis, and code generation. We show that visual Chain-of-Thought, an extension of Chain-of-Thought to multi-modal LLMs, yields significant improvements over the vanilla model. We also present a categorized analysis of scenarios where these models perform well and where they struggle, highlighting challenges associated with coherent multimodal reasoning.
CodeFusion: A Pre-trained Diffusion Model for Code Generation
Nov 01, 2023

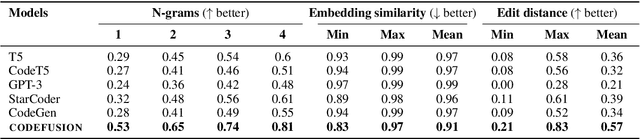

Imagine a developer who can only change their last line of code, how often would they have to start writing a function from scratch before it is correct? Auto-regressive models for code generation from natural language have a similar limitation: they do not easily allow reconsidering earlier tokens generated. We introduce CodeFusion, a pre-trained diffusion code generation model that addresses this limitation by iteratively denoising a complete program conditioned on the encoded natural language. We evaluate CodeFusion on the task of natural language to code generation for Bash, Python, and Microsoft Excel conditional formatting (CF) rules. Experiments show that CodeFusion (75M parameters) performs on par with state-of-the-art auto-regressive systems (350M-175B parameters) in top-1 accuracy and outperforms them in top-3 and top-5 accuracy due to its better balance in diversity versus quality.
FormaT5: Abstention and Examples for Conditional Table Formatting with Natural Language
Nov 01, 2023
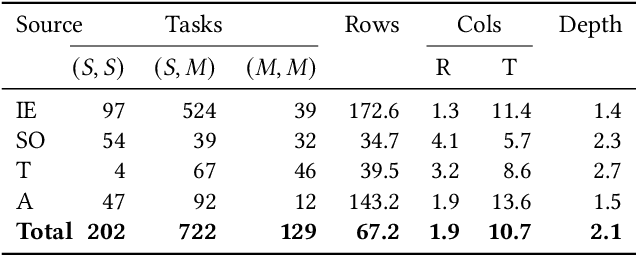

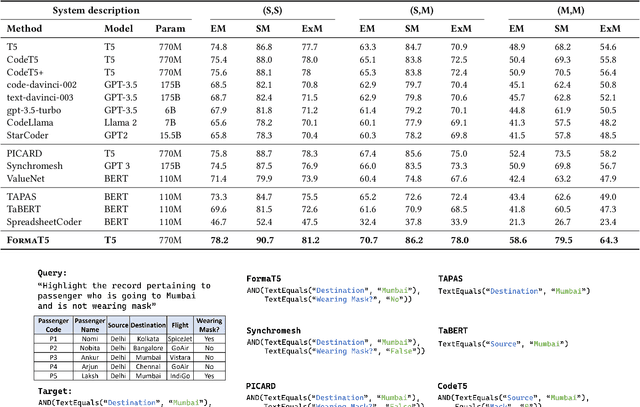
Formatting is an important property in tables for visualization, presentation, and analysis. Spreadsheet software allows users to automatically format their tables by writing data-dependent conditional formatting (CF) rules. Writing such rules is often challenging for users as it requires them to understand and implement the underlying logic. We present FormaT5, a transformer-based model that can generate a CF rule given the target table and a natural language description of the desired formatting logic. We find that user descriptions for these tasks are often under-specified or ambiguous, making it harder for code generation systems to accurately learn the desired rule in a single step. To tackle this problem of under-specification and minimise argument errors, FormaT5 learns to predict placeholders though an abstention objective. These placeholders can then be filled by a second model or, when examples of rows that should be formatted are available, by a programming-by-example system. To evaluate FormaT5 on diverse and real scenarios, we create an extensive benchmark of 1053 CF tasks, containing real-world descriptions collected from four different sources. We release our benchmarks to encourage research in this area. Abstention and filling allow FormaT5 to outperform 8 different neural approaches on our benchmarks, both with and without examples. Our results illustrate the value of building domain-specific learning systems.
TST$^\mathrm{R}$: Target Similarity Tuning Meets the Real World
Oct 28, 2023Target similarity tuning (TST) is a method of selecting relevant examples in natural language (NL) to code generation through large language models (LLMs) to improve performance. Its goal is to adapt a sentence embedding model to have the similarity between two NL inputs match the similarity between their associated code outputs. In this paper, we propose different methods to apply and improve TST in the real world. First, we replace the sentence transformer with embeddings from a larger model, which reduces sensitivity to the language distribution and thus provides more flexibility in synthetic generation of examples, and we train a tiny model that transforms these embeddings to a space where embedding similarity matches code similarity, which allows the model to remain a black box and only requires a few matrix multiplications at inference time. Second, we show how to efficiently select a smaller number of training examples to train the TST model. Third, we introduce a ranking-based evaluation for TST that does not require end-to-end code generation experiments, which can be expensive to perform.
DataVinci: Learning Syntactic and Semantic String Repairs
Aug 21, 2023



String data is common in real-world datasets: 67.6% of values in a sample of 1.8 million real Excel spreadsheets from the web were represented as text. Systems that successfully clean such string data can have a significant impact on real users. While prior work has explored errors in string data, proposed approaches have often been limited to error detection or require that the user provide annotations, examples, or constraints to fix the errors. Furthermore, these systems have focused independently on syntactic errors or semantic errors in strings, but ignore that strings often contain both syntactic and semantic substrings. We introduce DataVinci, a fully unsupervised string data error detection and repair system. DataVinci learns regular-expression-based patterns that cover a majority of values in a column and reports values that do not satisfy such patterns as data errors. DataVinci can automatically derive edits to the data error based on the majority patterns and constraints learned over other columns without the need for further user interaction. To handle strings with both syntactic and semantic substrings, DataVinci uses an LLM to abstract (and re-concretize) portions of strings that are semantic prior to learning majority patterns and deriving edits. Because not all data can result in majority patterns, DataVinci leverages execution information from an existing program (which reads the target data) to identify and correct data repairs that would not otherwise be identified. DataVinci outperforms 7 baselines on both error detection and repair when evaluated on 4 existing and new benchmarks.
Demonstration of CORNET: A System For Learning Spreadsheet Formatting Rules By Example
Aug 14, 2023

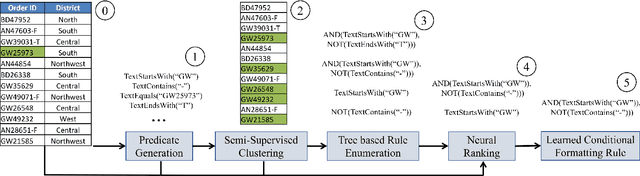

Data management and analysis tasks are often carried out using spreadsheet software. A popular feature in most spreadsheet platforms is the ability to define data-dependent formatting rules. These rules can express actions such as "color red all entries in a column that are negative" or "bold all rows not containing error or failure." Unfortunately, users who want to exercise this functionality need to manually write these conditional formatting (CF) rules. We introduce CORNET, a system that automatically learns such conditional formatting rules from user examples. CORNET takes inspiration from inductive program synthesis and combines symbolic rule enumeration, based on semi-supervised clustering and iterative decision tree learning, with a neural ranker to produce accurate conditional formatting rules. In this demonstration, we show CORNET in action as a simple add-in to Microsoft Excel. After the user provides one or two formatted cells as examples, CORNET generates formatting rule suggestions for the user to apply to the spreadsheet.
FLAME: A small language model for spreadsheet formulas
Jan 31, 2023



The widespread use of spreadsheet environments by billions of users presents a unique opportunity for formula-authoring assistance. Although large language models, such as Codex, can assist in general-purpose languages, they are expensive to train and challenging to deploy due to their large model sizes (up to billions of parameters). Moreover, they require hundreds of gigabytes of training data. We present FLAME, a T5-based model trained on Excel formulas that leverages domain insights to achieve competitive performance with a substantially smaller model (60M parameters) and two orders of magnitude less training data. We curate a training dataset using sketch deduplication, introduce an Excel-specific formula tokenizer for our model, and use domain-specific versions of masked span prediction and noisy auto-encoding as pretraining objectives. We evaluate FLAME on formula repair, formula auto-completion, and a novel task called syntax reconstruction. FLAME (60M) can outperform much larger models, such as Codex-Davinci (175B), Codex-Cushman (12B), and CodeT5 (220M), in 6 out of 10 settings.
Repairing Bugs in Python Assignments Using Large Language Models
Sep 29, 2022

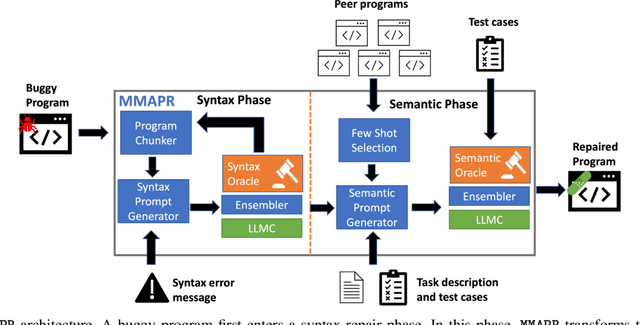

Students often make mistakes on their introductory programming assignments as part of their learning process. Unfortunately, providing custom repairs for these mistakes can require a substantial amount of time and effort from class instructors. Automated program repair (APR) techniques can be used to synthesize such fixes. Prior work has explored the use of symbolic and neural techniques for APR in the education domain. Both types of approaches require either substantial engineering efforts or large amounts of data and training. We propose to use a large language model trained on code, such as Codex, to build an APR system -- MMAPR -- for introductory Python programming assignments. Our system can fix both syntactic and semantic mistakes by combining multi-modal prompts, iterative querying, test-case-based selection of few-shots, and program chunking. We evaluate MMAPR on 286 real student programs and compare to a baseline built by combining a state-of-the-art Python syntax repair engine, BIFI, and state-of-the-art Python semantic repair engine for student assignments, Refactory. We find that MMAPR can fix more programs and produce smaller patches on average.
Repair Is Nearly Generation: Multilingual Program Repair with LLMs
Aug 24, 2022
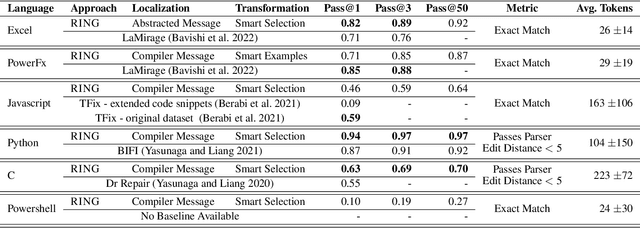

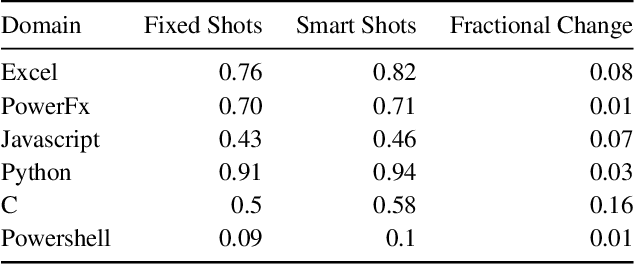
Most programmers make mistakes when writing code. Some of these mistakes are small and require few edits to the original program - a class of errors recently termed last mile mistakes. These errors break the flow for experienced developers and can stump novice programmers. Existing automated repair techniques targeting this class of errors are domain-specific and do not easily carry over to new domains. Transferring symbolic approaches requires substantial engineering and neural approaches require data and retraining. We introduce RING, a multilingual repair engine powered by a large language model trained on code (LLMC) such as Codex. Such a multilingual engine enables a flipped model for programming assistance, one where the programmer writes code and the AI assistance suggests fixes, compared to traditional code suggestion technology. Taking inspiration from the way programmers manually fix bugs, we show that a prompt-based strategy that conceptualizes repair as localization, transformation, and candidate ranking, can successfully repair programs in multiple domains with minimal effort. We present the first results for such a multilingual repair engine by evaluating on 6 different domains and comparing performance to domain-specific repair engines. We show that RING can outperform domain-specific repair engines in 3 of these domains. We also identify directions for future research using LLMCs for multilingual repair.