 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerchMobi^3: A Multi-Modal Robot with Power-Reuse Quad-Fan Mechanism for Air-Ground-Wall Locomotion
Sep 16, 2025Achieving seamless integration of aerial flight, ground driving, and wall climbing within a single robotic platform remains a major challenge, as existing designs often rely on additional adhesion actuators that increase complexity, reduce efficiency, and compromise reliability. To address these limitations, we present PerchMobi^3, a quad-fan, negative-pressure, air-ground-wall robot that implements a propulsion-adhesion power-reuse mechanism. By repurposing four ducted fans to simultaneously provide aerial thrust and negative-pressure adhesion, and integrating them with four actively driven wheels, PerchMobi^3 eliminates dedicated pumps while maintaining a lightweight and compact design. To the best of our knowledge, this is the first quad-fan prototype to demonstrate functional power reuse for multi-modal locomotion. A modeling and control framework enables coordinated operation across ground, wall, and aerial domains with fan-assisted transitions. The feasibility of the design is validated through a comprehensive set of experiments covering ground driving, payload-assisted wall climbing, aerial flight, and cross-mode transitions, demonstrating robust adaptability across locomotion scenarios. These results highlight the potential of PerchMobi^3 as a novel design paradigm for multi-modal robotic mobility, paving the way for future extensions toward autonomous and application-oriented deployment.
Integer Linear Programming Preprocessing for Maximum Satisfiability
Jun 06, 2025

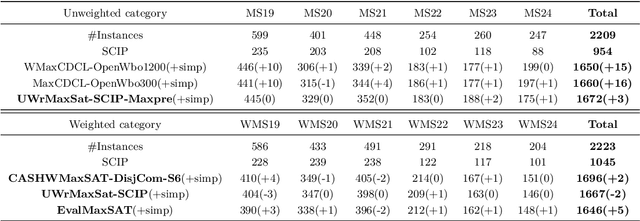

The Maximum Satisfiability problem (MaxSAT) is a major optimization challenge with numerous practical applications. In recent MaxSAT evaluations, most MaxSAT solvers have adopted an ILP solver as part of their portfolios. This paper investigates the impact of Integer Linear Programming (ILP) preprocessing techniques on MaxSAT solving. Experimental results show that ILP preprocessing techniques help WMaxCDCL-OpenWbo1200, the winner of the MaxSAT evaluation 2024 in the unweighted track, solve 15 additional instances. Moreover, current state-of-the-art MaxSAT solvers heavily use an ILP solver in their portfolios, while our proposed approach reduces the need to call an ILP solver in a portfolio including WMaxCDCL or MaxCDCL.
TransMA: an explainable multi-modal deep learning model for predicting properties of ionizable lipid nanoparticles in mRNA delivery
Jul 08, 2024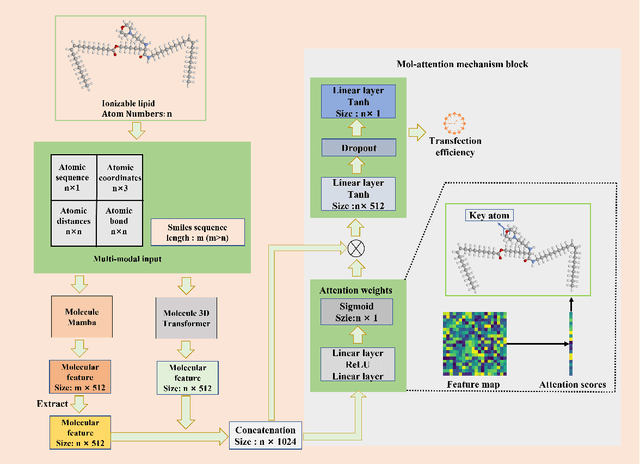
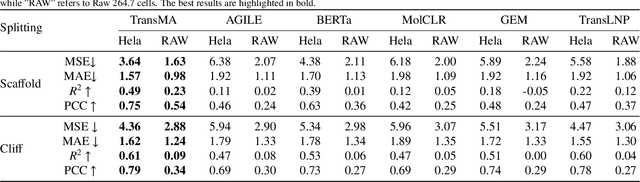


As the primary mRNA delivery vehicles, ionizable lipid nanoparticles (LNPs) exhibit excellent safety, high transfection efficiency, and strong immune response induction. However, the screening process for LNPs is time-consuming and costly. To expedite the identification of high-transfection-efficiency mRNA drug delivery systems, we propose an explainable LNPs transfection efficiency prediction model, called TransMA. TransMA employs a multi-modal molecular structure fusion architecture, wherein the fine-grained atomic spatial relationship extractor named molecule 3D Transformer captures three-dimensional spatial features of the molecule, and the coarse-grained atomic sequence extractor named molecule Mamba captures one-dimensional molecular features. We design the mol-attention mechanism block, enabling it to align coarse and fine-grained atomic features and captures relationships between atomic spatial and sequential structures. TransMA achieves state-of-the-art performance in predicting transfection efficiency using the scaffold and cliff data splitting methods on the current largest LNPs dataset, including Hela and RAW cell lines. Moreover, we find that TransMA captures the relationship between subtle structural changes and significant transfection efficiency variations, providing valuable insights for LNPs design. Additionally, TransMA's predictions on external transfection efficiency data maintain a consistent order with actual transfection efficiencies, demonstrating its robust generalization capability. The code, model and data are made publicly available at https://github.com/wklix/TransMA/tree/master. We hope that high-accuracy transfection prediction models in the future can aid in LNPs design and initial screening, thereby assisting in accelerating the mRNA design process.
Scale Optimization Using Evolutionary Reinforcement Learning for Object Detection on Drone Imagery
Dec 23, 2023Object detection in aerial imagery presents a significant challenge due to large scale variations among objects. This paper proposes an evolutionary reinforcement learning agent, integrated within a coarse-to-fine object detection framework, to optimize the scale for more effective detection of objects in such images. Specifically, a set of patches potentially containing objects are first generated. A set of rewards measuring the localization accuracy, the accuracy of predicted labels, and the scale consistency among nearby patches are designed in the agent to guide the scale optimization. The proposed scale-consistency reward ensures similar scales for neighboring objects of the same category. Furthermore, a spatial-semantic attention mechanism is designed to exploit the spatial semantic relations between patches. The agent employs the proximal policy optimization strategy in conjunction with the evolutionary strategy, effectively utilizing both the current patch status and historical experience embedded in the agent. The proposed model is compared with state-of-the-art methods on two benchmark datasets for object detection on drone imagery. It significantly outperforms all the compared methods.
Repairing Bugs in Python Assignments Using Large Language Models
Sep 29, 2022

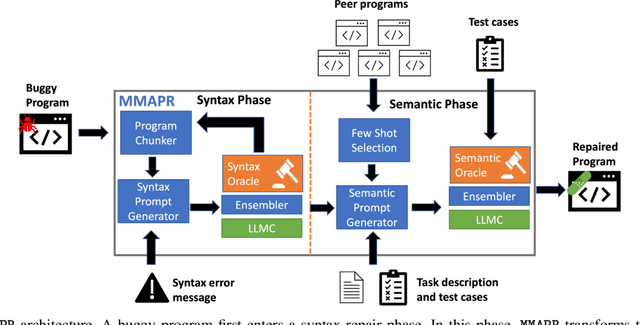

Students often make mistakes on their introductory programming assignments as part of their learning process. Unfortunately, providing custom repairs for these mistakes can require a substantial amount of time and effort from class instructors. Automated program repair (APR) techniques can be used to synthesize such fixes. Prior work has explored the use of symbolic and neural techniques for APR in the education domain. Both types of approaches require either substantial engineering efforts or large amounts of data and training. We propose to use a large language model trained on code, such as Codex, to build an APR system -- MMAPR -- for introductory Python programming assignments. Our system can fix both syntactic and semantic mistakes by combining multi-modal prompts, iterative querying, test-case-based selection of few-shots, and program chunking. We evaluate MMAPR on 286 real student programs and compare to a baseline built by combining a state-of-the-art Python syntax repair engine, BIFI, and state-of-the-art Python semantic repair engine for student assignments, Refactory. We find that MMAPR can fix more programs and produce smaller patches on average.
Spatial-context-aware deep neural network for multi-class image classification
Nov 24, 2021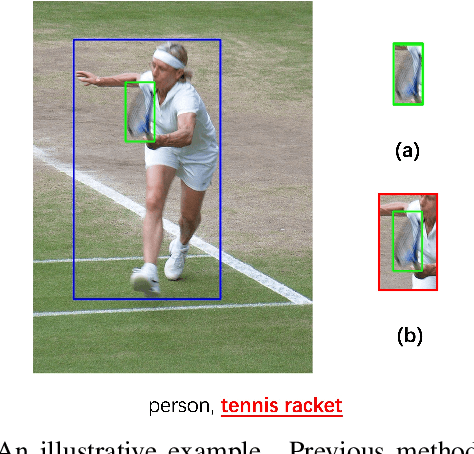
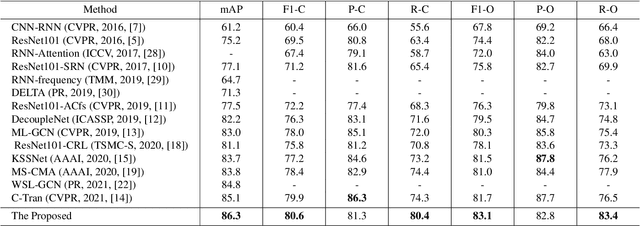
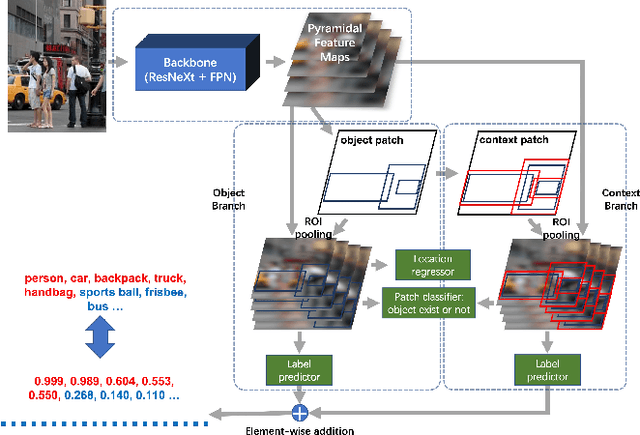

Multi-label image classification is a fundamental but challenging task in computer vision. Over the past few decades, solutions exploring relationships between semantic labels have made great progress. However, the underlying spatial-contextual information of labels is under-exploited. To tackle this problem, a spatial-context-aware deep neural network is proposed to predict labels taking into account both semantic and spatial information. This proposed framework is evaluated on Microsoft COCO and PASCAL VOC, two widely used benchmark datasets for image multi-labelling. The results show that the proposed approach is superior to the state-of-the-art solutions on dealing with the multi-label image classification problem.
A Data Augmentation Method by Mixing Up Negative Candidate Answers for Solving Raven's Progressive Matrices
Mar 09, 2021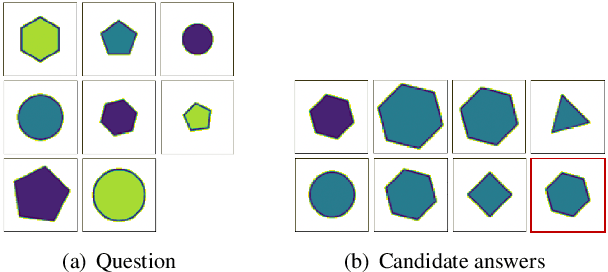

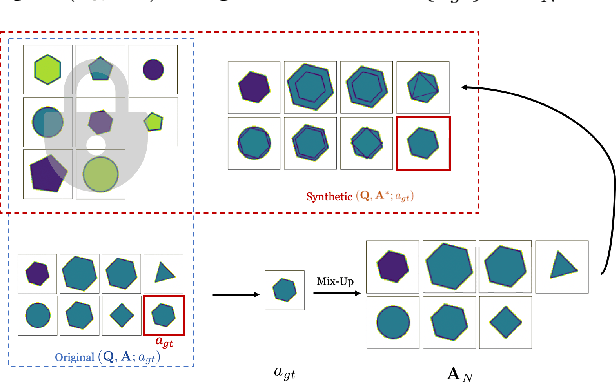
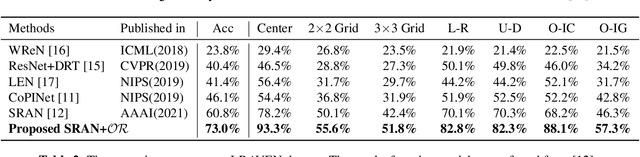
Raven's Progressive Matrices (RPMs) are frequently-used in testing human's visual reasoning ability. Recently developed RPM-like datasets and solution models transfer this kind of problems from cognitive science to computer science. In view of the poor generalization performance due to insufficient samples in RPM datasets, we propose a data augmentation strategy by image mix-up, which is generalizable to a variety of multiple-choice problems, especially for image-based RPM-like problems. By focusing on potential functionalities of negative candidate answers, the visual reasoning capability of the model is enhanced. By applying the proposed data augmentation method, we achieve significant and consistent improvement on various RPM-like datasets compared with the state-of-the-art models.
Succinct Explanations With Cascading Decision Trees
Oct 13, 2020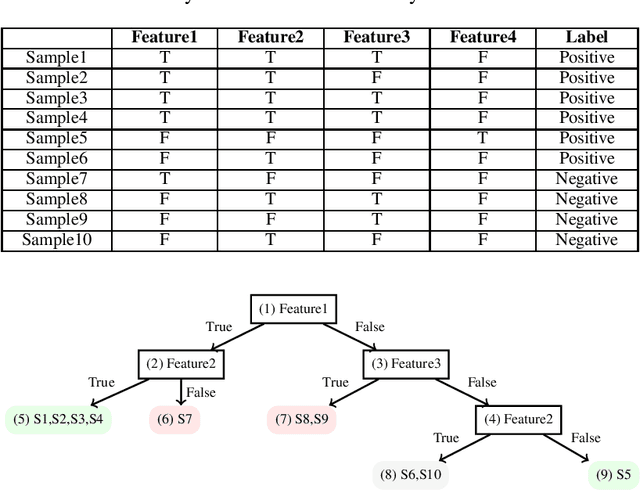
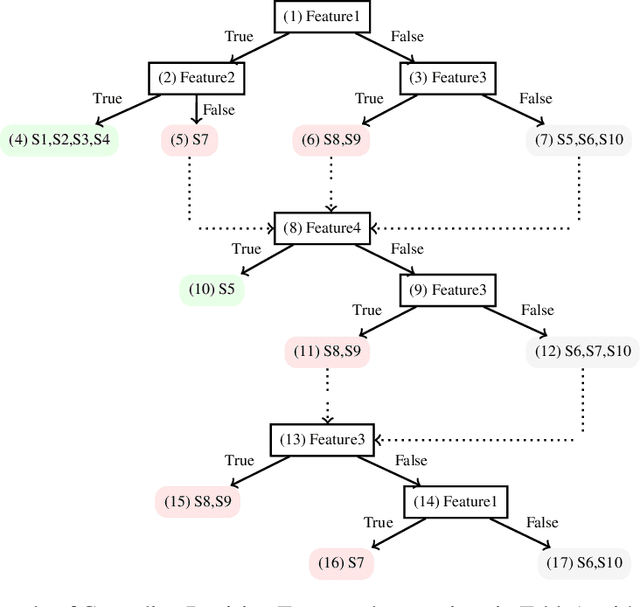

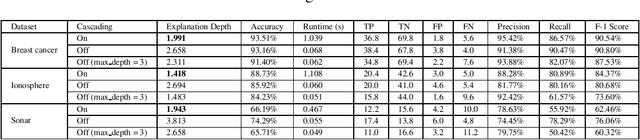
Classic decision tree learning is a binary classification algorithm that constructs models with first-class transparency - every classification has a directly derivable explanation. However, learning decision trees on modern datasets generates large trees, which in turn generate decision paths of excessive depth, obscuring the explanation of classifications. To improve the comprehensibility of classifications, we propose a new decision tree model that we call Cascading Decision Trees. Cascading Decision Trees shorten the size of explanations of classifications, without sacrificing model performance overall. Our key insight is to separate the notion of a decision path and an explanation path. Utilizing this insight, instead of having one monolithic decision tree, we build several smaller decision subtrees and cascade them in sequence. Our cascading decision subtrees are designed to specifically target explanations for positive classifications. This way each subtree identifies the smallest set of features that can classify as many positive samples as possible, without misclassifying any negative samples. Applying cascading decision trees to new samples results in a significantly shorter and succinct explanation, if one of the subtrees detects a positive classification. In that case, we immediately stop and report the decision path of only the current subtree to the user as an explanation for the classification. We evaluate our algorithm on standard datasets, as well as new real-world applications and find that our model shortens the explanation depth by over 40.8% for positive classifications compared to the classic decision tree model.