 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and Framework for Evaluating Next Action Predictions in Spreadsheets
Jun 11, 2026Predictive code completion greatly accelerates how quickly developers work. In spreadsheets, despite being much more common, such auto-completion features are virtually non-existent. To address this gap, we introduce a benchmark for systems that observe a sequence of user actions in a spreadsheet and predict future actions. Two challenges are (1) the absence of edit histories in public spreadsheet corpora and (2) the complex space of spreadsheet actions (spatial, temporal, composite). To address (1), we manually curate 52 sequences of 12K actions that recreate spreadsheets from public corpora, seeded by parametrized heuristics and LLM refinement. To address (2), we propose an online evaluation that expects a prediction after each user action, accepts or rejects that prediction, updates the future actions upon acceptance, and repeats this until the target spreadsheet is obtained. We use multiple baseline predictors (including zero-shot LLMs, fine-tuned SLMs, and classical models) and analyze different properties that our benchmark teaches us, including but not limited to: properties of saved actions and false positives, efficiency, effect of user profiles, effect of triggers, and effect of context.
Auditing and Controlling AI Agent Actions in Spreadsheets
Apr 22, 2026Advances in AI agent capabilities have outpaced users' ability to meaningfully oversee their execution. AI agents can perform sophisticated, multi-step knowledge work autonomously from start to finish, yet this process remains effectively inaccessible during execution, often buried within large volumes of intermediate reasoning and outputs: by the time users receive the output, all underlying decisions have already been made without their involvement. This lack of transparency leaves users unable to examine the agent's assumptions, identify errors before they propagate, or redirect execution when it deviates from their intent. The stakes are particularly high in spreadsheet environments, where process and artifact are inseparable. Each decision the agent makes is recorded directly in cells that belong to and reflect on the user. We introduce Pista, a spreadsheet AI agent that decomposes execution into auditable, controllable actions, providing users with visibility into the agent's decision-making process and the capacity to intervene at each step. A formative study (N = 8) and a within-subjects summative evaluation (N = 16) comparing Pista to a baseline agent demonstrated that active participation in execution influenced not only task outcomes but also users' comprehension of the task, their perception of the agent, and their sense of role within the workflow. Users identified their own intent reflected in the agent's actions, detected errors that post-hoc review would have failed to surface, and reported a sense of co-ownership over the resulting output. These findings indicate that meaningful human oversight of AI agents in knowledge work requires not improved post-hoc review mechanisms, but active participation in decisions as they are made.
An Empirical Investigation of Robustness in Large Language Models under Tabular Distortions
Jan 08, 2026We investigate how large language models (LLMs) fail when tabular data in an otherwise canonical representation is subjected to semantic and structural distortions. Our findings reveal that LLMs lack an inherent ability to detect and correct subtle distortions in table representations. Only when provided with an explicit prior, via a system prompt, do models partially adjust their reasoning strategies and correct some distortions, though not consistently or completely. To study this phenomenon, we introduce a small, expert-curated dataset that explicitly evaluates LLMs on table question answering (TQA) tasks requiring an additional error-correction step prior to analysis. Our results reveal systematic differences in how LLMs ingest and interpret tabular information under distortion, with even SoTA models such as GPT-5.2 model exhibiting a drop of minimum 22% accuracy under distortion. These findings raise important questions for future research, particularly regarding when and how models should autonomously decide to realign tabular inputs, analogous to human behavior, without relying on explicit prompts or tabular data pre-processing.
Exploration vs. Fixation: Scaffolding Divergent and Convergent Thinking for Human-AI Co-Creation with Generative Models
Dec 20, 2025Generative AI has begun to democratize creative work, enabling novices to produce complex artifacts such as code, images, and videos. However, in practice, existing interaction paradigms often fail to support divergent exploration: users tend to converge too quickly on early ``good enough'' results and struggle to move beyond them, leading to premature convergence and design fixation that constrains their creative potential. To address this, we propose a structured, process-oriented human-AI co-creation paradigm including divergent and convergent thinking stages, grounded in Wallas's model of creativity. To avoid design fixation, our paradigm scaffolds both high-level exploration of conceptual ideas in the early divergent thinking phase and low-level exploration of variations in the later convergent thinking phrase. We instantiate this paradigm in HAIExplore, an image co-creation system that (i) scaffolds divergent thinking through a dedicated brainstorming stage for exploring high-level ideas in a conceptual space, and (ii) scaffolds convergent refinement through an interface that externalizes users' refinement intentions as interpretable parameters and options, making the refinement process more controllable and easier to explore. We report on a within-subjects study comparing HAIExplore with a widely used linear chat interface (ChatGPT) for creative image generation. Our findings show that explicitly scaffolding the creative process into brainstorming and refinement stages can mitigate design fixation, improve perceived controllability and alignment with users' intentions, and better support the non-linear nature of creative work. We conclude with design implications for future creativity support tools and human-AI co-creation workflows.
Collaboration and Conflict between Humans and Language Models through the Lens of Game Theory
Sep 05, 2025Language models are increasingly deployed in interactive online environments, from personal chat assistants to domain-specific agents, raising questions about their cooperative and competitive behavior in multi-party settings. While prior work has examined language model decision-making in isolated or short-term game-theoretic contexts, these studies often neglect long-horizon interactions, human-model collaboration, and the evolution of behavioral patterns over time. In this paper, we investigate the dynamics of language model behavior in the iterated prisoner's dilemma (IPD), a classical framework for studying cooperation and conflict. We pit model-based agents against a suite of 240 well-established classical strategies in an Axelrod-style tournament and find that language models achieve performance on par with, and in some cases exceeding, the best-known classical strategies. Behavioral analysis reveals that language models exhibit key properties associated with strong cooperative strategies - niceness, provocability, and generosity while also demonstrating rapid adaptability to changes in opponent strategy mid-game. In controlled "strategy switch" experiments, language models detect and respond to shifts within only a few rounds, rivaling or surpassing human adaptability. These results provide the first systematic characterization of long-term cooperative behaviors in language model agents, offering a foundation for future research into their role in more complex, mixed human-AI social environments.
STACKFEED: Structured Textual Actor-Critic Knowledge Base Editing with FeedBack
Oct 14, 2024Large Language Models (LLMs) often generate incorrect or outdated information, especially in low-resource settings or when dealing with private data. To address this, Retrieval-Augmented Generation (RAG) uses external knowledge bases (KBs), but these can also suffer from inaccuracies. We introduce STACKFEED, a novel Structured Textual Actor-Critic Knowledge base editing with FEEDback approach that iteratively refines the KB based on expert feedback using a multi-actor, centralized critic reinforcement learning framework. Each document is assigned to an actor, modeled as a ReACT agent, which performs structured edits based on document-specific targeted instructions from a centralized critic. Experimental results show that STACKFEED significantly improves KB quality and RAG system performance, enhancing accuracy by up to 8% over baselines.
An Empirical Study of Validating Synthetic Data for Formula Generation
Jul 15, 2024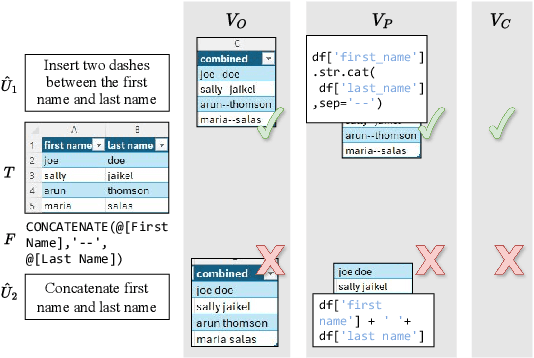
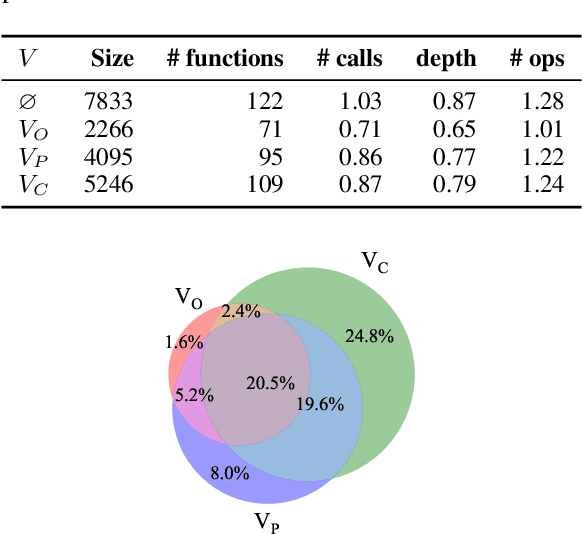
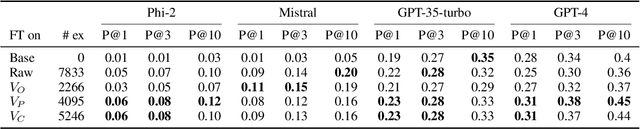
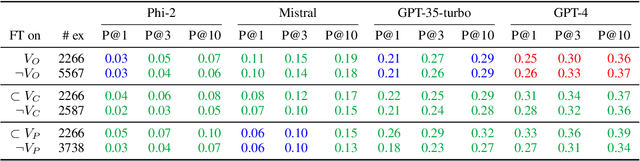
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
Enhancing Creativity in Large Language Models through Associative Thinking Strategies
May 09, 2024
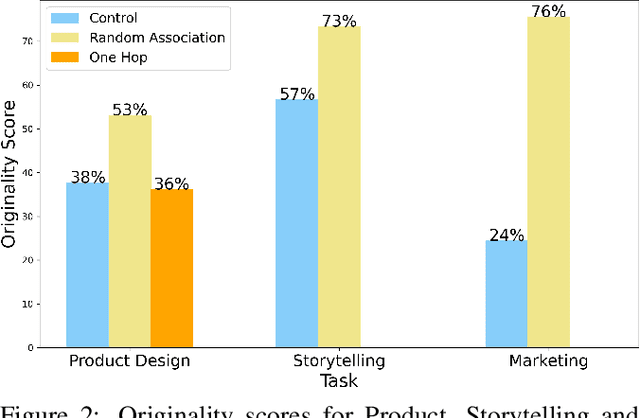


This paper explores the enhancement of creativity in Large Language Models (LLMs) like vGPT-4 through associative thinking, a cognitive process where creative ideas emerge from linking seemingly unrelated concepts. Associative thinking strategies have been found to effectively help humans boost creativity. However, whether the same strategies can help LLMs become more creative remains under-explored. In this work, we investigate whether prompting LLMs to connect disparate concepts can augment their creative outputs. Focusing on three domains -- Product Design, Storytelling, and Marketing -- we introduce creativity tasks designed to assess vGPT-4's ability to generate original and useful content. By challenging the models to form novel associations, we evaluate the potential of associative thinking to enhance the creative capabilities of LLMs. Our findings show that leveraging associative thinking techniques can significantly improve the originality of vGPT-4's responses.
Exploring Interaction Patterns for Debugging: Enhancing Conversational Capabilities of AI-assistants
Feb 09, 2024



The widespread availability of Large Language Models (LLMs) within Integrated Development Environments (IDEs) has led to their speedy adoption. Conversational interactions with LLMs enable programmers to obtain natural language explanations for various software development tasks. However, LLMs often leap to action without sufficient context, giving rise to implicit assumptions and inaccurate responses. Conversations between developers and LLMs are primarily structured as question-answer pairs, where the developer is responsible for asking the the right questions and sustaining conversations across multiple turns. In this paper, we draw inspiration from interaction patterns and conversation analysis -- to design Robin, an enhanced conversational AI-assistant for debugging. Through a within-subjects user study with 12 industry professionals, we find that equipping the LLM to -- (1) leverage the insert expansion interaction pattern, (2) facilitate turn-taking, and (3) utilize debugging workflows -- leads to lowered conversation barriers, effective fault localization, and 5x improvement in bug resolution rates.
Generative AI for Education (GAIED): Advances, Opportunities, and Challenges
Feb 07, 2024This survey article has grown out of the GAIED (pronounced "guide") workshop organized by the authors at the NeurIPS 2023 conference. We organized the GAIED workshop as part of a community-building effort to bring together researchers, educators, and practitioners to explore the potential of generative AI for enhancing education. This article aims to provide an overview of the workshop activities and highlight several future research directions in the area of GAIED.