 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Safeguards for Safe and Model-Agnostic Reinforcement Learning
Oct 31, 2024In this paper we propose a formal, model-agnostic meta-learning framework for safe reinforcement learning. Our framework is inspired by how parents safeguard their children across a progression of increasingly riskier tasks, imparting a sense of safety that is carried over from task to task. We model this as a meta-learning process where each task is synchronized with a safeguard that monitors safety and provides a reward signal to the agent. The safeguard is implemented as a finite-state machine based on a safety specification; the reward signal is formally shaped around this specification. The safety specification and its corresponding safeguard can be arbitrarily complex and non-Markovian, which adds flexibility to the training process and explainability to the learned policy. The design of the safeguard is manual but it is high-level and model-agnostic, which gives rise to an end-to-end safe learning approach with wide applicability, from pixel-level game control to language model fine-tuning. Starting from a given set of safety specifications (tasks), we train a model such that it can adapt to new specifications using only a small number of training samples. This is made possible by our method for efficiently transferring safety bias between tasks, which effectively minimizes the number of safety violations. We evaluate our framework in a Minecraft-inspired Gridworld, a VizDoom game environment, and an LLM fine-tuning application. Agents trained with our approach achieve near-minimal safety violations, while baselines are shown to underperform.
STACKFEED: Structured Textual Actor-Critic Knowledge Base Editing with FeedBack
Oct 14, 2024Large Language Models (LLMs) often generate incorrect or outdated information, especially in low-resource settings or when dealing with private data. To address this, Retrieval-Augmented Generation (RAG) uses external knowledge bases (KBs), but these can also suffer from inaccuracies. We introduce STACKFEED, a novel Structured Textual Actor-Critic Knowledge base editing with FEEDback approach that iteratively refines the KB based on expert feedback using a multi-actor, centralized critic reinforcement learning framework. Each document is assigned to an actor, modeled as a ReACT agent, which performs structured edits based on document-specific targeted instructions from a centralized critic. Experimental results show that STACKFEED significantly improves KB quality and RAG system performance, enhancing accuracy by up to 8% over baselines.
Guiding Language Models of Code with Global Context using Monitors
Jun 19, 2023
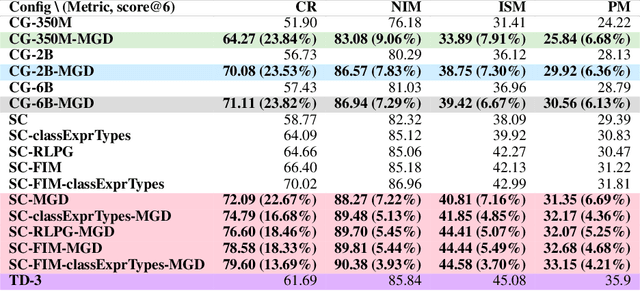
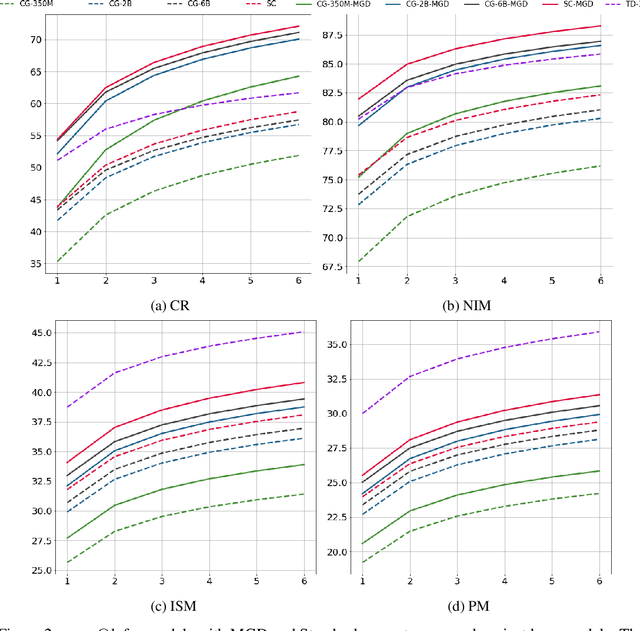
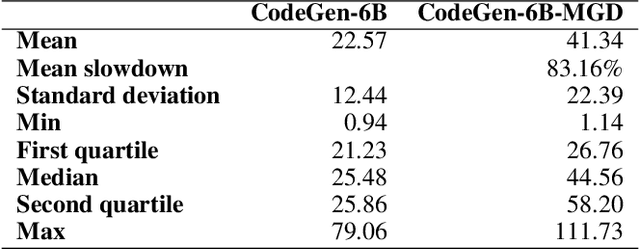
Language models of code (LMs) work well when the surrounding code in the vicinity of generation provides sufficient context. This is not true when it becomes necessary to use types or functionality defined in another module or library, especially those not seen during training. LMs suffer from limited awareness of such global context and end up hallucinating, e.g., using types defined in other files incorrectly. Recent work tries to overcome this issue by retrieving global information to augment the local context. However, this bloats the prompt or requires architecture modifications and additional training. Integrated development environments (IDEs) assist developers by bringing the global context at their fingertips using static analysis. We extend this assistance, enjoyed by developers, to the LMs. We propose a notion of monitors that use static analysis in the background to guide the decoding. Unlike a priori retrieval, static analysis is invoked iteratively during the entire decoding process, providing the most relevant suggestions on demand. We demonstrate the usefulness of our proposal by monitoring for type-consistent use of identifiers whenever an LM generates code for object dereference. To evaluate our approach, we curate PragmaticCode, a dataset of open-source projects with their development environments. On models of varying parameter scale, we show that monitor-guided decoding consistently improves the ability of an LM to not only generate identifiers that match the ground truth but also improves compilation rates and agreement with ground truth. We find that LMs with fewer parameters, when guided with our monitor, can outperform larger LMs. With monitor-guided decoding, SantaCoder-1.1B achieves better compilation rate and next-identifier match than the much larger text-davinci-003 model. The datasets and code will be released at https://aka.ms/monitors4codegen .