 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Label Training Preserves Epistemic Uncertainty
Nov 18, 2025Many machine learning tasks involve inherent subjectivity, where annotators naturally provide varied labels. Standard practice collapses these label distributions into single labels, aggregating diverse human judgments into point estimates. We argue that this approach is epistemically misaligned for ambiguous data--the annotation distribution itself should be regarded as the ground truth. Training on collapsed single labels forces models to express false confidence on fundamentally ambiguous cases, creating a misalignment between model certainty and the diversity of human perception. We demonstrate empirically that soft-label training, which treats annotation distributions as ground truth, preserves epistemic uncertainty. Across both vision and NLP tasks, soft-label training achieves 32% lower KL divergence from human annotations and 61% stronger correlation between model and annotation entropy, while matching the accuracy of hard-label training. Our work repositions annotation distributions from noisy signals to be aggregated away, to faithful representations of epistemic uncertainty that models should learn to reproduce.
STACKFEED: Structured Textual Actor-Critic Knowledge Base Editing with FeedBack
Oct 14, 2024Large Language Models (LLMs) often generate incorrect or outdated information, especially in low-resource settings or when dealing with private data. To address this, Retrieval-Augmented Generation (RAG) uses external knowledge bases (KBs), but these can also suffer from inaccuracies. We introduce STACKFEED, a novel Structured Textual Actor-Critic Knowledge base editing with FEEDback approach that iteratively refines the KB based on expert feedback using a multi-actor, centralized critic reinforcement learning framework. Each document is assigned to an actor, modeled as a ReACT agent, which performs structured edits based on document-specific targeted instructions from a centralized critic. Experimental results show that STACKFEED significantly improves KB quality and RAG system performance, enhancing accuracy by up to 8% over baselines.
LOGIC-LM++: Multi-Step Refinement for Symbolic Formulations
Jul 04, 2024In this paper we examine the limitations of Large Language Models (LLMs) for complex reasoning tasks. Although recent works have started to employ formal languages as an intermediate representation for reasoning tasks, they often face challenges in accurately generating and refining these formal specifications to ensure correctness. To address these issues, this paper proposes Logic-LM++, an improvement on Logic-LM . It uses the ability of LLMs to do pairwise comparisons, allowing the evaluation of the refinements suggested by the LLM. The paper demonstrates that Logic-LM++ outperforms Logic-LM and other contemporary techniques across natural language reasoning tasks on three datasets, FOLIO, ProofWriter and AR-LSAT, with an average improvement of 18.5% on standard prompting, 12.3% on chain of thought prompting and 5% on Logic-LM.
TST$^\mathrm{R}$: Target Similarity Tuning Meets the Real World
Oct 28, 2023Target similarity tuning (TST) is a method of selecting relevant examples in natural language (NL) to code generation through large language models (LLMs) to improve performance. Its goal is to adapt a sentence embedding model to have the similarity between two NL inputs match the similarity between their associated code outputs. In this paper, we propose different methods to apply and improve TST in the real world. First, we replace the sentence transformer with embeddings from a larger model, which reduces sensitivity to the language distribution and thus provides more flexibility in synthetic generation of examples, and we train a tiny model that transforms these embeddings to a space where embedding similarity matches code similarity, which allows the model to remain a black box and only requires a few matrix multiplications at inference time. Second, we show how to efficiently select a smaller number of training examples to train the TST model. Third, we introduce a ranking-based evaluation for TST that does not require end-to-end code generation experiments, which can be expensive to perform.
Augmented Embeddings for Custom Retrievals
Oct 09, 2023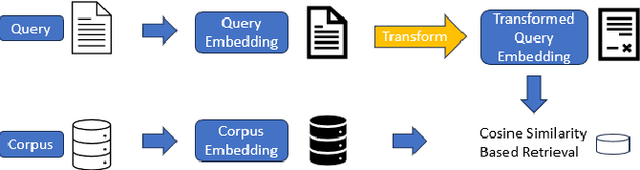



Information retrieval involves selecting artifacts from a corpus that are most relevant to a given search query. The flavor of retrieval typically used in classical applications can be termed as homogeneous and relaxed, where queries and corpus elements are both natural language (NL) utterances (homogeneous) and the goal is to pick most relevant elements from the corpus in the Top-K, where K is large, such as 10, 25, 50 or even 100 (relaxed). Recently, retrieval is being used extensively in preparing prompts for large language models (LLMs) to enable LLMs to perform targeted tasks. These new applications of retrieval are often heterogeneous and strict -- the queries and the corpus contain different kinds of entities, such as NL and code, and there is a need for improving retrieval at Top-K for small values of K, such as K=1 or 3 or 5. Current dense retrieval techniques based on pretrained embeddings provide a general-purpose and powerful approach for retrieval, but they are oblivious to task-specific notions of similarity of heterogeneous artifacts. We introduce Adapted Dense Retrieval, a mechanism to transform embeddings to enable improved task-specific, heterogeneous and strict retrieval. Adapted Dense Retrieval works by learning a low-rank residual adaptation of the pretrained black-box embedding. We empirically validate our approach by showing improvements over the state-of-the-art general-purpose embeddings-based baseline.
GrACE: Generation using Associated Code Edits
May 24, 2023



Developers expend a significant amount of time in editing code for a variety of reasons such as bug fixing or adding new features. Designing effective methods to predict code edits has been an active yet challenging area of research due to the diversity of code edits and the difficulty of capturing the developer intent. In this work, we address these challenges by endowing pre-trained large language models (LLMs) of code with the knowledge of prior, relevant edits. The generative capability of the LLMs helps address the diversity in code changes and conditioning code generation on prior edits helps capture the latent developer intent. We evaluate two well-known LLMs, Codex and CodeT5, in zero-shot and fine-tuning settings respectively. In our experiments with two datasets, the knowledge of prior edits boosts the performance of the LLMs significantly and enables them to generate 29% and 54% more correctly edited code in top-1 suggestions relative to the current state-of-the-art symbolic and neural approaches, respectively.
Overwatch: Learning Patterns in Code Edit Sequences
Jul 25, 2022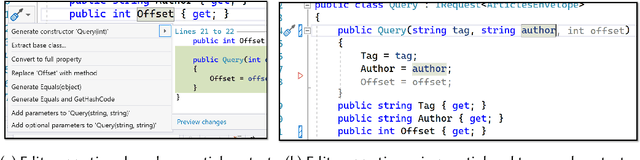


Integrated Development Environments (IDEs) provide tool support to automate many source code editing tasks. Traditionally, IDEs use only the spatial context, i.e., the location where the developer is editing, to generate candidate edit recommendations. However, spatial context alone is often not sufficient to confidently predict the developer's next edit, and thus IDEs generate many suggestions at a location. Therefore, IDEs generally do not actively offer suggestions and instead, the developer is usually required to click on a specific icon or menu and then select from a large list of potential suggestions. As a consequence, developers often miss the opportunity to use the tool support because they are not aware it exists or forget to use it. To better understand common patterns in developer behavior and produce better edit recommendations, we can additionally use the temporal context, i.e., the edits that a developer was recently performing. To enable edit recommendations based on temporal context, we present Overwatch, a novel technique for learning edit sequence patterns from traces of developers' edits performed in an IDE. Our experiments show that Overwatch has 78% precision and that Overwatch not only completed edits when developers missed the opportunity to use the IDE tool support but also predicted new edits that have no tool support in the IDE.
A Probabilistic Framework for Knowledge Graph Data Augmentation
Oct 25, 2021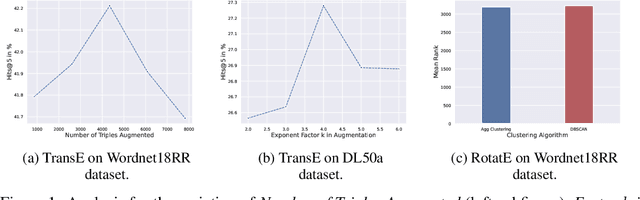



We present NNMFAug, a probabilistic framework to perform data augmentation for the task of knowledge graph completion to counter the problem of data scarcity, which can enhance the learning process of neural link predictors. Our method can generate potentially diverse triples with the advantage of being efficient and scalable as well as agnostic to the choice of the link prediction model and dataset used. Experiments and analysis done on popular models and benchmarks show that NNMFAug can bring notable improvements over the baselines.
Unbiased Loss Functions for Extreme Classification With Missing Labels
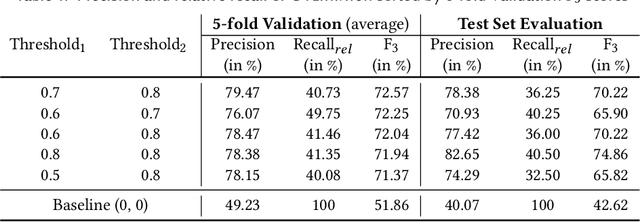
Jul 01, 2020

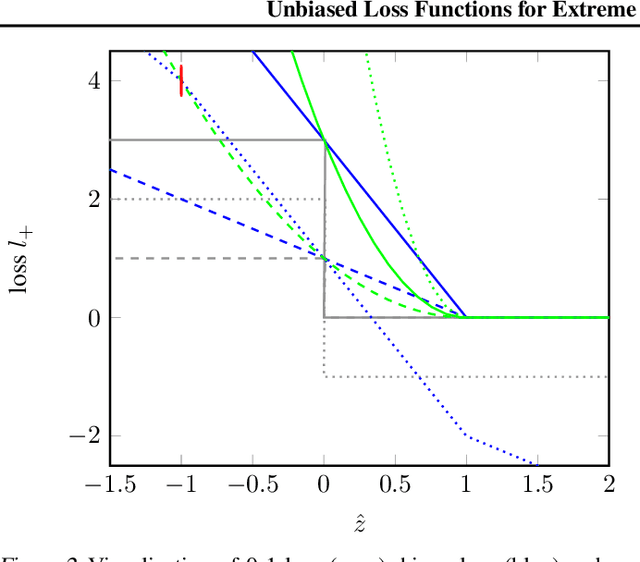
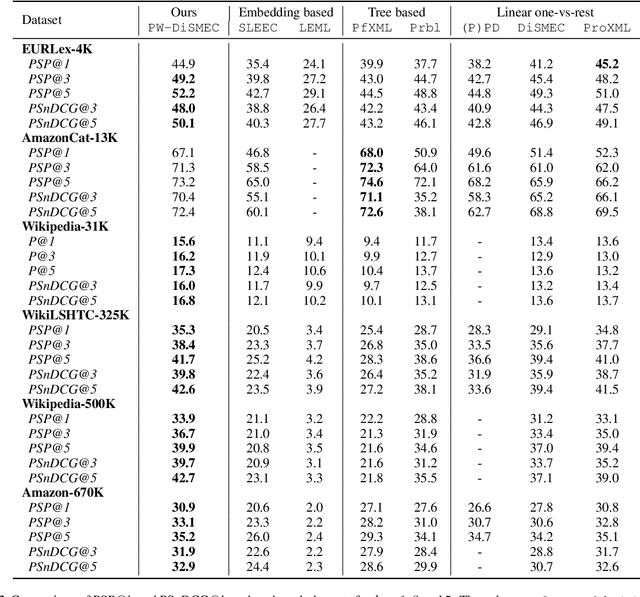
The goal in extreme multi-label classification (XMC) is to tag an instance with a small subset of relevant labels from an extremely large set of possible labels. In addition to the computational burden arising from large number of training instances, features and labels, problems in XMC are faced with two statistical challenges, (i) large number of 'tail-labels' -- those which occur very infrequently, and (ii) missing labels as it is virtually impossible to manually assign every relevant label to an instance. In this work, we derive an unbiased estimator for general formulation of loss functions which decompose over labels, and then infer the forms for commonly used loss functions such as hinge- and squared-hinge-loss and binary cross-entropy loss. We show that the derived unbiased estimators, in the form of appropriate weighting factors, can be easily incorporated in state-of-the-art algorithms for extreme classification, thereby scaling to datasets with hundreds of thousand labels. However, empirically, we find a slightly altered version that gives more relative weight to tail labels to perform even better. We suspect is due to the label imbalance in the dataset, which is not explicitly addressed by our theoretically derived estimator. Minimizing the proposed loss functions leads to significant improvement over existing methods (up to 20% in some cases) on benchmark datasets in XMC.