 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Label Training Preserves Epistemic Uncertainty
Nov 18, 2025Many machine learning tasks involve inherent subjectivity, where annotators naturally provide varied labels. Standard practice collapses these label distributions into single labels, aggregating diverse human judgments into point estimates. We argue that this approach is epistemically misaligned for ambiguous data--the annotation distribution itself should be regarded as the ground truth. Training on collapsed single labels forces models to express false confidence on fundamentally ambiguous cases, creating a misalignment between model certainty and the diversity of human perception. We demonstrate empirically that soft-label training, which treats annotation distributions as ground truth, preserves epistemic uncertainty. Across both vision and NLP tasks, soft-label training achieves 32% lower KL divergence from human annotations and 61% stronger correlation between model and annotation entropy, while matching the accuracy of hard-label training. Our work repositions annotation distributions from noisy signals to be aggregated away, to faithful representations of epistemic uncertainty that models should learn to reproduce.
TensoIS: A Step Towards Feed-Forward Tensorial Inverse Subsurface Scattering for Perlin Distributed Heterogeneous Media
Sep 04, 2025Estimating scattering parameters of heterogeneous media from images is a severely under-constrained and challenging problem. Most of the existing approaches model BSSRDF either through an analysis-by-synthesis approach, approximating complex path integrals, or using differentiable volume rendering techniques to account for heterogeneity. However, only a few studies have applied learning-based methods to estimate subsurface scattering parameters, but they assume homogeneous media. Interestingly, no specific distribution is known to us that can explicitly model the heterogeneous scattering parameters in the real world. Notably, procedural noise models such as Perlin and Fractal Perlin noise have been effective in representing intricate heterogeneities of natural, organic, and inorganic surfaces. Leveraging this, we first create HeteroSynth, a synthetic dataset comprising photorealistic images of heterogeneous media whose scattering parameters are modeled using Fractal Perlin noise. Furthermore, we propose Tensorial Inverse Scattering (TensoIS), a learning-based feed-forward framework to estimate these Perlin-distributed heterogeneous scattering parameters from sparse multi-view image observations. Instead of directly predicting the 3D scattering parameter volume, TensoIS uses learnable low-rank tensor components to represent the scattering volume. We evaluate TensoIS on unseen heterogeneous variations over shapes from the HeteroSynth test set, smoke and cloud geometries obtained from open-source realistic volumetric simulations, and some real-world samples to establish its effectiveness for inverse scattering. Overall, this study is an attempt to explore Perlin noise distribution, given the lack of any such well-defined distribution in literature, to potentially model real-world heterogeneous scattering in a feed-forward manner.
RASP: Revisiting 3D Anamorphic Art for Shadow-Guided Packing of Irregular Objects
Apr 03, 2025Recent advancements in learning-based methods have opened new avenues for exploring and interpreting art forms, such as shadow art, origami, and sketch art, through computational models. One notable visual art form is 3D Anamorphic Art in which an ensemble of arbitrarily shaped 3D objects creates a realistic and meaningful expression when observed from a particular viewpoint and loses its coherence over the other viewpoints. In this work, we build on insights from 3D Anamorphic Art to perform 3D object arrangement. We introduce RASP, a differentiable-rendering-based framework to arrange arbitrarily shaped 3D objects within a bounded volume via shadow (or silhouette)-guided optimization with an aim of minimal inter-object spacing and near-maximal occupancy. Furthermore, we propose a novel SDF-based formulation to handle inter-object intersection and container extrusion. We demonstrate that RASP can be extended to part assembly alongside object packing considering 3D objects to be "parts" of another 3D object. Finally, we present artistic illustrations of multi-view anamorphic art, achieving meaningful expressions from multiple viewpoints within a single ensemble.
$C^{3}$-NeRF: Modeling Multiple Scenes via Conditional-cum-Continual Neural Radiance Fields
Nov 29, 2024Neural radiance fields (NeRF) have exhibited highly photorealistic rendering of novel views through per-scene optimization over a single 3D scene. With the growing popularity of NeRF and its variants, they have become ubiquitous and have been identified as efficient 3D resources. However, they are still far from being scalable since a separate model needs to be stored for each scene, and the training time increases linearly with every newly added scene. Surprisingly, the idea of encoding multiple 3D scenes into a single NeRF model is heavily under-explored. In this work, we propose a novel conditional-cum-continual framework, called $C^{3}$-NeRF, to accommodate multiple scenes into the parameters of a single neural radiance field. Unlike conventional approaches that leverage feature extractors and pre-trained priors for scene conditioning, we use simple pseudo-scene labels to model multiple scenes in NeRF. Interestingly, we observe the framework is also inherently continual (via generative replay) with minimal, if not no, forgetting of the previously learned scenes. Consequently, the proposed framework adapts to multiple new scenes without necessarily accessing the old data. Through extensive qualitative and quantitative evaluation using synthetic and real datasets, we demonstrate the inherent capacity of the NeRF model to accommodate multiple scenes with high-quality novel-view renderings without adding additional parameters. We provide implementation details and dynamic visualizations of our results in the supplementary file.
LIPIDS: Learning-based Illumination Planning In Discretized (Light) Space for Photometric Stereo
Sep 01, 2024

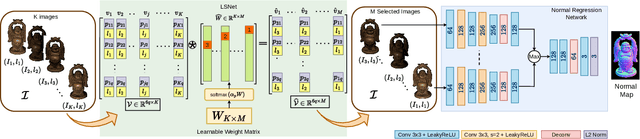

Photometric stereo is a powerful method for obtaining per-pixel surface normals from differently illuminated images of an object. While several methods address photometric stereo with different image (or light) counts ranging from one to two to a hundred, very few focus on learning optimal lighting configuration. Finding an optimal configuration is challenging due to the vast number of possible lighting directions. Moreover, exhaustively sampling all possibilities is impractical due to time and resource constraints. Photometric stereo methods have demonstrated promising performance on existing datasets, which feature limited light directions sparsely sampled from the light space. Therefore, can we optimally utilize these datasets for illumination planning? In this work, we introduce LIPIDS - Learning-based Illumination Planning In Discretized light Space to achieve minimal and optimal lighting configurations for photometric stereo under arbitrary light distribution. We propose a Light Sampling Network (LSNet) that optimizes lighting direction for a fixed number of lights by minimizing the normal loss through a normal regression network. The learned light configurations can directly estimate surface normals during inference, even using an off-the-shelf photometric stereo method. Extensive qualitative and quantitative analyses on synthetic and real-world datasets show that photometric stereo under learned lighting configurations through LIPIDS either surpasses or is nearly comparable to existing illumination planning methods across different photometric stereo backbones.
MERLiN: Single-Shot Material Estimation and Relighting for Photometric Stereo
Sep 01, 2024



Photometric stereo typically demands intricate data acquisition setups involving multiple light sources to recover surface normals accurately. In this paper, we propose MERLiN, an attention-based hourglass network that integrates single image-based inverse rendering and relighting within a single unified framework. We evaluate the performance of photometric stereo methods using these relit images and demonstrate how they can circumvent the underlying challenge of complex data acquisition. Our physically-based model is trained on a large synthetic dataset containing complex shapes with spatially varying BRDF and is designed to handle indirect illumination effects to improve material reconstruction and relighting. Through extensive qualitative and quantitative evaluation, we demonstrate that the proposed framework generalizes well to real-world images, achieving high-quality shape, material estimation, and relighting. We assess these synthetically relit images over photometric stereo benchmark methods for their physical correctness and resulting normal estimation accuracy, paving the way towards single-shot photometric stereo through physically-based relighting. This work allows us to address the single image-based inverse rendering problem holistically, applying well to both synthetic and real data and taking a step towards mitigating the challenge of data acquisition in photometric stereo.
SS-SfP:Neural Inverse Rendering for Self Supervised Shape from (Mixed) Polarization
Jul 12, 2024We present a novel inverse rendering-based framework to estimate the 3D shape (per-pixel surface normals and depth) of objects and scenes from single-view polarization images, the problem popularly known as Shape from Polarization (SfP). The existing physics-based and learning-based methods for SfP perform under certain restrictions, i.e., (a) purely diffuse or purely specular reflections, which are seldom in the real surfaces, (b) availability of the ground truth surface normals for direct supervision that are hard to acquire and are limited by the scanner's resolution, and (c) known refractive index. To overcome these restrictions, we start by learning to separate the partially-polarized diffuse and specular reflection components, which we call reflectance cues, based on a modified polarization reflection model and then estimate shape under mixed polarization through an inverse-rendering based self-supervised deep learning framework called SS-SfP, guided by the polarization data and estimated reflectance cues. Furthermore, we also obtain the refractive index as a non-linear least squares solution. Through extensive quantitative and qualitative evaluation, we establish the efficacy of the proposed framework over simple single-object scenes from DeepSfP dataset and complex in-the-wild scenes from SPW dataset in an entirely self-supervised setting. To the best of our knowledge, this is the first learning-based approach to address SfP under mixed polarization in a completely self-supervised framework.
Augmented Embeddings for Custom Retrievals
Oct 09, 2023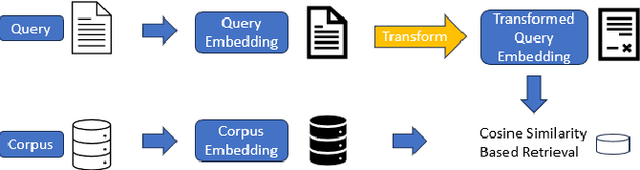



Information retrieval involves selecting artifacts from a corpus that are most relevant to a given search query. The flavor of retrieval typically used in classical applications can be termed as homogeneous and relaxed, where queries and corpus elements are both natural language (NL) utterances (homogeneous) and the goal is to pick most relevant elements from the corpus in the Top-K, where K is large, such as 10, 25, 50 or even 100 (relaxed). Recently, retrieval is being used extensively in preparing prompts for large language models (LLMs) to enable LLMs to perform targeted tasks. These new applications of retrieval are often heterogeneous and strict -- the queries and the corpus contain different kinds of entities, such as NL and code, and there is a need for improving retrieval at Top-K for small values of K, such as K=1 or 3 or 5. Current dense retrieval techniques based on pretrained embeddings provide a general-purpose and powerful approach for retrieval, but they are oblivious to task-specific notions of similarity of heterogeneous artifacts. We introduce Adapted Dense Retrieval, a mechanism to transform embeddings to enable improved task-specific, heterogeneous and strict retrieval. Adapted Dense Retrieval works by learning a low-rank residual adaptation of the pretrained black-box embedding. We empirically validate our approach by showing improvements over the state-of-the-art general-purpose embeddings-based baseline.
GrACE: Generation using Associated Code Edits
May 24, 2023



Developers expend a significant amount of time in editing code for a variety of reasons such as bug fixing or adding new features. Designing effective methods to predict code edits has been an active yet challenging area of research due to the diversity of code edits and the difficulty of capturing the developer intent. In this work, we address these challenges by endowing pre-trained large language models (LLMs) of code with the knowledge of prior, relevant edits. The generative capability of the LLMs helps address the diversity in code changes and conditioning code generation on prior edits helps capture the latent developer intent. We evaluate two well-known LLMs, Codex and CodeT5, in zero-shot and fine-tuning settings respectively. In our experiments with two datasets, the knowledge of prior edits boosts the performance of the LLMs significantly and enables them to generate 29% and 54% more correctly edited code in top-1 suggestions relative to the current state-of-the-art symbolic and neural approaches, respectively.
From Words to Code: Harnessing Data for Program Synthesis from Natural Language
May 03, 2023



Creating programs to correctly manipulate data is a difficult task, as the underlying programming languages and APIs can be challenging to learn for many users who are not skilled programmers. Large language models (LLMs) demonstrate remarkable potential for generating code from natural language, but in the data manipulation domain, apart from the natural language (NL) description of the intended task, we also have the dataset on which the task is to be performed, or the "data context". Existing approaches have utilized data context in a limited way by simply adding relevant information from the input data into the prompts sent to the LLM. In this work, we utilize the available input data to execute the candidate programs generated by the LLMs and gather their outputs. We introduce semantic reranking, a technique to rerank the programs generated by LLMs based on three signals coming the program outputs: (a) semantic filtering and well-formedness based score tuning: do programs even generate well-formed outputs, (b) semantic interleaving: how do the outputs from different candidates compare to each other, and (c) output-based score tuning: how do the outputs compare to outputs predicted for the same task. We provide theoretical justification for semantic interleaving. We also introduce temperature mixing, where we combine samples generated by LLMs using both high and low temperatures. We extensively evaluate our approach in three domains, namely databases (SQL), data science (Pandas) and business intelligence (Excel's Power Query M) on a variety of new and existing benchmarks. We observe substantial gains across domains, with improvements of up to 45% in top-1 accuracy and 34% in top-3 accuracy.