 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Code: Harnessing Data for Program Synthesis from Natural Language
May 03, 2023



Creating programs to correctly manipulate data is a difficult task, as the underlying programming languages and APIs can be challenging to learn for many users who are not skilled programmers. Large language models (LLMs) demonstrate remarkable potential for generating code from natural language, but in the data manipulation domain, apart from the natural language (NL) description of the intended task, we also have the dataset on which the task is to be performed, or the "data context". Existing approaches have utilized data context in a limited way by simply adding relevant information from the input data into the prompts sent to the LLM. In this work, we utilize the available input data to execute the candidate programs generated by the LLMs and gather their outputs. We introduce semantic reranking, a technique to rerank the programs generated by LLMs based on three signals coming the program outputs: (a) semantic filtering and well-formedness based score tuning: do programs even generate well-formed outputs, (b) semantic interleaving: how do the outputs from different candidates compare to each other, and (c) output-based score tuning: how do the outputs compare to outputs predicted for the same task. We provide theoretical justification for semantic interleaving. We also introduce temperature mixing, where we combine samples generated by LLMs using both high and low temperatures. We extensively evaluate our approach in three domains, namely databases (SQL), data science (Pandas) and business intelligence (Excel's Power Query M) on a variety of new and existing benchmarks. We observe substantial gains across domains, with improvements of up to 45% in top-1 accuracy and 34% in top-3 accuracy.
Semantic Robustness of Models of Source Code
Feb 07, 2020
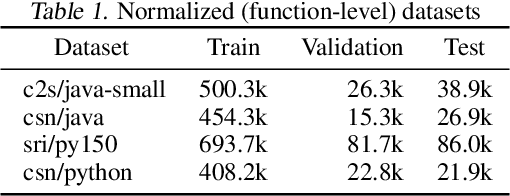


Deep neural networks are vulnerable to adversarial examples - small input perturbations that result in incorrect predictions. We study this problem in the context of models of source code, where we want the network to be robust to source-code modifications that preserve code functionality. We define a natural notion of robustness, $k$-transformation robustness, in which an adversary performs up to $k$ semantics-preserving transformations to an input program. We show how to train robust models using an adversarial training objective inspired by that of Madry et al. (2018) for continuous domains. We implement an extensible framework for adversarial training over source code, and conduct a thorough evaluation on a number of datasets and two different architectures. Our results show (1) the increase in robustness following adversarial training, (2) the ability of training on weak adversaries to provide robustness to attacks by stronger adversaries, and (3) the shift in attribution focus of adversarially trained models towards semantic vs. syntactic features.
Enabling Open-World Specification Mining via Unsupervised Learning
Apr 27, 2019


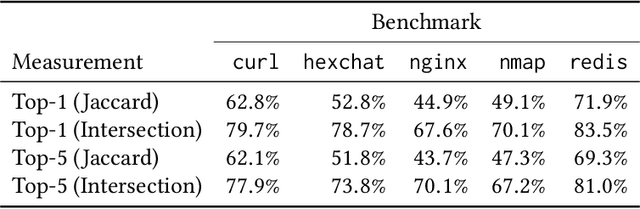
Many programming tasks require using both domain-specific code and well-established patterns (such as routines concerned with file IO). Together, several small patterns combine to create complex interactions. This compounding effect, mixed with domain-specific idiosyncrasies, creates a challenging environment for fully automatic specification inference. Mining specifications in this environment, without the aid of rule templates, user-directed feedback, or predefined API surfaces, is a major challenge. We call this challenge Open-World Specification Mining. In this paper, we present a framework for mining specifications and usage patterns in an Open-World setting. We design this framework to be miner-agnostic and instead focus on disentangling complex and noisy API interactions. To evaluate our framework, we introduce a benchmark of 71 clusters extracted from five open-source projects. Using this dataset, we show that interesting clusters can be recovered, in a fully automatic way, by leveraging unsupervised learning in the form of word embeddings. Once clusters have been recovered, the challenge of Open-World Specification Mining is simplified and any trace-based mining technique can be applied. In addition, we provide a comprehensive evaluation of three word-vector learners to showcase the value of sub-word information for embeddings learned in the software-engineering domain.