 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Compiler for Secure Agentic Systems
Feb 19, 2026LLM-based agents are increasingly being deployed in contexts requiring complex authorization policies: customer service protocols, approval workflows, data access restrictions, and regulatory compliance. Embedding these policies in prompts provides no enforcement guarantees. We present PCAS, a Policy Compiler for Agentic Systems that provides deterministic policy enforcement. Enforcing such policies requires tracking information flow across agents, which linear message histories cannot capture. Instead, PCAS models the agentic system state as a dependency graph capturing causal relationships among events such as tool calls, tool results, and messages. Policies are expressed in a Datalog-derived language, as declarative rules that account for transitive information flow and cross-agent provenance. A reference monitor intercepts all actions and blocks violations before execution, providing deterministic enforcement independent of model reasoning. PCAS takes an existing agent implementation and a policy specification, and compiles them into an instrumented system that is policy-compliant by construction, with no security-specific restructuring required. We evaluate PCAS on three case studies: information flow policies for prompt injection defense, approval workflows in a multi-agent pharmacovigilance system, and organizational policies for customer service. On customer service tasks, PCAS improves policy compliance from 48% to 93% across frontier models, with zero policy violations in instrumented runs.
What Really is a Member? Discrediting Membership Inference via Poisoning
Jun 06, 2025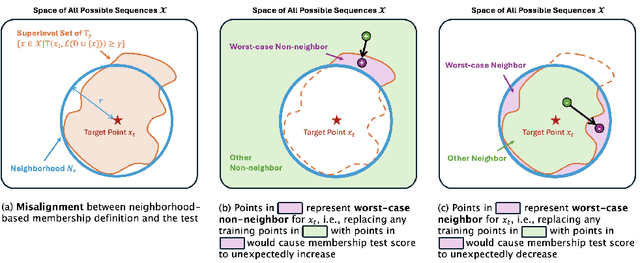

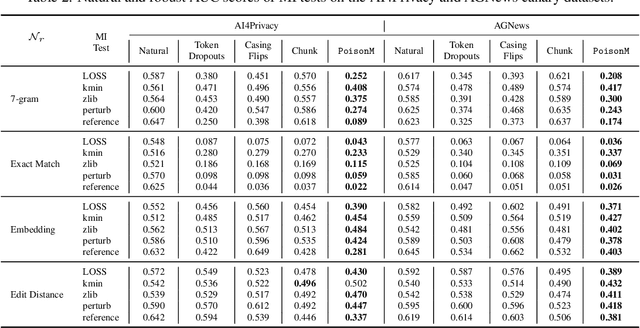
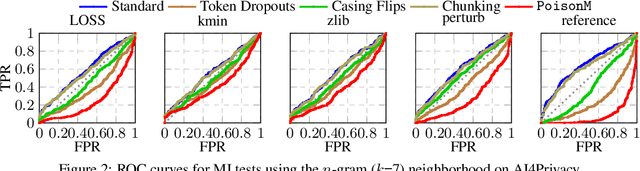
Membership inference tests aim to determine whether a particular data point was included in a language model's training set. However, recent works have shown that such tests often fail under the strict definition of membership based on exact matching, and have suggested relaxing this definition to include semantic neighbors as members as well. In this work, we show that membership inference tests are still unreliable under this relaxation - it is possible to poison the training dataset in a way that causes the test to produce incorrect predictions for a target point. We theoretically reveal a trade-off between a test's accuracy and its robustness to poisoning. We also present a concrete instantiation of this poisoning attack and empirically validate its effectiveness. Our results show that it can degrade the performance of existing tests to well below random.
Through the Stealth Lens: Rethinking Attacks and Defenses in RAG
Jun 04, 2025Retrieval-augmented generation (RAG) systems are vulnerable to attacks that inject poisoned passages into the retrieved set, even at low corruption rates. We show that existing attacks are not designed to be stealthy, allowing reliable detection and mitigation. We formalize stealth using a distinguishability-based security game. If a few poisoned passages are designed to control the response, they must differentiate themselves from benign ones, inherently compromising stealth. This motivates the need for attackers to rigorously analyze intermediate signals involved in generation$\unicode{x2014}$such as attention patterns or next-token probability distributions$\unicode{x2014}$to avoid easily detectable traces of manipulation. Leveraging attention patterns, we propose a passage-level score$\unicode{x2014}$the Normalized Passage Attention Score$\unicode{x2014}$used by our Attention-Variance Filter algorithm to identify and filter potentially poisoned passages. This method mitigates existing attacks, improving accuracy by up to $\sim 20 \%$ over baseline defenses. To probe the limits of attention-based defenses, we craft stealthier adaptive attacks that obscure such traces, achieving up to $35 \%$ attack success rate, and highlight the challenges in improving stealth.
Pr$εε$mpt: Sanitizing Sensitive Prompts for LLMs
Apr 07, 2025The rise of large language models (LLMs) has introduced new privacy challenges, particularly during inference where sensitive information in prompts may be exposed to proprietary LLM APIs. In this paper, we address the problem of formally protecting the sensitive information contained in a prompt while maintaining response quality. To this end, first, we introduce a cryptographically inspired notion of a prompt sanitizer which transforms an input prompt to protect its sensitive tokens. Second, we propose Pr$\epsilon\epsilon$mpt, a novel system that implements a prompt sanitizer. Pr$\epsilon\epsilon$mpt categorizes sensitive tokens into two types: (1) those where the LLM's response depends solely on the format (such as SSNs, credit card numbers), for which we use format-preserving encryption (FPE); and (2) those where the response depends on specific values, (such as age, salary) for which we apply metric differential privacy (mDP). Our evaluation demonstrates that Pr$\epsilon\epsilon$mpt is a practical method to achieve meaningful privacy guarantees, while maintaining high utility compared to unsanitized prompts, and outperforming prior methods
LLM-Driven Multi-step Translation from C to Rust using Static Analysis
Mar 16, 2025

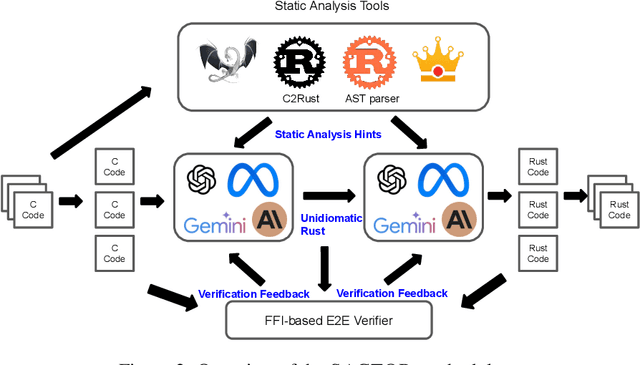

Translating software written in legacy languages to modern languages, such as C to Rust, has significant benefits in improving memory safety while maintaining high performance. However, manual translation is cumbersome, error-prone, and produces unidiomatic code. Large language models (LLMs) have demonstrated promise in producing idiomatic translations, but offer no correctness guarantees as they lack the ability to capture all the semantics differences between the source and target languages. To resolve this issue, we propose SACTOR, an LLM-driven C-to-Rust zero-shot translation tool using a two-step translation methodology: an "unidiomatic" step to translate C into Rust while preserving semantics, and an "idiomatic" step to refine the code to follow Rust's semantic standards. SACTOR utilizes information provided by static analysis of the source C program to address challenges such as pointer semantics and dependency resolution. To validate the correctness of the translated result from each step, we use end-to-end testing via the foreign function interface to embed our translated code segment into the original code. We evaluate the translation of 200 programs from two datasets and two case studies, comparing the performance of GPT-4o, Claude 3.5 Sonnet, Gemini 2.0 Flash, Llama 3.3 70B and DeepSeek-R1 in SACTOR. Our results demonstrate that SACTOR achieves high correctness and improved idiomaticity, with the best-performing model (DeepSeek-R1) reaching 93% and (GPT-4o, Claude 3.5, DeepSeek-R1) reaching 84% correctness (on each dataset, respectively), while producing more natural and Rust-compliant translations compared to existing methods.
SLVR: Securely Leveraging Client Validation for Robust Federated Learning
Feb 12, 2025Federated Learning (FL) enables collaborative model training while keeping client data private. However, exposing individual client updates makes FL vulnerable to reconstruction attacks. Secure aggregation mitigates such privacy risks but prevents the server from verifying the validity of each client update, creating a privacy-robustness tradeoff. Recent efforts attempt to address this tradeoff by enforcing checks on client updates using zero-knowledge proofs, but they support limited predicates and often depend on public validation data. We propose SLVR, a general framework that securely leverages clients' private data through secure multi-party computation. By utilizing clients' data, SLVR not only eliminates the need for public validation data, but also enables a wider range of checks for robustness, including cross-client accuracy validation. It also adapts naturally to distribution shifts in client data as it can securely refresh its validation data up-to-date. Our empirical evaluations show that SLVR improves robustness against model poisoning attacks, particularly outperforming existing methods by up to 50% under adaptive attacks. Additionally, SLVR demonstrates effective adaptability and stable convergence under various distribution shift scenarios.
On the Difficulty of Constructing a Robust and Publicly-Detectable Watermark
Feb 07, 2025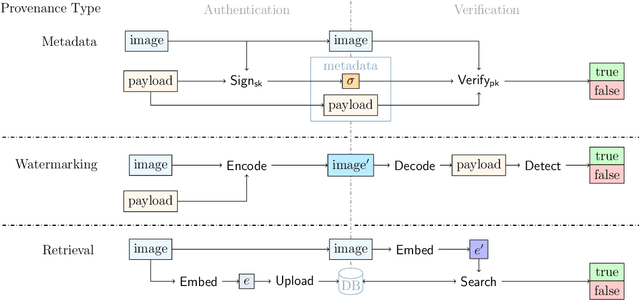
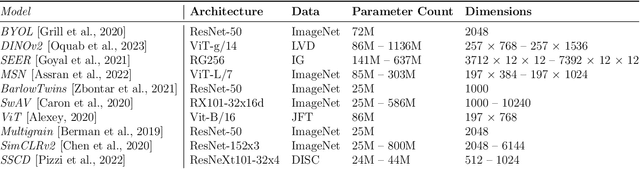
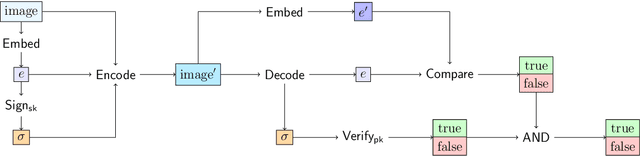
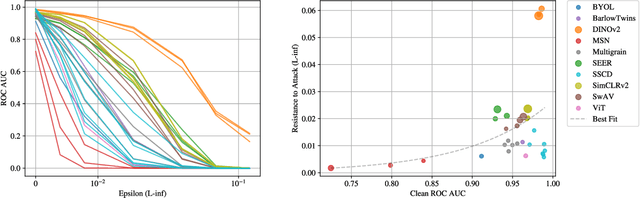
This work investigates the theoretical boundaries of creating publicly-detectable schemes to enable the provenance of watermarked imagery. Metadata-based approaches like C2PA provide unforgeability and public-detectability. ML techniques offer robust retrieval and watermarking. However, no existing scheme combines robustness, unforgeability, and public-detectability. In this work, we formally define such a scheme and establish its existence. Although theoretically possible, we find that at present, it is intractable to build certain components of our scheme without a leap in deep learning capabilities. We analyze these limitations and propose research directions that need to be addressed before we can practically realize robust and publicly-verifiable provenance.
Adaptive Concept Bottleneck for Foundation Models Under Distribution Shifts
Dec 18, 2024

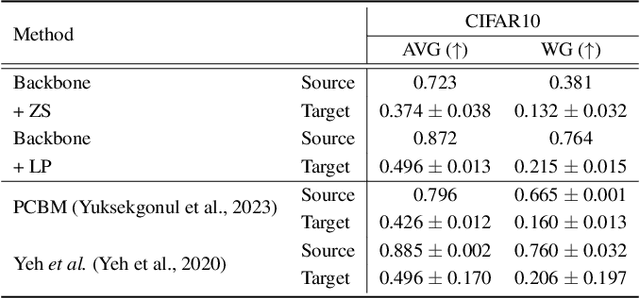

Advancements in foundation models (FMs) have led to a paradigm shift in machine learning. The rich, expressive feature representations from these pre-trained, large-scale FMs are leveraged for multiple downstream tasks, usually via lightweight fine-tuning of a shallow fully-connected network following the representation. However, the non-interpretable, black-box nature of this prediction pipeline can be a challenge, especially in critical domains such as healthcare, finance, and security. In this paper, we explore the potential of Concept Bottleneck Models (CBMs) for transforming complex, non-interpretable foundation models into interpretable decision-making pipelines using high-level concept vectors. Specifically, we focus on the test-time deployment of such an interpretable CBM pipeline "in the wild", where the input distribution often shifts from the original training distribution. We first identify the potential failure modes of such a pipeline under different types of distribution shifts. Then we propose an adaptive concept bottleneck framework to address these failure modes, that dynamically adapts the concept-vector bank and the prediction layer based solely on unlabeled data from the target domain, without access to the source (training) dataset. Empirical evaluations with various real-world distribution shifts show that our adaptation method produces concept-based interpretations better aligned with the test data and boosts post-deployment accuracy by up to 28%, aligning the CBM performance with that of non-interpretable classification.
SoK: Watermarking for AI-Generated Content
Nov 27, 2024

As the outputs of generative AI (GenAI) techniques improve in quality, it becomes increasingly challenging to distinguish them from human-created content. Watermarking schemes are a promising approach to address the problem of distinguishing between AI and human-generated content. These schemes embed hidden signals within AI-generated content to enable reliable detection. While watermarking is not a silver bullet for addressing all risks associated with GenAI, it can play a crucial role in enhancing AI safety and trustworthiness by combating misinformation and deception. This paper presents a comprehensive overview of watermarking techniques for GenAI, beginning with the need for watermarking from historical and regulatory perspectives. We formalize the definitions and desired properties of watermarking schemes and examine the key objectives and threat models for existing approaches. Practical evaluation strategies are also explored, providing insights into the development of robust watermarking techniques capable of resisting various attacks. Additionally, we review recent representative works, highlight open challenges, and discuss potential directions for this emerging field. By offering a thorough understanding of watermarking in GenAI, this work aims to guide researchers in advancing watermarking methods and applications, and support policymakers in addressing the broader implications of GenAI.
AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs
Oct 14, 2024



In this paper, we propose AutoDAN-Turbo, a black-box jailbreak method that can automatically discover as many jailbreak strategies as possible from scratch, without any human intervention or predefined scopes (e.g., specified candidate strategies), and use them for red-teaming. As a result, AutoDAN-Turbo can significantly outperform baseline methods, achieving a 74.3% higher average attack success rate on public benchmarks. Notably, AutoDAN-Turbo achieves an 88.5 attack success rate on GPT-4-1106-turbo. In addition, AutoDAN-Turbo is a unified framework that can incorporate existing human-designed jailbreak strategies in a plug-and-play manner. By integrating human-designed strategies, AutoDAN-Turbo can even achieve a higher attack success rate of 93.4 on GPT-4-1106-turbo.