 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Rates for Differentially Private Hypothesis Testing with E-values
May 27, 2026E-values have attracted considerable interest in recent years as flexible tools for enabling anytime-valid and adaptive data analysis. Hypothesis testing is at the core of many of these applications, which can often involve private or sensitive data. In this work, we answer a simple but important question: given two distributions $\mathbb{P}$ and $\mathbb{Q}$, what is the maximum achievable e-power when testing $X\sim \mathbb{P}^n$ against $X\sim\mathbb{Q}^n$ with e-values that satisfy $\varepsilon$-differential privacy? We characterize the optimal rate for this problem and provide an algorithm which matches it exactly. In the sequential setting, when observations arrive one-by-one and the analyst chooses when to halt, we give matching upper and lower bounds on the stopping times of any private e-process. Numerical experiments confirm the practicality of our algorithms, which require less data than the recently proposed DP-SPRT across a range of sequential testing problems and privacy levels.
Undetectable Backdoors in Model Parameters: Hiding Sparse Secrets in High Dimensions
May 05, 2026We present Sparse Backdoor, a supply-chain attack that plants a \emph{provably undetectable} backdoor in pre-trained image classifiers, including convolutional networks and Vision Transformers. The attack injects a structured sparse perturbation along a randomly chosen direction into a small subset of columns at each fully connected layer, propagating a trigger signal to an adversary-chosen target class, and masks the perturbation with an independent isotropic Gaussian dither. The dither serves a single technical purpose: it induces a clean reference distribution anchored at the pre-trained weights, against which undetectability can be formalized. Under a mild margin condition on the pre-trained classifier, we show that the dithered reference is functionally equivalent to the original classifier. We prove that distinguishing the backdoor-injected model from this reference is at least as hard as Sparse PCA detection, which is computationally infeasible under standard hardness assumptions. The guarantee holds against any probabilistic polynomial-time distinguisher with white-box access to the parameters.
Challenges and Future Directions in Agentic Reverse Engineering Systems
Apr 15, 2026Agentic systems built on large language models (LLMs) are increasingly being used for complex security tasks, including binary reverse engineering (RE). Despite recent growth in popularity and capability, these systems continue to face limitations in realistic settings. Cutting-edge systems still fail in complex RE scenarios that involve obfuscation, timing, and unique architecture. In this work, we examine how agentic systems perform reverse engineering tasks with static, dynamic, and hybrid agents. Through an analysis of existing agentic tool usage, we identify several limitations, including token constraints, struggles with obfuscation, and a lack of program guardrails. From these findings, we outline current challenges and position future directions for system designers to overcome from a security perspective.
WebSP-Eval: Evaluating Web Agents on Website Security and Privacy Tasks
Apr 07, 2026Web agents automate browser tasks, ranging from simple form completion to complex workflows like ordering groceries. While current benchmarks evaluate general-purpose performance~(e.g., WebArena) or safety against malicious actions~(e.g., SafeArena), no existing framework assesses an agent's ability to successfully execute user-facing website security and privacy tasks, such as managing cookie preferences, configuring privacy-sensitive account settings, or revoking inactive sessions. To address this gap, we introduce WebSP-Eval, an evaluation framework for measuring web agent performance on website security and privacy tasks. WebSP-Eval comprises 1) a manually crafted task dataset of 200 task instances across 28 websites; 2) a robust agentic system supporting account and initial state management across runs using a custom Google Chrome extension; and 3) an automated evaluator. We evaluate a total of 8 web agent instantiations using state-of-the-art multimodal large language models, conducting a fine-grained analysis across websites, task categories, and UI elements. Our evaluation reveals that current models suffer from limited autonomous exploration capabilities to reliably solve website security and privacy tasks, and struggle with specific task categories and websites. Crucially, we identify stateful UI elements such as toggles and checkboxes are a primary reason for agent failure, failing at a rate of more than 45\% in tasks containing these elements across many models.
"It's like a pet...but my pet doesn't collect data about me": Multi-person Households' Privacy Design Preferences for Household Robots
Feb 19, 2026Household robots boasting mobility, more sophisticated sensors, and powerful processing models have become increasingly prevalent in the commercial market. However, these features may expose users to unwanted privacy risks, including unsolicited data collection and unauthorized data sharing. While security and privacy researchers thus far have explored people's privacy concerns around household robots, literature investigating people's preferred privacy designs and mitigation strategies is still limited. Additionally, the existing literature has not yet accounted for multi-user perspectives on privacy design and household robots. We aimed to fill this gap by conducting in-person participatory design sessions with 15 households to explore how they would design a privacy-aware household robot based on their concerns and expectations. We found that participants did not trust that robots, or their respective manufacturers, would respect the data privacy of household members or operate in a multi-user ecosystem without jeopardizing users' personal data. Based on these concerns, they generated designs that gave them authority over their data, contained accessible controls and notification systems, and could be customized and tailored to suit the needs and preferences of each user over time. We synthesize our findings into actionable design recommendations for robot manufacturers and developers.
Private Continual Counting of Unbounded Streams
Jun 17, 2025We study the problem of differentially private continual counting in the unbounded setting where the input size $n$ is not known in advance. Current state-of-the-art algorithms based on optimal instantiations of the matrix mechanism cannot be directly applied here because their privacy guarantees only hold when key parameters are tuned to $n$. Using the common `doubling trick' avoids knowledge of $n$ but leads to suboptimal and non-smooth error. We solve this problem by introducing novel matrix factorizations based on logarithmic perturbations of the function $\frac{1}{\sqrt{1-z}}$ studied in prior works, which may be of independent interest. The resulting algorithm has smooth error, and for any $\alpha > 0$ and $t\leq n$ it is able to privately estimate the sum of the first $t$ data points with $O(\log^{2+2\alpha}(t))$ variance. It requires $O(t)$ space and amortized $O(\log t)$ time per round, compared to $O(\log(n)\log(t))$ variance, $O(n)$ space and $O(n \log n)$ pre-processing time for the nearly-optimal bounded-input algorithm of Henzinger et al. (SODA 2023). Empirically, we find that our algorithm's performance is also comparable to theirs in absolute terms: our variance is less than $1.5\times$ theirs for $t$ as large as $2^{24}$.
What Really is a Member? Discrediting Membership Inference via Poisoning
Jun 06, 2025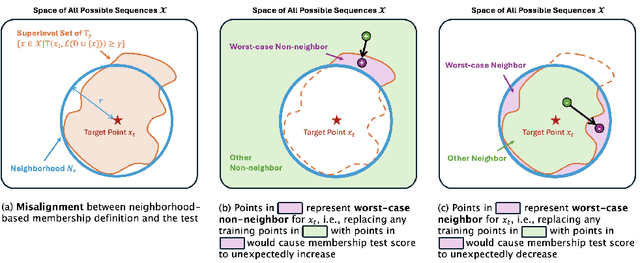

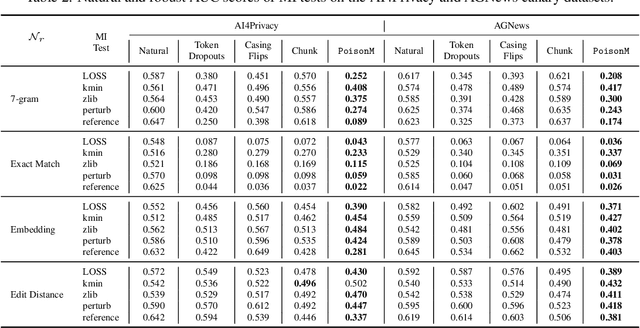
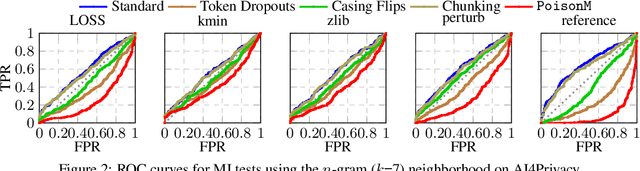
Membership inference tests aim to determine whether a particular data point was included in a language model's training set. However, recent works have shown that such tests often fail under the strict definition of membership based on exact matching, and have suggested relaxing this definition to include semantic neighbors as members as well. In this work, we show that membership inference tests are still unreliable under this relaxation - it is possible to poison the training dataset in a way that causes the test to produce incorrect predictions for a target point. We theoretically reveal a trade-off between a test's accuracy and its robustness to poisoning. We also present a concrete instantiation of this poisoning attack and empirically validate its effectiveness. Our results show that it can degrade the performance of existing tests to well below random.
"Impressively Scary:" Exploring User Perceptions and Reactions to Unraveling Machine Learning Models in Social Media Applications
Mar 05, 2025Machine learning models deployed locally on social media applications are used for features, such as face filters which read faces in-real time, and they expose sensitive attributes to the apps. However, the deployment of machine learning models, e.g., when, where, and how they are used, in social media applications is opaque to users. We aim to address this inconsistency and investigate how social media user perceptions and behaviors change once exposed to these models. We conducted user studies (N=21) and found that participants were unaware to both what the models output and when the models were used in Instagram and TikTok, two major social media platforms. In response to being exposed to the models' functionality, we observed long term behavior changes in 8 participants. Our analysis uncovers the challenges and opportunities in providing transparency for machine learning models that interact with local user data.
Automatically Detecting Online Deceptive Patterns in Real-time
Nov 11, 2024Deceptive patterns (DPs) in digital interfaces manipulate users into making unintended decisions, exploiting cognitive biases and psychological vulnerabilities. These patterns have become ubiquitous across various digital platforms. While efforts to mitigate DPs have emerged from legal and technical perspectives, a significant gap in usable solutions that empower users to identify and make informed decisions about DPs in real-time remains. In this work, we introduce AutoBot, an automated, deceptive pattern detector that analyzes websites' visual appearances using machine learning techniques to identify and notify users of DPs in real-time. AutoBot employs a two-staged pipeline that processes website screenshots, identifying interactable elements and extracting textual features without relying on HTML structure. By leveraging a custom language model, AutoBot understands the context surrounding these elements to determine the presence of deceptive patterns. We implement AutoBot as a lightweight Chrome browser extension that performs all analyses locally, minimizing latency and preserving user privacy. Through extensive evaluation, we demonstrate AutoBot's effectiveness in enhancing users' ability to navigate digital environments safely while providing a valuable tool for regulators to assess and enforce compliance with DP regulations.
Reliable Heading Tracking for Pedestrian Road Crossing Prediction Using Commodity Devices
Oct 08, 2024



Pedestrian heading tracking enables applications in pedestrian navigation, traffic safety, and accessibility. Previous works, using inertial sensor fusion or machine learning, are limited in that they assume the phone is fixed in specific orientations, hindering their generalizability. We propose a new heading tracking algorithm, the Orientation-Heading Alignment (OHA), which leverages a key insight: people tend to carry smartphones in certain ways due to habits, such as swinging them while walking. For each smartphone attitude during this motion, OHA maps the smartphone orientation to the pedestrian heading and learns such mappings efficiently from coarse headings and smartphone orientations. To anchor our algorithm in a practical scenario, we apply OHA to a challenging task: predicting when pedestrians are about to cross the road to improve road user safety. In particular, using 755 hours of walking data collected since 2020 from 60 individuals, we develop a lightweight model that operates in real-time on commodity devices to predict road crossings. Our evaluation shows that OHA achieves 3.4 times smaller heading errors across nine scenarios than existing methods. Furthermore, OHA enables the early and accurate detection of pedestrian crossing behavior, issuing crossing alerts 0.35 seconds, on average, before pedestrians enter the road range.