 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Multi-step Translation from C to Rust using Static Analysis
Mar 16, 2025

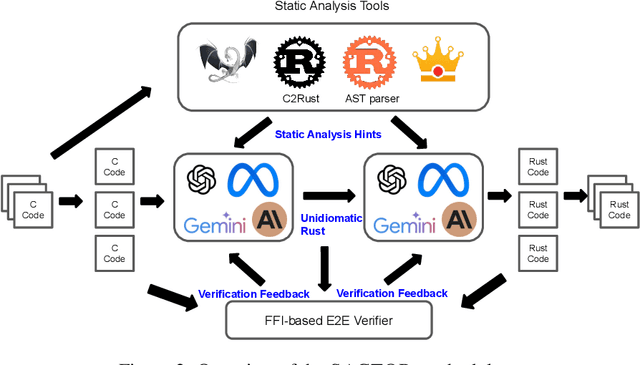

Translating software written in legacy languages to modern languages, such as C to Rust, has significant benefits in improving memory safety while maintaining high performance. However, manual translation is cumbersome, error-prone, and produces unidiomatic code. Large language models (LLMs) have demonstrated promise in producing idiomatic translations, but offer no correctness guarantees as they lack the ability to capture all the semantics differences between the source and target languages. To resolve this issue, we propose SACTOR, an LLM-driven C-to-Rust zero-shot translation tool using a two-step translation methodology: an "unidiomatic" step to translate C into Rust while preserving semantics, and an "idiomatic" step to refine the code to follow Rust's semantic standards. SACTOR utilizes information provided by static analysis of the source C program to address challenges such as pointer semantics and dependency resolution. To validate the correctness of the translated result from each step, we use end-to-end testing via the foreign function interface to embed our translated code segment into the original code. We evaluate the translation of 200 programs from two datasets and two case studies, comparing the performance of GPT-4o, Claude 3.5 Sonnet, Gemini 2.0 Flash, Llama 3.3 70B and DeepSeek-R1 in SACTOR. Our results demonstrate that SACTOR achieves high correctness and improved idiomaticity, with the best-performing model (DeepSeek-R1) reaching 93% and (GPT-4o, Claude 3.5, DeepSeek-R1) reaching 84% correctness (on each dataset, respectively), while producing more natural and Rust-compliant translations compared to existing methods.
Natural Language Outlines for Code: Literate Programming in the LLM Era
Aug 09, 2024



We propose using natural language outlines as a novel modality and interaction surface for providing AI assistance to developers throughout the software development process. An NL outline for a code function comprises multiple statements written in concise prose, which partition the code and summarize its main ideas in the style of literate programming. Crucially, we find that modern LLMs can generate accurate and high-quality NL outlines in practice. Moreover, NL outlines enable a bidirectional sync between code and NL, allowing changes in one to be automatically reflected in the other. We discuss many use cases for NL outlines: they can accelerate understanding and navigation of code and diffs, simplify code maintenance, augment code search, steer code generation, and more. We then propose and compare multiple LLM prompting techniques for generating outlines and ask professional developers to judge outline quality. Finally, we present two case studies applying NL outlines toward code review and the difficult task of malware detection.
Do Large Code Models Understand Programming Concepts? A Black-box Approach
Feb 23, 2024



Large Language Models' success on text generation has also made them better at code generation and coding tasks. While a lot of work has demonstrated their remarkable performance on tasks such as code completion and editing, it is still unclear as to why. We help bridge this gap by exploring to what degree auto-regressive models understand the logical constructs of the underlying programs. We propose Counterfactual Analysis for Programming Concept Predicates (CACP) as a counterfactual testing framework to evaluate whether Large Code Models understand programming concepts. With only black-box access to the model, we use CACP to evaluate ten popular Large Code Models for four different programming concepts. Our findings suggest that current models lack understanding of concepts such as data flow and control flow.
Burning the Adversarial Bridges: Robust Windows Malware Detection Against Binary-level Mutations
Oct 05, 2023



Toward robust malware detection, we explore the attack surface of existing malware detection systems. We conduct root-cause analyses of the practical binary-level black-box adversarial malware examples. Additionally, we uncover the sensitivity of volatile features within the detection engines and exhibit their exploitability. Highlighting volatile information channels within the software, we introduce three software pre-processing steps to eliminate the attack surface, namely, padding removal, software stripping, and inter-section information resetting. Further, to counter the emerging section injection attacks, we propose a graph-based section-dependent information extraction scheme for software representation. The proposed scheme leverages aggregated information within various sections in the software to enable robust malware detection and mitigate adversarial settings. Our experimental results show that traditional malware detection models are ineffective against adversarial threats. However, the attack surface can be largely reduced by eliminating the volatile information. Therefore, we propose simple-yet-effective methods to mitigate the impacts of binary manipulation attacks. Overall, our graph-based malware detection scheme can accurately detect malware with an area under the curve score of 88.32\% and a score of 88.19% under a combination of binary manipulation attacks, exhibiting the efficiency of our proposed scheme.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023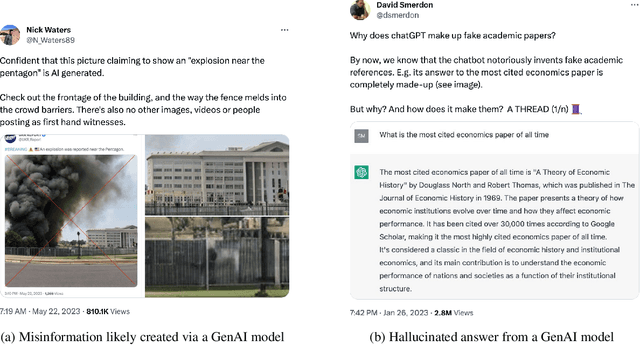
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
An Optimal Energy Efficient Design of Artificial Noise for Preventing Power Leakage based Side-Channel Attacks
Aug 19, 2022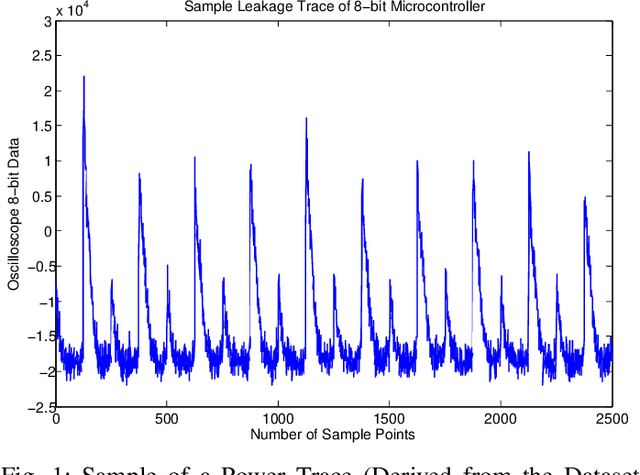

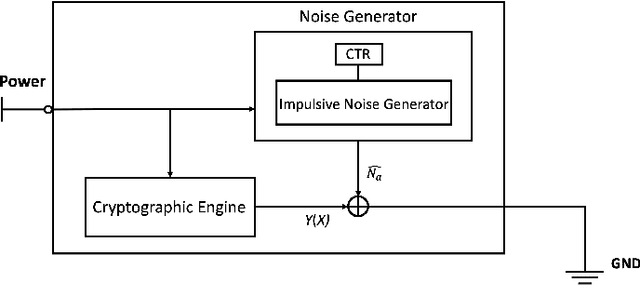
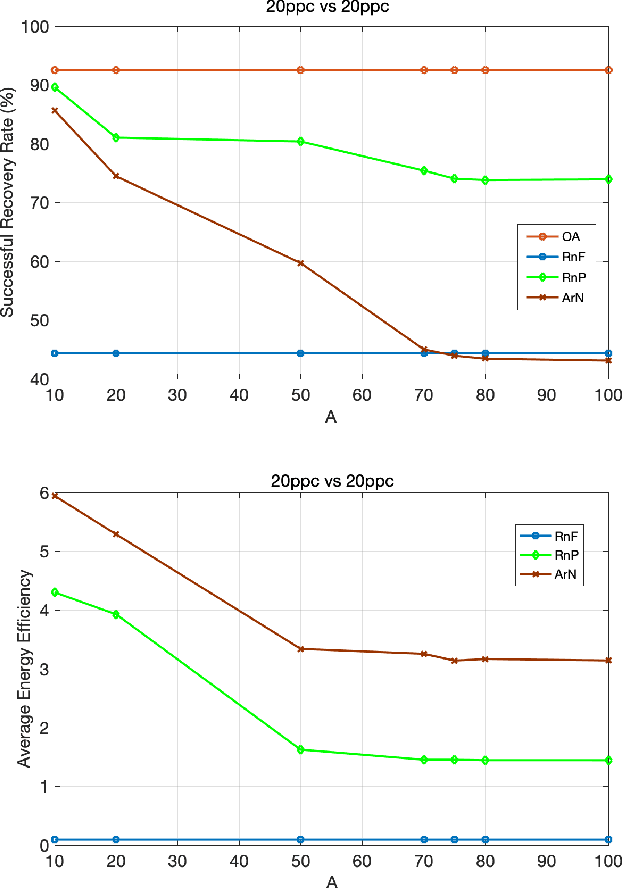
Side-channel attacks (SCAs), which infer secret information (for example secret keys) by exploiting information that leaks from the implementation (such as power consumption), have been shown to be a non-negligible threat to modern cryptographic implementations and devices in recent years. Hence, how to prevent side-channel attacks on cryptographic devices has become an important problem. One of the widely used countermeasures to against power SCAs is the injection of random noise sequences into the raw leakage traces. However, the indiscriminate injection of random noise can lead to significant increases in energy consumption in device, and ways must be found to reduce the amount of energy in noise generation while keeping the side-channel invisible. In this paper, we propose an optimal energy-efficient design for artificial noise generation to prevent side-channel attacks. This approach exploits the sparsity among the leakage traces. We model the side-channel as a communication channel, which allows us to use channel capacity to measure the mutual information between the secret and the leakage traces. For a given energy budget in the noise generation, we obtain the optimal design of the artificial noise injection by solving the side-channel's channel capacity minimization problem. The experimental results also validate the effectiveness of our proposed scheme.
Robust Learning against Logical Adversaries
Jul 01, 2020


Test-time adversarial attacks have posed serious challenges to the robustness of machine learning models, and in many settings the adversarial manipulation needs not be bounded by small $\ell_p$-norms. Motivated by semantic-preserving attacks in security domain, we investigate logical adversaries, a broad class of attackers who create adversarial examples within a reflexive-transitive closure of a logical relation. We analyze the conditions for robustness and propose normalize-and-predict -- a learning framework with provable robustness guarantee. We compare our approach with adversarial training and derive a unified framework that provides the benefits of both approaches.Driven by the theoretical findings, we apply our framework to malware detection. We use our framework to learn new detectors and propose two generic logical attacks to validate model robustness. Experiment results on real-world data set show that attacks using logical relations can evade existing detectors, and our unified framework can significantly enhance model robustness.
COSET: A Benchmark for Evaluating Neural Program Embeddings
May 27, 2019



Neural program embedding can be helpful in analyzing large software, a task that is challenging for traditional logic-based program analyses due to their limited scalability. A key focus of recent machine-learning advances in this area is on modeling program semantics instead of just syntax. Unfortunately evaluating such advances is not obvious, as program semantics does not lend itself to straightforward metrics. In this paper, we introduce a benchmarking framework called COSET for standardizing the evaluation of neural program embeddings. COSET consists of a diverse dataset of programs in source-code format, labeled by human experts according to a number of program properties of interest. A point of novelty is a suite of program transformations included in COSET. These transformations when applied to the base dataset can simulate natural changes to program code due to optimization and refactoring and can serve as a "debugging" tool for classification mistakes. We conducted a pilot study on four prominent models: TreeLSTM, gated graph neural network (GGNN), AST-Path neural network (APNN), and DYPRO. We found that COSET is useful in identifying the strengths and limitations of each model and in pinpointing specific syntactic and semantic characteristics of programs that pose challenges.