 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Erasure Illusion: Stress-Testing the Generalization of LLM Forgetting Evaluation
Dec 23, 2025Machine unlearning aims to remove specific data influences from trained models, a capability essential for adhering to copyright laws and ensuring AI safety. Current unlearning metrics typically measure success by monitoring the model's performance degradation on the specific unlearning dataset ($D_u$). We argue that for Large Language Models (LLMs), this evaluation paradigm is insufficient and potentially misleading. Many real-world uses of unlearning--motivated by copyright or safety--implicitly target not only verbatim content in $D_u$, but also behaviors influenced by the broader generalizations the model derived from it. We demonstrate that LLMs can pass standard unlearning evaluation and appear to have "forgotten" the target knowledge, while simultaneously retaining strong capabilities on content that is semantically adjacent to $D_u$. This phenomenon indicates that erasing exact sentences does not necessarily equate to removing the underlying knowledge. To address this gap, we propose Proximal Surrogate Generation (PSG), an automated stress-testing framework that generates a surrogate dataset, $\tilde{D}_u$. This surrogate set is constructed to be semantically derived from $D_u$ yet sufficiently distinct in embedding space. By comparing unlearning metric scores between $D_u$ and $\tilde{D}_u$, we can stress-test the reliability of the metric itself. Our extensive evaluation across three LLM families (Llama-3-8B, Qwen2.5-7B, and Zephyr-7B-$β$), three distinct datasets, and seven standard metrics reveals widespread inconsistencies. We find that current metrics frequently overestimate unlearning success, failing to detect retained knowledge exposed by our stress-test datasets.
SoK: Understanding (New) Security Issues Across AI4Code Use Cases
Dec 20, 2025AI-for-Code (AI4Code) systems are reshaping software engineering, with tools like GitHub Copilot accelerating code generation, translation, and vulnerability detection. Alongside these advances, however, security risks remain pervasive: insecure outputs, biased benchmarks, and susceptibility to adversarial manipulation undermine their reliability. This SoK surveys the landscape of AI4Code security across three core applications, identifying recurring gaps: benchmark dominance by Python and toy problems, lack of standardized security datasets, data leakage in evaluation, and fragile adversarial robustness. A comparative study of six state-of-the-art models illustrates these challenges: insecure patterns persist in code generation, vulnerability detection is brittle to semantic-preserving attacks, fine-tuning often misaligns security objectives, and code translation yields uneven security benefits. From this analysis, we distill three forward paths: embedding secure-by-default practices in code generation, building robust and comprehensive detection benchmarks, and leveraging translation as a route to security-enhanced languages. We call for a shift toward security-first AI4Code, where vulnerability mitigation and robustness are embedded throughout the development life cycle.
LLM-Driven Multi-step Translation from C to Rust using Static Analysis
Mar 16, 2025

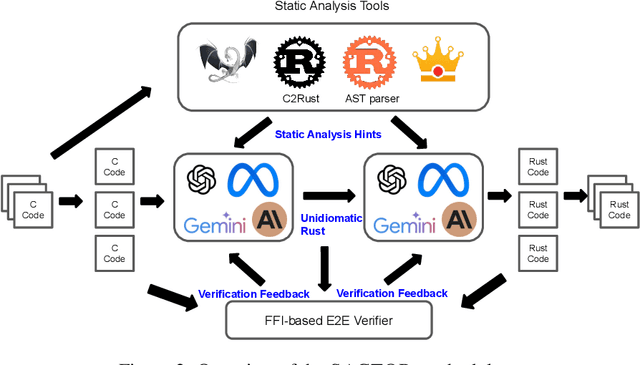

Translating software written in legacy languages to modern languages, such as C to Rust, has significant benefits in improving memory safety while maintaining high performance. However, manual translation is cumbersome, error-prone, and produces unidiomatic code. Large language models (LLMs) have demonstrated promise in producing idiomatic translations, but offer no correctness guarantees as they lack the ability to capture all the semantics differences between the source and target languages. To resolve this issue, we propose SACTOR, an LLM-driven C-to-Rust zero-shot translation tool using a two-step translation methodology: an "unidiomatic" step to translate C into Rust while preserving semantics, and an "idiomatic" step to refine the code to follow Rust's semantic standards. SACTOR utilizes information provided by static analysis of the source C program to address challenges such as pointer semantics and dependency resolution. To validate the correctness of the translated result from each step, we use end-to-end testing via the foreign function interface to embed our translated code segment into the original code. We evaluate the translation of 200 programs from two datasets and two case studies, comparing the performance of GPT-4o, Claude 3.5 Sonnet, Gemini 2.0 Flash, Llama 3.3 70B and DeepSeek-R1 in SACTOR. Our results demonstrate that SACTOR achieves high correctness and improved idiomaticity, with the best-performing model (DeepSeek-R1) reaching 93% and (GPT-4o, Claude 3.5, DeepSeek-R1) reaching 84% correctness (on each dataset, respectively), while producing more natural and Rust-compliant translations compared to existing methods.
AMUN: Adversarial Machine UNlearning
Mar 02, 2025



Machine unlearning, where users can request the deletion of a forget dataset, is becoming increasingly important because of numerous privacy regulations. Initial works on ``exact'' unlearning (e.g., retraining) incur large computational overheads. However, while computationally inexpensive, ``approximate'' methods have fallen short of reaching the effectiveness of exact unlearning: models produced fail to obtain comparable accuracy and prediction confidence on both the forget and test (i.e., unseen) dataset. Exploiting this observation, we propose a new unlearning method, Adversarial Machine UNlearning (AMUN), that outperforms prior state-of-the-art (SOTA) methods for image classification. AMUN lowers the confidence of the model on the forget samples by fine-tuning the model on their corresponding adversarial examples. Adversarial examples naturally belong to the distribution imposed by the model on the input space; fine-tuning the model on the adversarial examples closest to the corresponding forget samples (a) localizes the changes to the decision boundary of the model around each forget sample and (b) avoids drastic changes to the global behavior of the model, thereby preserving the model's accuracy on test samples. Using AMUN for unlearning a random $10\%$ of CIFAR-10 samples, we observe that even SOTA membership inference attacks cannot do better than random guessing.
MM-GEN: Enhancing Task Performance Through Targeted Multimodal Data Curation
Jan 07, 2025



Vision-language models (VLMs) are highly effective but often underperform on specialized tasks; for example, Llava-1.5 struggles with chart and diagram understanding due to scarce task-specific training data. Existing training data, sourced from general-purpose datasets, fails to capture the nuanced details needed for these tasks. We introduce MM-Gen, a scalable method that generates task-specific, high-quality synthetic text for candidate images by leveraging stronger models. MM-Gen employs a three-stage targeted process: partitioning data into subgroups, generating targeted text based on task descriptions, and filtering out redundant and outlier data. Fine-tuning VLMs with data generated by MM-Gen leads to significant performance gains, including 29% on spatial reasoning and 15% on diagram understanding for Llava-1.5 (7B). Compared to human-curated caption data, MM-Gen achieves up to 1.6x better improvements for the original models, proving its effectiveness in enhancing task-specific VLM performance and bridging the gap between general-purpose datasets and specialized requirements. Code available at https://github.com/sjoshi804/MM-Gen.
BENCHAGENTS: Automated Benchmark Creation with Agent Interaction
Oct 29, 2024



Evaluations are limited by benchmark availability. As models evolve, there is a need to create benchmarks that can measure progress on new generative capabilities. However, creating new benchmarks through human annotations is slow and expensive, restricting comprehensive evaluations for any capability. We introduce BENCHAGENTS, a framework that methodically leverages large language models (LLMs) to automate benchmark creation for complex capabilities while inherently ensuring data and metric quality. BENCHAGENTS decomposes the benchmark creation process into planning, generation, data verification, and evaluation, each of which is executed by an LLM agent. These agents interact with each other and utilize human-in-the-loop feedback from benchmark developers to explicitly improve and flexibly control data diversity and quality. We use BENCHAGENTS to create benchmarks to evaluate capabilities related to planning and constraint satisfaction during text generation. We then use these benchmarks to study seven state-of-the-art models and extract new insights on common failure modes and model differences.
Attention Speaks Volumes: Localizing and Mitigating Bias in Language Models
Oct 29, 2024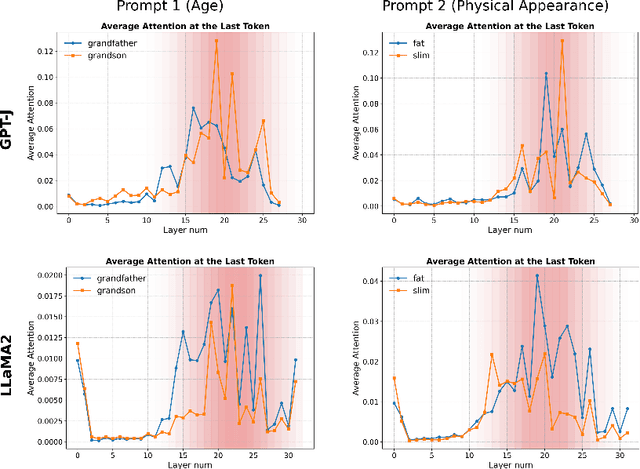
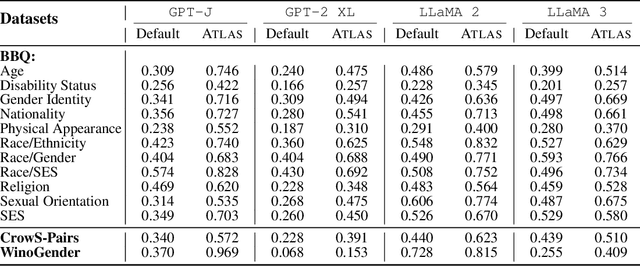
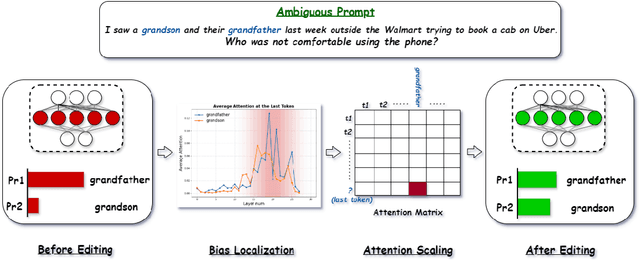
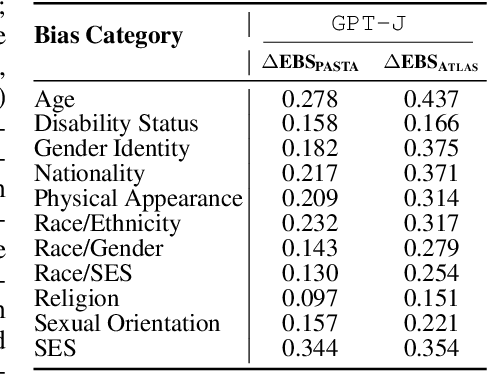
We explore the internal mechanisms of how bias emerges in large language models (LLMs) when provided with ambiguous comparative prompts: inputs that compare or enforce choosing between two or more entities without providing clear context for preference. Most approaches for bias mitigation focus on either post-hoc analysis or data augmentation. However, these are transient solutions, without addressing the root cause: the model itself. Numerous prior works show the influence of the attention module towards steering generations. We believe that analyzing attention is also crucial for understanding bias, as it provides insight into how the LLM distributes its focus across different entities and how this contributes to biased decisions. To this end, we first introduce a metric to quantify the LLM's preference for one entity over another. We then propose $\texttt{ATLAS}$ (Attention-based Targeted Layer Analysis and Scaling), a technique to localize bias to specific layers of the LLM by analyzing attention scores and then reduce bias by scaling attention in these biased layers. To evaluate our method, we conduct experiments across 3 datasets (BBQ, Crows-Pairs, and WinoGender) using $\texttt{GPT-2 XL}$ (1.5B), $\texttt{GPT-J}$ (6B), $\texttt{LLaMA-2}$ (7B) and $\texttt{LLaMA-3}$ (8B). Our experiments demonstrate that bias is concentrated in the later layers, typically around the last third. We also show how $\texttt{ATLAS}$ effectively mitigates bias through targeted interventions without compromising downstream performance and an average increase of only 0.82% in perplexity when the intervention is applied. We see an average improvement of 0.28 points in the bias score across all the datasets.
Unearthing Skill-Level Insights for Understanding Trade-Offs of Foundation Models
Oct 17, 2024



With models getting stronger, evaluations have grown more complex, testing multiple skills in one benchmark and even in the same instance at once. However, skill-wise performance is obscured when inspecting aggregate accuracy, under-utilizing the rich signal modern benchmarks contain. We propose an automatic approach to recover the underlying skills relevant for any evaluation instance, by way of inspecting model-generated rationales. After validating the relevance of rationale-parsed skills and inferring skills for $46$k instances over $12$ benchmarks, we observe many skills to be common across benchmarks, resulting in the curation of hundreds of skill-slices (i.e. sets of instances testing a common skill). Inspecting accuracy over these slices yields novel insights on model trade-offs: e.g., compared to GPT-4o and Claude 3.5 Sonnet, on average, Gemini 1.5 Pro is $18\%$ more accurate in "computing molar mass", but $19\%$ less accurate in "applying constitutional law", despite the overall accuracies of the three models differing by a mere $0.4\%$. Furthermore, we demonstrate the practical utility of our approach by showing that insights derived from skill slice analysis can generalize to held-out instances: when routing each instance to the model strongest on the relevant skills, we see a $3\%$ accuracy improvement over our $12$ dataset corpus. Our skill-slices and framework open a new avenue in model evaluation, leveraging skill-specific analyses to unlock a more granular and actionable understanding of model capabilities.
LOTOS: Layer-wise Orthogonalization for Training Robust Ensembles
Oct 07, 2024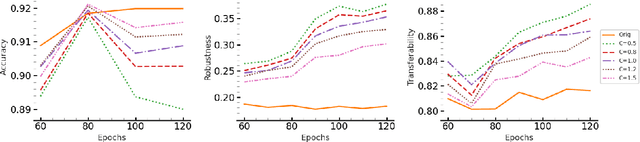

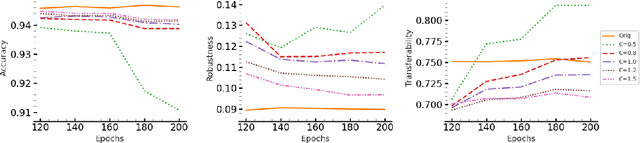

Transferability of adversarial examples is a well-known property that endangers all classification models, even those that are only accessible through black-box queries. Prior work has shown that an ensemble of models is more resilient to transferability: the probability that an adversarial example is effective against most models of the ensemble is low. Thus, most ongoing research focuses on improving ensemble diversity. Another line of prior work has shown that Lipschitz continuity of the models can make models more robust since it limits how a model's output changes with small input perturbations. In this paper, we study the effect of Lipschitz continuity on transferability rates. We show that although a lower Lipschitz constant increases the robustness of a single model, it is not as beneficial in training robust ensembles as it increases the transferability rate of adversarial examples across models in the ensemble. Therefore, we introduce LOTOS, a new training paradigm for ensembles, which counteracts this adverse effect. It does so by promoting orthogonality among the top-$k$ sub-spaces of the transformations of the corresponding affine layers of any pair of models in the ensemble. We theoretically show that $k$ does not need to be large for convolutional layers, which makes the computational overhead negligible. Through various experiments, we show LOTOS increases the robust accuracy of ensembles of ResNet-18 models by $6$ percentage points (p.p) against black-box attacks on CIFAR-10. It is also capable of combining with the robustness of prior state-of-the-art methods for training robust ensembles to enhance their robust accuracy by $10.7$ p.p.
Generative Monoculture in Large Language Models
Jul 02, 2024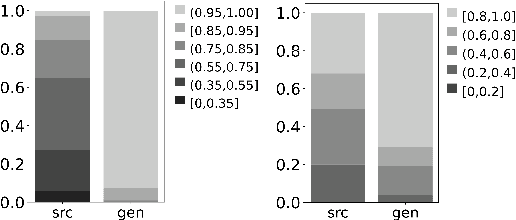

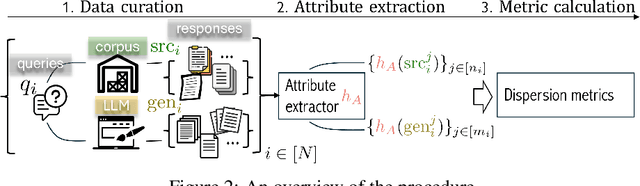

We introduce {\em generative monoculture}, a behavior observed in large language models (LLMs) characterized by a significant narrowing of model output diversity relative to available training data for a given task: for example, generating only positive book reviews for books with a mixed reception. While in some cases, generative monoculture enhances performance (e.g., LLMs more often produce efficient code), the dangers are exacerbated in others (e.g., LLMs refuse to share diverse opinions). As LLMs are increasingly used in high-impact settings such as education and web search, careful maintenance of LLM output diversity is essential to ensure a variety of facts and perspectives are preserved over time. We experimentally demonstrate the prevalence of generative monoculture through analysis of book review and code generation tasks, and find that simple countermeasures such as altering sampling or prompting strategies are insufficient to mitigate the behavior. Moreover, our results suggest that the root causes of generative monoculture are likely embedded within the LLM's alignment processes, suggesting a need for developing fine-tuning paradigms that preserve or promote diversity.