 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
DatBench: Discriminative, Faithful, and Efficient VLM Evaluations
Jan 05, 2026Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.
Luxical: High-Speed Lexical-Dense Text Embeddings
Dec 11, 2025Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at https://github.com/datologyai/luxical.
Attention Speaks Volumes: Localizing and Mitigating Bias in Language Models
Oct 29, 2024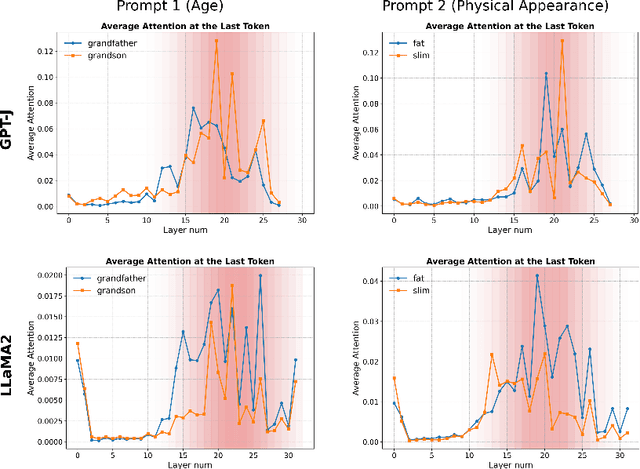
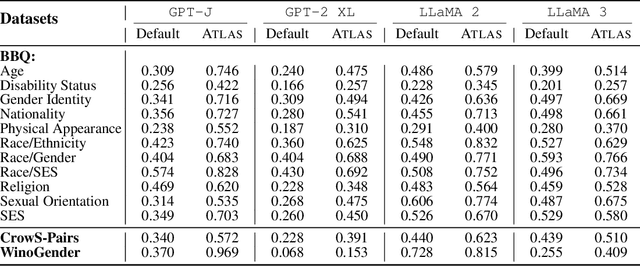
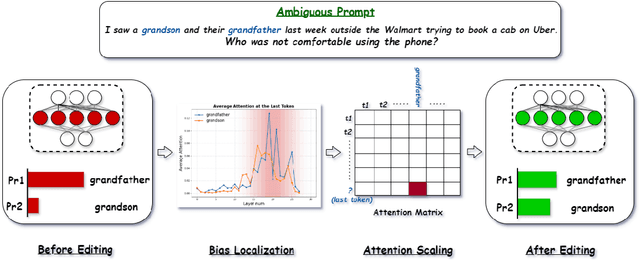
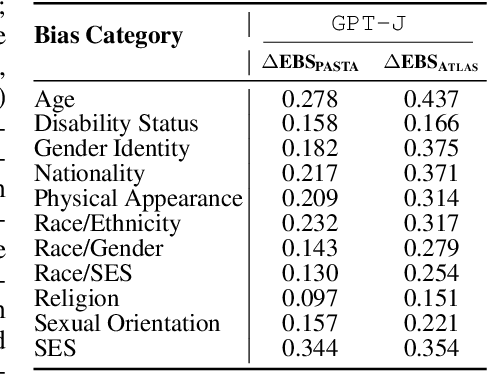
We explore the internal mechanisms of how bias emerges in large language models (LLMs) when provided with ambiguous comparative prompts: inputs that compare or enforce choosing between two or more entities without providing clear context for preference. Most approaches for bias mitigation focus on either post-hoc analysis or data augmentation. However, these are transient solutions, without addressing the root cause: the model itself. Numerous prior works show the influence of the attention module towards steering generations. We believe that analyzing attention is also crucial for understanding bias, as it provides insight into how the LLM distributes its focus across different entities and how this contributes to biased decisions. To this end, we first introduce a metric to quantify the LLM's preference for one entity over another. We then propose $\texttt{ATLAS}$ (Attention-based Targeted Layer Analysis and Scaling), a technique to localize bias to specific layers of the LLM by analyzing attention scores and then reduce bias by scaling attention in these biased layers. To evaluate our method, we conduct experiments across 3 datasets (BBQ, Crows-Pairs, and WinoGender) using $\texttt{GPT-2 XL}$ (1.5B), $\texttt{GPT-J}$ (6B), $\texttt{LLaMA-2}$ (7B) and $\texttt{LLaMA-3}$ (8B). Our experiments demonstrate that bias is concentrated in the later layers, typically around the last third. We also show how $\texttt{ATLAS}$ effectively mitigates bias through targeted interventions without compromising downstream performance and an average increase of only 0.82% in perplexity when the intervention is applied. We see an average improvement of 0.28 points in the bias score across all the datasets.
Designing Informative Metrics for Few-Shot Example Selection
Mar 06, 2024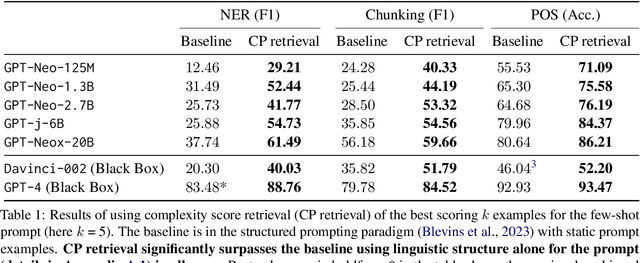
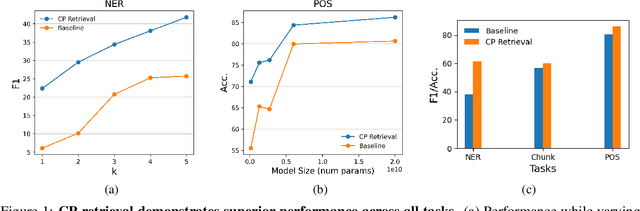


Pretrained language models (PLMs) have shown remarkable few-shot learning capabilities when provided with properly formatted examples. However, selecting the "best" examples remains an open challenge. We propose a complexity-based prompt selection approach for sequence tagging tasks. This approach avoids the training of a dedicated model for selection of examples, and instead uses certain metrics to align the syntactico-semantic complexity of test sentences and examples. We use both sentence- and word-level metrics to match the complexity of examples to the (test) sentence being considered. Our results demonstrate that our approach extracts greater performance from PLMs: it achieves state-of-the-art performance on few-shot NER, achieving a 5% absolute improvement in F1 score on the CoNLL2003 dataset for GPT-4. We also see large gains of upto 28.85 points (F1/Acc.) in smaller models like GPT-j-6B.