 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Informative Metrics for Few-Shot Example Selection
Paper and Code
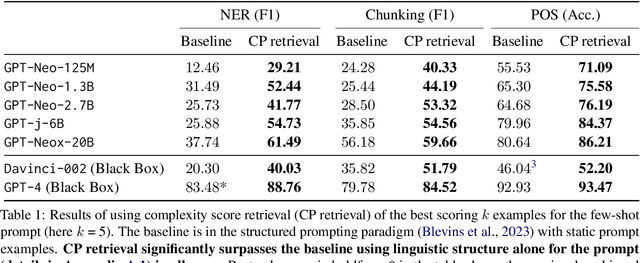
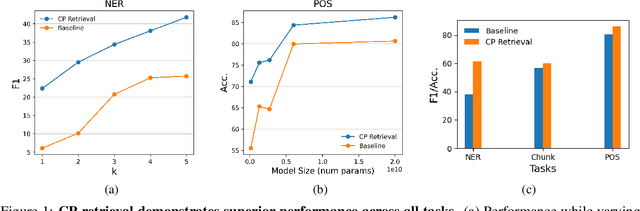


Pretrained language models (PLMs) have shown remarkable few-shot learning capabilities when provided with properly formatted examples. However, selecting the "best" examples remains an open challenge. We propose a complexity-based prompt selection approach for sequence tagging tasks. This approach avoids the training of a dedicated model for selection of examples, and instead uses certain metrics to align the syntactico-semantic complexity of test sentences and examples. We use both sentence- and word-level metrics to match the complexity of examples to the (test) sentence being considered. Our results demonstrate that our approach extracts greater performance from PLMs: it achieves state-of-the-art performance on few-shot NER, achieving a 5% absolute improvement in F1 score on the CoNLL2003 dataset for GPT-4. We also see large gains of upto 28.85 points (F1/Acc.) in smaller models like GPT-j-6B.