 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Understanding (New) Security Issues Across AI4Code Use Cases
Dec 20, 2025AI-for-Code (AI4Code) systems are reshaping software engineering, with tools like GitHub Copilot accelerating code generation, translation, and vulnerability detection. Alongside these advances, however, security risks remain pervasive: insecure outputs, biased benchmarks, and susceptibility to adversarial manipulation undermine their reliability. This SoK surveys the landscape of AI4Code security across three core applications, identifying recurring gaps: benchmark dominance by Python and toy problems, lack of standardized security datasets, data leakage in evaluation, and fragile adversarial robustness. A comparative study of six state-of-the-art models illustrates these challenges: insecure patterns persist in code generation, vulnerability detection is brittle to semantic-preserving attacks, fine-tuning often misaligns security objectives, and code translation yields uneven security benefits. From this analysis, we distill three forward paths: embedding secure-by-default practices in code generation, building robust and comprehensive detection benchmarks, and leveraging translation as a route to security-enhanced languages. We call for a shift toward security-first AI4Code, where vulnerability mitigation and robustness are embedded throughout the development life cycle.
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.
PyVision: Agentic Vision with Dynamic Tooling
Jul 10, 2025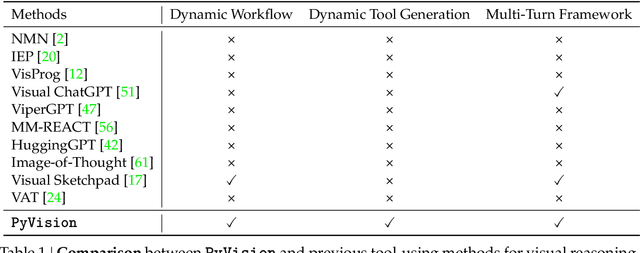
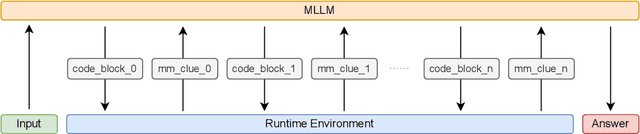
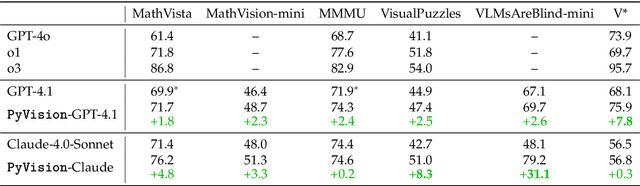
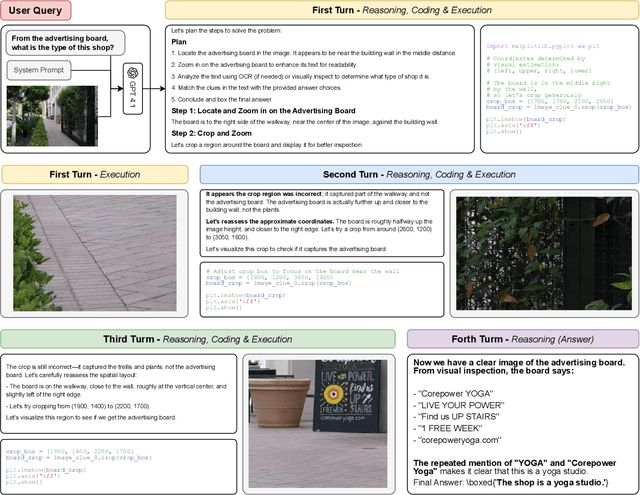
LLMs are increasingly deployed as agents, systems capable of planning, reasoning, and dynamically calling external tools. However, in visual reasoning, prior approaches largely remain limited by predefined workflows and static toolsets. In this report, we present PyVision, an interactive, multi-turn framework that enables MLLMs to autonomously generate, execute, and refine Python-based tools tailored to the task at hand, unlocking flexible and interpretable problem-solving. We develop a taxonomy of the tools created by PyVision and analyze their usage across a diverse set of benchmarks. Quantitatively, PyVision achieves consistent performance gains, boosting GPT-4.1 by +7.8% on V* and Claude-4.0-Sonnet by +31.1% on VLMsAreBlind-mini. These results point to a broader shift: dynamic tooling allows models not just to use tools, but to invent them, advancing toward more agentic visual reasoning.
Learning Optimal Multimodal Information Bottleneck Representations
May 26, 2025Leveraging high-quality joint representations from multimodal data can greatly enhance model performance in various machine-learning based applications. Recent multimodal learning methods, based on the multimodal information bottleneck (MIB) principle, aim to generate optimal MIB with maximal task-relevant information and minimal superfluous information via regularization. However, these methods often set ad hoc regularization weights and overlook imbalanced task-relevant information across modalities, limiting their ability to achieve optimal MIB. To address this gap, we propose a novel multimodal learning framework, Optimal Multimodal Information Bottleneck (OMIB), whose optimization objective guarantees the achievability of optimal MIB by setting the regularization weight within a theoretically derived bound. OMIB further addresses imbalanced task-relevant information by dynamically adjusting regularization weights per modality, promoting the inclusion of all task-relevant information. Moreover, we establish a solid information-theoretical foundation for OMIB's optimization and implement it under the variational approximation framework for computational efficiency. Finally, we empirically validate the OMIB's theoretical properties on synthetic data and demonstrate its superiority over the state-of-the-art benchmark methods in various downstream tasks.
Sybil-based Virtual Data Poisoning Attacks in Federated Learning
May 15, 2025



Federated learning is vulnerable to poisoning attacks by malicious adversaries. Existing methods often involve high costs to achieve effective attacks. To address this challenge, we propose a sybil-based virtual data poisoning attack, where a malicious client generates sybil nodes to amplify the poisoning model's impact. To reduce neural network computational complexity, we develop a virtual data generation method based on gradient matching. We also design three schemes for target model acquisition, applicable to online local, online global, and offline scenarios. In simulation, our method outperforms other attack algorithms since our method can obtain a global target model under non-independent uniformly distributed data.
TS-Diff: Two-Stage Diffusion Model for Low-Light RAW Image Enhancement
May 07, 2025This paper presents a novel Two-Stage Diffusion Model (TS-Diff) for enhancing extremely low-light RAW images. In the pre-training stage, TS-Diff synthesizes noisy images by constructing multiple virtual cameras based on a noise space. Camera Feature Integration (CFI) modules are then designed to enable the model to learn generalizable features across diverse virtual cameras. During the aligning stage, CFIs are averaged to create a target-specific CFI$^T$, which is fine-tuned using a small amount of real RAW data to adapt to the noise characteristics of specific cameras. A structural reparameterization technique further simplifies CFI$^T$ for efficient deployment. To address color shifts during the diffusion process, a color corrector is introduced to ensure color consistency by dynamically adjusting global color distributions. Additionally, a novel dataset, QID, is constructed, featuring quantifiable illumination levels and a wide dynamic range, providing a comprehensive benchmark for training and evaluation under extreme low-light conditions. Experimental results demonstrate that TS-Diff achieves state-of-the-art performance on multiple datasets, including QID, SID, and ELD, excelling in denoising, generalization, and color consistency across various cameras and illumination levels. These findings highlight the robustness and versatility of TS-Diff, making it a practical solution for low-light imaging applications. Source codes and models are available at https://github.com/CircccleK/TS-Diff
LeX-Art: Rethinking Text Generation via Scalable High-Quality Data Synthesis
Mar 27, 2025We introduce LeX-Art, a comprehensive suite for high-quality text-image synthesis that systematically bridges the gap between prompt expressiveness and text rendering fidelity. Our approach follows a data-centric paradigm, constructing a high-quality data synthesis pipeline based on Deepseek-R1 to curate LeX-10K, a dataset of 10K high-resolution, aesthetically refined 1024$\times$1024 images. Beyond dataset construction, we develop LeX-Enhancer, a robust prompt enrichment model, and train two text-to-image models, LeX-FLUX and LeX-Lumina, achieving state-of-the-art text rendering performance. To systematically evaluate visual text generation, we introduce LeX-Bench, a benchmark that assesses fidelity, aesthetics, and alignment, complemented by Pairwise Normalized Edit Distance (PNED), a novel metric for robust text accuracy evaluation. Experiments demonstrate significant improvements, with LeX-Lumina achieving a 79.81% PNED gain on CreateBench, and LeX-FLUX outperforming baselines in color (+3.18%), positional (+4.45%), and font accuracy (+3.81%). Our codes, models, datasets, and demo are publicly available.
ScaleMAI: Accelerating the Development of Trusted Datasets and AI Models
Jan 06, 2025

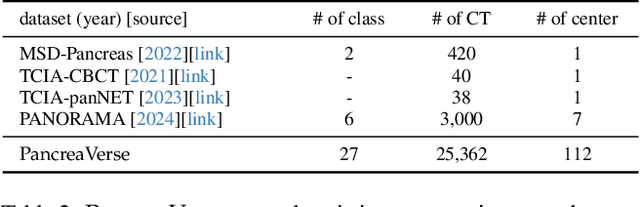

Building trusted datasets is critical for transparent and responsible Medical AI (MAI) research, but creating even small, high-quality datasets can take years of effort from multidisciplinary teams. This process often delays AI benefits, as human-centric data creation and AI-centric model development are treated as separate, sequential steps. To overcome this, we propose ScaleMAI, an agent of AI-integrated data curation and annotation, allowing data quality and AI performance to improve in a self-reinforcing cycle and reducing development time from years to months. We adopt pancreatic tumor detection as an example. First, ScaleMAI progressively creates a dataset of 25,362 CT scans, including per-voxel annotations for benign/malignant tumors and 24 anatomical structures. Second, through progressive human-in-the-loop iterations, ScaleMAI provides Flagship AI Model that can approach the proficiency of expert annotators (30-year experience) in detecting pancreatic tumors. Flagship Model significantly outperforms models developed from smaller, fixed-quality datasets, with substantial gains in tumor detection (+14%), segmentation (+5%), and classification (72%) on three prestigious benchmarks. In summary, ScaleMAI transforms the speed, scale, and reliability of medical dataset creation, paving the way for a variety of impactful, data-driven applications.
Text-Driven Tumor Synthesis
Dec 24, 2024



Tumor synthesis can generate examples that AI often misses or over-detects, improving AI performance by training on these challenging cases. However, existing synthesis methods, which are typically unconditional -- generating images from random variables -- or conditioned only by tumor shapes, lack controllability over specific tumor characteristics such as texture, heterogeneity, boundaries, and pathology type. As a result, the generated tumors may be overly similar or duplicates of existing training data, failing to effectively address AI's weaknesses. We propose a new text-driven tumor synthesis approach, termed TextoMorph, that provides textual control over tumor characteristics. This is particularly beneficial for examples that confuse the AI the most, such as early tumor detection (increasing Sensitivity by +8.5%), tumor segmentation for precise radiotherapy (increasing DSC by +6.3%), and classification between benign and malignant tumors (improving Sensitivity by +8.2%). By incorporating text mined from radiology reports into the synthesis process, we increase the variability and controllability of the synthetic tumors to target AI's failure cases more precisely. Moreover, TextoMorph uses contrastive learning across different texts and CT scans, significantly reducing dependence on scarce image-report pairs (only 141 pairs used in this study) by leveraging a large corpus of 34,035 radiology reports. Finally, we have developed rigorous tests to evaluate synthetic tumors, including Text-Driven Visual Turing Test and Radiomics Pattern Analysis, showing that our synthetic tumors is realistic and diverse in texture, heterogeneity, boundaries, and pathology.
SusGen-GPT: A Data-Centric LLM for Financial NLP and Sustainability Report Generation
Dec 14, 2024The rapid growth of the financial sector and the rising focus on Environmental, Social, and Governance (ESG) considerations highlight the need for advanced NLP tools. However, open-source LLMs proficient in both finance and ESG domains remain scarce. To address this gap, we introduce SusGen-30K, a category-balanced dataset comprising seven financial NLP tasks and ESG report generation, and propose TCFD-Bench, a benchmark for evaluating sustainability report generation. Leveraging this dataset, we developed SusGen-GPT, a suite of models achieving state-of-the-art performance across six adapted and two off-the-shelf tasks, trailing GPT-4 by only 2% despite using 7-8B parameters compared to GPT-4's 1,700B. Based on this, we propose the SusGen system, integrated with Retrieval-Augmented Generation (RAG), to assist in sustainability report generation. This work demonstrates the efficiency of our approach, advancing research in finance and ESG.