 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly and Prediagnostic Detection of Pancreatic Cancer from Computed Tomography
Jan 29, 2026Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest solid malignancies, is often detected at a late and inoperable stage. Retrospective reviews of prediagnostic CT scans, when conducted by expert radiologists aware that the patient later developed PDAC, frequently reveal lesions that were previously overlooked. To help detecting these lesions earlier, we developed an automated system named ePAI (early Pancreatic cancer detection with Artificial Intelligence). It was trained on data from 1,598 patients from a single medical center. In the internal test involving 1,009 patients, ePAI achieved an area under the receiver operating characteristic curve (AUC) of 0.939-0.999, a sensitivity of 95.3%, and a specificity of 98.7% for detecting small PDAC less than 2 cm in diameter, precisely localizing PDAC as small as 2 mm. In an external test involving 7,158 patients across 6 centers, ePAI achieved an AUC of 0.918-0.945, a sensitivity of 91.5%, and a specificity of 88.0%, precisely localizing PDAC as small as 5 mm. Importantly, ePAI detected PDACs on prediagnostic CT scans obtained 3 to 36 months before clinical diagnosis that had originally been overlooked by radiologists. It successfully detected and localized PDACs in 75 of 159 patients, with a median lead time of 347 days before clinical diagnosis. Our multi-reader study showed that ePAI significantly outperformed 30 board-certified radiologists by 50.3% (P < 0.05) in sensitivity while maintaining a comparable specificity of 95.4% in detecting PDACs early and prediagnostic. These findings suggest its potential of ePAI as an assistive tool to improve early detection of pancreatic cancer.
RadGPT: Constructing 3D Image-Text Tumor Datasets
Jan 08, 2025With over 85 million CT scans performed annually in the United States, creating tumor-related reports is a challenging and time-consuming task for radiologists. To address this need, we present RadGPT, an Anatomy-Aware Vision-Language AI Agent for generating detailed reports from CT scans. RadGPT first segments tumors, including benign cysts and malignant tumors, and their surrounding anatomical structures, then transforms this information into both structured reports and narrative reports. These reports provide tumor size, shape, location, attenuation, volume, and interactions with surrounding blood vessels and organs. Extensive evaluation on unseen hospitals shows that RadGPT can produce accurate reports, with high sensitivity/specificity for small tumor (<2 cm) detection: 80/73% for liver tumors, 92/78% for kidney tumors, and 77/77% for pancreatic tumors. For large tumors, sensitivity ranges from 89% to 97%. The results significantly surpass the state-of-the-art in abdominal CT report generation. RadGPT generated reports for 17 public datasets. Through radiologist review and refinement, we have ensured the reports' accuracy, and created the first publicly available image-text 3D medical dataset, comprising over 1.8 million text tokens and 2.7 million images from 9,262 CT scans, including 2,947 tumor scans/reports of 8,562 tumor instances. Our reports can: (1) localize tumors in eight liver sub-segments and three pancreatic sub-segments annotated per-voxel; (2) determine pancreatic tumor stage (T1-T4) in 260 reports; and (3) present individual analyses of multiple tumors--rare in human-made reports. Importantly, 948 of the reports are for early-stage tumors.
Touchstone Benchmark: Are We on the Right Way for Evaluating AI Algorithms for Medical Segmentation?
Nov 06, 2024



How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks--which, differing from algorithms, are more flexible and can support different algorithms--including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
Label Critic: Design Data Before Models
Nov 05, 2024

As medical datasets rapidly expand, creating detailed annotations of different body structures becomes increasingly expensive and time-consuming. We consider that requesting radiologists to create detailed annotations is unnecessarily burdensome and that pre-existing AI models can largely automate this process. Following the spirit don't use a sledgehammer on a nut, we find that, rather than creating annotations from scratch, radiologists only have to review and edit errors if the Best-AI Labels have mistakes. To obtain the Best-AI Labels among multiple AI Labels, we developed an automatic tool, called Label Critic, that can assess label quality through tireless pairwise comparisons. Extensive experiments demonstrate that, when incorporated with our developed Image-Prompt pairs, pre-existing Large Vision-Language Models (LVLM), trained on natural images and texts, achieve 96.5% accuracy when choosing the best label in a pair-wise comparison, without extra fine-tuning. By transforming the manual annotation task (30-60 min/scan) into an automatic comparison task (15 sec/scan), we effectively reduce the manual efforts required from radiologists by an order of magnitude. When the Best-AI Labels are sufficiently accurate (81% depending on body structures), they will be directly adopted as the gold-standard annotations for the dataset, with lower-quality AI Labels automatically discarded. Label Critic can also check the label quality of a single AI Label with 71.8% accuracy when no alternatives are available for comparison, prompting radiologists to review and edit if the estimated quality is low (19% depending on body structures).
Explanation is All You Need in Distillation: Mitigating Bias and Shortcut Learning
Jul 13, 2024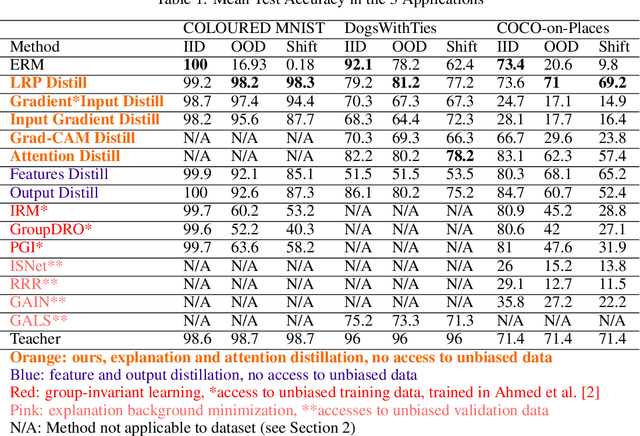


Bias and spurious correlations in data can cause shortcut learning, undermining out-of-distribution (OOD) generalization in deep neural networks. Most methods require unbiased data during training (and/or hyper-parameter tuning) to counteract shortcut learning. Here, we propose the use of explanation distillation to hinder shortcut learning. The technique does not assume any access to unbiased data, and it allows an arbitrarily sized student network to learn the reasons behind the decisions of an unbiased teacher, such as a vision-language model or a network processing debiased images. We found that it is possible to train a neural network with explanation (e.g by Layer Relevance Propagation, LRP) distillation only, and that the technique leads to high resistance to shortcut learning, surpassing group-invariant learning, explanation background minimization, and alternative distillation techniques. In the COLOURED MNIST dataset, LRP distillation achieved 98.2% OOD accuracy, while deep feature distillation and IRM achieved 92.1% and 60.2%, respectively. In COCO-on-Places, the undesirable generalization gap between in-distribution and OOD accuracy is only of 4.4% for LRP distillation, while the other two techniques present gaps of 15.1% and 52.1%, respectively.
Faster ISNet for Background Bias Mitigation on Deep Neural Networks
Jan 16, 2024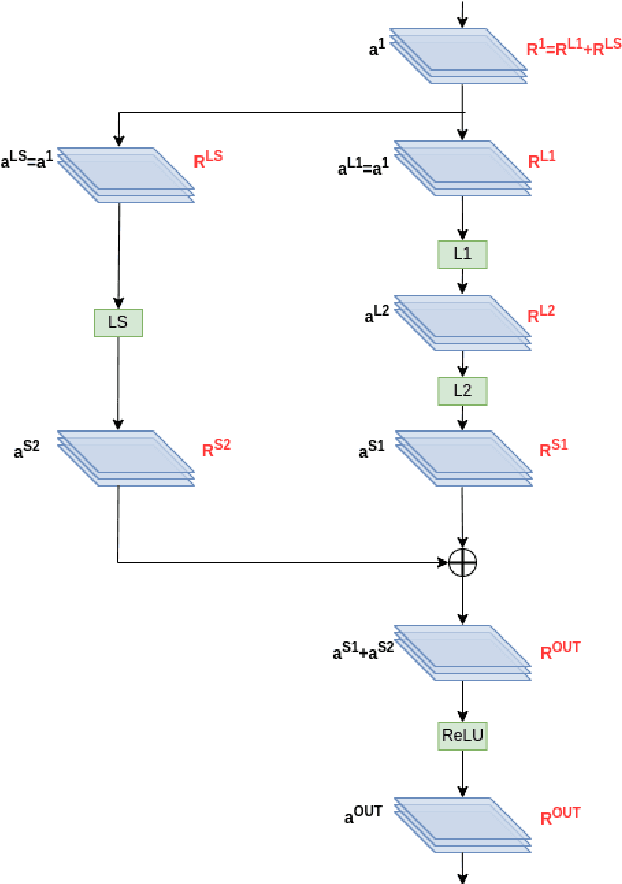
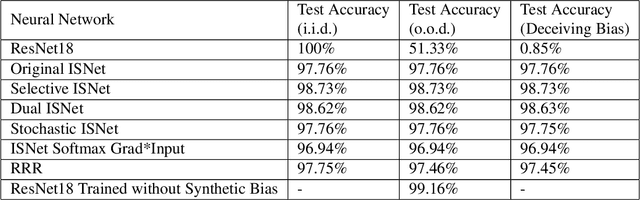
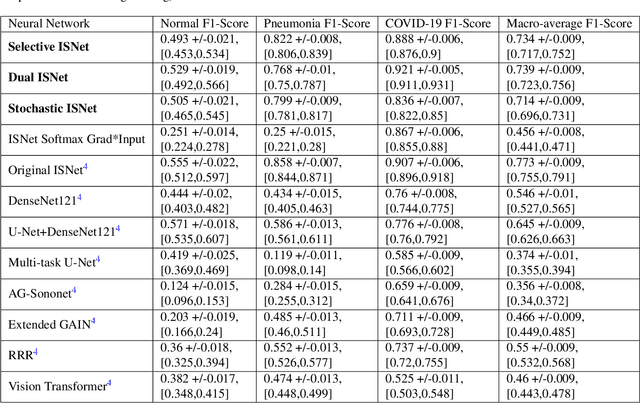
Image background features can constitute background bias (spurious correlations) and impact deep classifiers decisions, causing shortcut learning (Clever Hans effect) and reducing the generalization skill on real-world data. The concept of optimizing Layer-wise Relevance Propagation (LRP) heatmaps, to improve classifier behavior, was recently introduced by a neural network architecture named ISNet. It minimizes background relevance in LRP maps, to mitigate the influence of image background features on deep classifiers decisions, hindering shortcut learning and improving generalization. For each training image, the original ISNet produces one heatmap per possible class in the classification task, hence, its training time scales linearly with the number of classes. Here, we introduce reformulated architectures that allow the training time to become independent from this number, rendering the optimization process much faster. We challenged the enhanced models utilizing the MNIST dataset with synthetic background bias, and COVID-19 detection in chest X-rays, an application that is prone to shortcut learning due to background bias. The trained models minimized background attention and hindered shortcut learning, while retaining high accuracy. Considering external (out-of-distribution) test datasets, they consistently proved more accurate than multiple state-of-the-art deep neural network architectures, including a dedicated image semantic segmenter followed by a classifier. The architectures presented here represent a potentially massive improvement in training speed over the original ISNet, thus introducing LRP optimization into a gamut of applications that could not be feasibly handled by the original model.