 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Small Language Models and Small Reasoning Language Models on System Log Severity Classification
Jan 12, 2026System logs are crucial for monitoring and diagnosing modern computing infrastructure, but their scale and complexity require reliable and efficient automated interpretation. Since severity levels are predefined metadata in system log messages, having a model merely classify them offers limited standalone practical value, revealing little about its underlying ability to interpret system logs. We argue that severity classification is more informative when treated as a benchmark for probing runtime log comprehension rather than as an end task. Using real-world journalctl data from Linux production servers, we evaluate nine small language models (SLMs) and small reasoning language models (SRLMs) under zero-shot, few-shot, and retrieval-augmented generation (RAG) prompting. The results reveal strong stratification. Qwen3-4B achieves the highest accuracy at 95.64% with RAG, while Gemma3-1B improves from 20.25% under few-shot prompting to 85.28% with RAG. Notably, the tiny Qwen3-0.6B reaches 88.12% accuracy despite weak performance without retrieval. In contrast, several SRLMs, including Qwen3-1.7B and DeepSeek-R1-Distill-Qwen-1.5B, degrade substantially when paired with RAG. Efficiency measurements further separate models: most Gemma and Llama variants complete inference in under 1.2 seconds per log, whereas Phi-4-Mini-Reasoning exceeds 228 seconds per log while achieving <10% accuracy. These findings suggest that (1) architectural design, (2) training objectives, and (3) the ability to integrate retrieved context under strict output constraints jointly determine performance. By emphasizing small, deployable models, this benchmark aligns with real-time requirements of digital twin (DT) systems and shows that severity classification serves as a lens for evaluating model competence and real-time deployability, with implications for root cause analysis (RCA) and broader DT integration.
Jigsaw-R1: A Study of Rule-based Visual Reinforcement Learning with Jigsaw Puzzles
May 29, 2025The application of rule-based reinforcement learning (RL) to multimodal large language models (MLLMs) introduces unique challenges and potential deviations from findings in text-only domains, particularly for perception-heavy tasks. This paper provides a comprehensive study of rule-based visual RL using jigsaw puzzles as a structured experimental framework, revealing several key findings. \textit{Firstly,} we find that MLLMs, initially performing near to random guessing on simple puzzles, achieve near-perfect accuracy and generalize to complex, unseen configurations through fine-tuning. \textit{Secondly,} training on jigsaw puzzles can induce generalization to other visual tasks, with effectiveness tied to specific task configurations. \textit{Thirdly,} MLLMs can learn and generalize with or without explicit reasoning, though open-source models often favor direct answering. Consequently, even when trained for step-by-step reasoning, they can ignore the thinking process in deriving the final answer. \textit{Fourthly,} we observe that complex reasoning patterns appear to be pre-existing rather than emergent, with their frequency increasing alongside training and task difficulty. \textit{Finally,} our results demonstrate that RL exhibits more effective generalization than Supervised Fine-Tuning (SFT), and an initial SFT cold start phase can hinder subsequent RL optimization. Although these observations are based on jigsaw puzzles and may vary across other visual tasks, this research contributes a valuable piece of jigsaw to the larger puzzle of collective understanding rule-based visual RL and its potential in multimodal learning. The code is available at: \href{https://github.com/zifuwanggg/Jigsaw-R1}{https://github.com/zifuwanggg/Jigsaw-R1}.
Touchstone Benchmark: Are We on the Right Way for Evaluating AI Algorithms for Medical Segmentation?
Nov 06, 2024



How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks--which, differing from algorithms, are more flexible and can support different algorithms--including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
Can LLMs Learn by Teaching? A Preliminary Study
Jun 20, 2024



Teaching to improve student models (e.g., knowledge distillation) is an extensively studied methodology in LLMs. However, for humans, teaching not only improves students but also improves teachers. We ask: Can LLMs also learn by teaching (LbT)? If yes, we can potentially unlock the possibility of continuously advancing the models without solely relying on human-produced data or stronger models. In this paper, we provide a preliminary exploration of this ambitious agenda. We show that LbT ideas can be incorporated into existing LLM training/prompting pipelines and provide noticeable improvements. Specifically, we design three methods, each mimicking one of the three levels of LbT in humans: observing students' feedback, learning from the feedback, and learning iteratively, with the goals of improving answer accuracy without training and improving models' inherent capability with fine-tuning. The findings are encouraging. For example, similar to LbT in human, we see that: (1) LbT can induce weak-to-strong generalization: strong models can improve themselves by teaching other weak models; (2) Diversity in students might help: teaching multiple students could be better than teaching one student or the teacher itself. We hope that this early promise can inspire future research on LbT and more broadly adopting the advanced techniques in education to improve LLMs. The code is available at https://github.com/imagination-research/lbt.
Revisiting Evaluation Metrics for Semantic Segmentation: Optimization and Evaluation of Fine-grained Intersection over Union
Oct 30, 2023Semantic segmentation datasets often exhibit two types of imbalance: \textit{class imbalance}, where some classes appear more frequently than others and \textit{size imbalance}, where some objects occupy more pixels than others. This causes traditional evaluation metrics to be biased towards \textit{majority classes} (e.g. overall pixel-wise accuracy) and \textit{large objects} (e.g. mean pixel-wise accuracy and per-dataset mean intersection over union). To address these shortcomings, we propose the use of fine-grained mIoUs along with corresponding worst-case metrics, thereby offering a more holistic evaluation of segmentation techniques. These fine-grained metrics offer less bias towards large objects, richer statistical information, and valuable insights into model and dataset auditing. Furthermore, we undertake an extensive benchmark study, where we train and evaluate 15 modern neural networks with the proposed metrics on 12 diverse natural and aerial segmentation datasets. Our benchmark study highlights the necessity of not basing evaluations on a single metric and confirms that fine-grained mIoUs reduce the bias towards large objects. Moreover, we identify the crucial role played by architecture designs and loss functions, which lead to best practices in optimizing fine-grained metrics. The code is available at \href{https://github.com/zifuwanggg/JDTLosses}{https://github.com/zifuwanggg/JDTLosses}.
Dice Semimetric Losses: Optimizing the Dice Score with Soft Labels
Apr 01, 2023



The soft Dice loss (SDL) has taken a pivotal role in many automated segmentation pipelines in the medical imaging community. Over the last years, some reasons behind its superior functioning have been uncovered and further optimizations have been explored. However, there is currently no implementation that supports its direct use in settings with soft labels. Hence, a synergy between the use of SDL and research leveraging the use of soft labels, also in the context of model calibration, is still missing. In this work, we introduce Dice semimetric losses (DMLs), which (i) are by design identical to SDL in a standard setting with hard labels, but (ii) can be used in settings with soft labels. Our experiments on the public QUBIQ, LiTS and KiTS benchmarks confirm the potential synergy of DMLs with soft labels (e.g. averaging, label smoothing, and knowledge distillation) over hard labels (e.g. majority voting and random selection). As a result, we obtain superior Dice scores and model calibration, which supports the wider adoption of DMLs in practice. Code is available at \href{https://github.com/zifuwanggg/JDTLosses}{https://github.com/zifuwanggg/JDTLosses}.
Jaccard Metric Losses: Optimizing the Jaccard Index with Soft Labels
Feb 11, 2023



IoU losses are surrogates that directly optimize the Jaccard index. In semantic segmentation, IoU losses are shown to perform better with respect to the Jaccard index measure than pixel-wise losses such as the cross-entropy loss. The most notable IoU losses are the soft Jaccard loss and the Lovasz-Softmax loss. However, these losses are incompatible with soft labels which are ubiquitous in machine learning. In this paper, we propose Jaccard metric losses (JMLs), which are variants of the soft Jaccard loss, and are compatible with soft labels. With JMLs, we study two of the most popular use cases of soft labels: label smoothing and knowledge distillation. With a variety of architectures, our experiments show significant improvements over the cross-entropy loss on three semantic segmentation datasets (Cityscapes, PASCAL VOC and DeepGlobe Land), and our simple approach outperforms state-of-the-art knowledge distillation methods by a large margin. Our source code is available at: \href{https://github.com/zifuwanggg/JDML}{https://github.com/zifuwanggg/JDML}.
MRF-UNets: Searching UNet with Markov Random Fields
Jul 13, 2022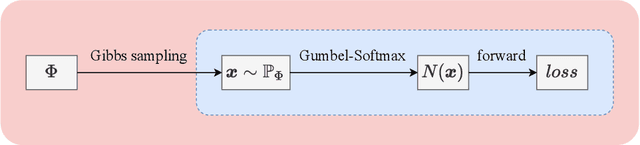
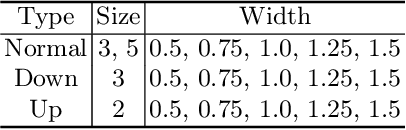
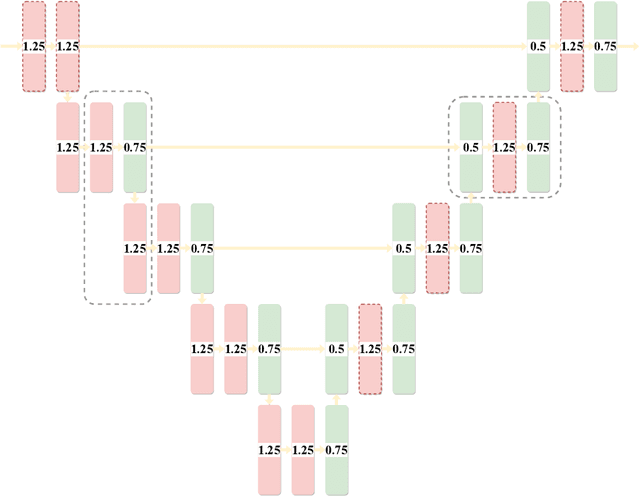
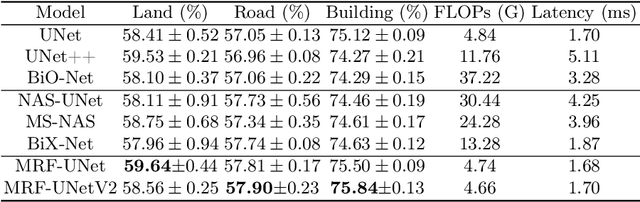
UNet [27] is widely used in semantic segmentation due to its simplicity and effectiveness. However, its manually-designed architecture is applied to a large number of problem settings, either with no architecture optimizations, or with manual tuning, which is time consuming and can be sub-optimal. In this work, firstly, we propose Markov Random Field Neural Architecture Search (MRF-NAS) that extends and improves the recent Adaptive and Optimal Network Width Search (AOWS) method [4] with (i) a more general MRF framework (ii) diverse M-best loopy inference (iii) differentiable parameter learning. This provides the necessary NAS framework to efficiently explore network architectures that induce loopy inference graphs, including loops that arise from skip connections. With UNet as the backbone, we find an architecture, MRF-UNet, that shows several interesting characteristics. Secondly, through the lens of these characteristics, we identify the sub-optimality of the original UNet architecture and further improve our results with MRF-UNetV2. Experiments show that our MRF-UNets significantly outperform several benchmarks on three aerial image datasets and two medical image datasets while maintaining low computational costs. The code is available at: https://github.com/zifuwanggg/MRF-UNets.