 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Graphs for Syntactic Simplification: A Revisit from the Age of LLM
Jul 04, 2024



Symbolic sentence meaning representations, such as AMR (Abstract Meaning Representation) provide expressive and structured semantic graphs that act as intermediates that simplify downstream NLP tasks. However, the instruction-following capability of large language models (LLMs) offers a shortcut to effectively solve NLP tasks, questioning the utility of semantic graphs. Meanwhile, recent work has also shown the difficulty of using meaning representations merely as a helpful auxiliary for LLMs. We revisit the position of semantic graphs in syntactic simplification, the task of simplifying sentence structures while preserving their meaning, which requires semantic understanding, and evaluate it on a new complex and natural dataset. The AMR-based method that we propose, AMRS$^3$, demonstrates that state-of-the-art meaning representations can lead to easy-to-implement simplification methods with competitive performance and unique advantages in cost, interpretability, and generalization. With AMRS$^3$ as an anchor, we discover that syntactic simplification is a task where semantic graphs are helpful in LLM prompting. We propose AMRCoC prompting that guides LLMs to emulate graph algorithms for explicit symbolic reasoning on AMR graphs, and show its potential for improving LLM on semantic-centered tasks like syntactic simplification.
Can LLMs Learn by Teaching? A Preliminary Study
Jun 20, 2024



Teaching to improve student models (e.g., knowledge distillation) is an extensively studied methodology in LLMs. However, for humans, teaching not only improves students but also improves teachers. We ask: Can LLMs also learn by teaching (LbT)? If yes, we can potentially unlock the possibility of continuously advancing the models without solely relying on human-produced data or stronger models. In this paper, we provide a preliminary exploration of this ambitious agenda. We show that LbT ideas can be incorporated into existing LLM training/prompting pipelines and provide noticeable improvements. Specifically, we design three methods, each mimicking one of the three levels of LbT in humans: observing students' feedback, learning from the feedback, and learning iteratively, with the goals of improving answer accuracy without training and improving models' inherent capability with fine-tuning. The findings are encouraging. For example, similar to LbT in human, we see that: (1) LbT can induce weak-to-strong generalization: strong models can improve themselves by teaching other weak models; (2) Diversity in students might help: teaching multiple students could be better than teaching one student or the teacher itself. We hope that this early promise can inspire future research on LbT and more broadly adopting the advanced techniques in education to improve LLMs. The code is available at https://github.com/imagination-research/lbt.
Accurate and Nuanced Open-QA Evaluation Through Textual Entailment
May 26, 2024Open-domain question answering (Open-QA) is a common task for evaluating large language models (LLMs). However, current Open-QA evaluations are criticized for the ambiguity in questions and the lack of semantic understanding in evaluators. Complex evaluators, powered by foundation models or LLMs and pertaining to semantic equivalence, still deviate from human judgments by a large margin. We propose to study the entailment relations of answers to identify more informative and more general system answers, offering a much closer evaluation to human judgment on both NaturalQuestions and TriviaQA while being learning-free. The entailment-based evaluation we propose allows the assignment of bonus or partial marks by quantifying the inference gap between answers, enabling a nuanced ranking of answer correctness that has higher AUC than current methods.
NLP Workbench: Efficient and Extensible Integration of State-of-the-art Text Mining Tools
Mar 02, 2023


NLP Workbench is a web-based platform for text mining that allows non-expert users to obtain semantic understanding of large-scale corpora using state-of-the-art text mining models. The platform is built upon latest pre-trained models and open source systems from academia that provide semantic analysis functionalities, including but not limited to entity linking, sentiment analysis, semantic parsing, and relation extraction. Its extensible design enables researchers and developers to smoothly replace an existing model or integrate a new one. To improve efficiency, we employ a microservice architecture that facilitates allocation of acceleration hardware and parallelization of computation. This paper presents the architecture of NLP Workbench and discusses the challenges we faced in designing it. We also discuss diverse use cases of NLP Workbench and the benefits of using it over other approaches. The platform is under active development, with its source code released under the MIT license. A website and a short video demonstrating our platform are also available.
Typing Errors in Factual Knowledge Graphs: Severity and Possible Ways Out
Feb 03, 2021

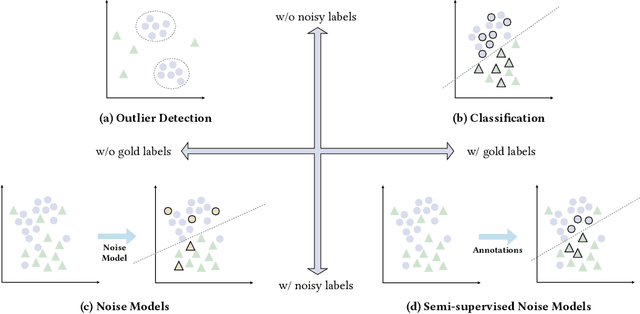

Factual knowledge graphs (KGs) such as DBpedia and Wikidata have served as part of various downstream tasks and are also widely adopted by artificial intelligence research communities as benchmark datasets. However, we found these KGs to be surprisingly noisy. In this study, we question the quality of these KGs, where the typing error rate is estimated to be 27% for coarse-grained types on average, and even 73% for certain fine-grained types. In pursuit of solutions, we propose an active typing error detection algorithm that maximizes the utilization of both gold and noisy labels. We also comprehensively discuss and compare unsupervised, semi-supervised, and supervised paradigms to deal with typing errors in factual KGs. The outcomes of this study provide guidelines for researchers to use noisy factual KGs. To help practitioners deploy the techniques and conduct further research, we published our code and data.