 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNI Sampling: Accelerating Discrete Diffusion Sampling by Token Order Optimization
Apr 20, 2026Discrete diffusion language models (dLLMs) have recently emerged as a promising alternative to traditional autoregressive approaches, offering the flexibility to generate tokens in arbitrary orders and the potential of parallel decoding. However, existing heuristic sampling strategies remain inefficient: they choose only a small part of tokens to sample at each step, leaving substantial room for improvement. In this work, we study the problem of token sampling order optimization and demonstrate its significant potential for acceleration. Specifically, we find that fully leveraging correct predictions at each step can reduce the number of sampling iterations by an order of magnitude without compromising accuracy. Based on this, we propose Neural Indicator Sampling (NI Sampling), a general sampling order optimization framework that utilize a neural indicator to decide which tokens should be sampled at each step. We further propose a novel trajectory-preserving objective to train the indicator. Experiments on LLaDA and Dream models across multiple benchmarks show that our method achieves up to 14.3$\times$ acceleration over full-step sampling with negligible performance drop, and consistently outperforms confidence threshold sampling in the accuracy-step trade-off. Code is available at https://github.com/imagination-research/NI-Sampling.
CineScene: Implicit 3D as Effective Scene Representation for Cinematic Video Generation
Feb 06, 2026Cinematic video production requires control over scene-subject composition and camera movement, but live-action shooting remains costly due to the need for constructing physical sets. To address this, we introduce the task of cinematic video generation with decoupled scene context: given multiple images of a static environment, the goal is to synthesize high-quality videos featuring dynamic subject while preserving the underlying scene consistency and following a user-specified camera trajectory. We present CineScene, a framework that leverages implicit 3D-aware scene representation for cinematic video generation. Our key innovation is a novel context conditioning mechanism that injects 3D-aware features in an implicit way: By encoding scene images into visual representations through VGGT, CineScene injects spatial priors into a pretrained text-to-video generation model by additional context concatenation, enabling camera-controlled video synthesis with consistent scenes and dynamic subjects. To further enhance the model's robustness, we introduce a simple yet effective random-shuffling strategy for the input scene images during training. To address the lack of training data, we construct a scene-decoupled dataset with Unreal Engine 5, containing paired videos of scenes with and without dynamic subjects, panoramic images representing the underlying static scene, along with their camera trajectories. Experiments show that CineScene achieves state-of-the-art performance in scene-consistent cinematic video generation, handling large camera movements and demonstrating generalization across diverse environments.
SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer
Jan 23, 2026Diffusion Transformers have recently demonstrated remarkable performance in video generation. However, the long input sequences result in high computational latency due to the quadratic complexity of full attention. Various sparse attention mechanisms have been proposed. Training-free sparse attention is constrained by limited sparsity and thus offers modest acceleration, whereas training-based methods can reach much higher sparsity but demand substantial data and computation for training. In this work, we propose SALAD, introducing a lightweight linear attention branch in parallel with the sparse attention. By incorporating an input-dependent gating mechanism to finely balance the two branches, our method attains 90% sparsity and 1.72x inference speedup, while maintaining generation quality comparable to the full attention baseline. Moreover, our finetuning process is highly efficient, requiring only 2,000 video samples and 1,600 training steps with a batch size of 8.
SJD++: Improved Speculative Jacobi Decoding for Training-free Acceleration of Discrete Auto-regressive Text-to-Image Generation
Dec 08, 2025Large autoregressive models can generate high-quality, high-resolution images but suffer from slow generation speed, because these models require hundreds to thousands of sequential forward passes for next-token prediction during inference. To accelerate autoregressive text-to-image generation, we propose Speculative Jacobi Decoding++ (SJD++), a training-free probabilistic parallel decoding algorithm. Unlike traditional next-token prediction, SJD++ performs multi-token prediction in each forward pass, drastically reducing generation steps. Specifically, it integrates the iterative multi-token prediction mechanism from Jacobi decoding, with the probabilistic drafting-and-verification mechanism from speculative sampling. More importantly, for further acceleration, SJD++ reuses high-confidence draft tokens after each verification phase instead of resampling them all. We conduct extensive experiments on several representative autoregressive text-to-image generation models and demonstrate that SJD++ achieves $2\times$ to $3\times$ inference latency reduction and $2\times$ to $7\times$ step compression, while preserving visual quality with no observable degradation.
On the Ability of LLMs to Handle Character-Level Perturbations: How Well and How?
Oct 16, 2025This work investigates the resilience of contemporary LLMs against frequent and structured character-level perturbations, specifically through the insertion of noisy characters after each input character. We introduce \nameshort{}, a practical method that inserts invisible Unicode control characters into text to discourage LLM misuse in scenarios such as online exam systems. Surprisingly, despite strong obfuscation that fragments tokenization and reduces the signal-to-noise ratio significantly, many LLMs still maintain notable performance. Through comprehensive evaluation across model-, problem-, and noise-related configurations, we examine the extent and mechanisms of this robustness, exploring both the handling of character-level tokenization and \textit{implicit} versus \textit{explicit} denoising mechanism hypotheses of character-level noises. We hope our findings on the low-level robustness of LLMs will shed light on the risks of their misuse and on the reliability of deploying LLMs across diverse applications.
Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification
Sep 19, 2025Generative modeling, representation learning, and classification are three core problems in machine learning (ML), yet their state-of-the-art (SoTA) solutions remain largely disjoint. In this paper, we ask: Can a unified principle address all three? Such unification could simplify ML pipelines and foster greater synergy across tasks. We introduce Latent Zoning Network (LZN) as a step toward this goal. At its core, LZN creates a shared Gaussian latent space that encodes information across all tasks. Each data type (e.g., images, text, labels) is equipped with an encoder that maps samples to disjoint latent zones, and a decoder that maps latents back to data. ML tasks are expressed as compositions of these encoders and decoders: for example, label-conditional image generation uses a label encoder and image decoder; image embedding uses an image encoder; classification uses an image encoder and label decoder. We demonstrate the promise of LZN in three increasingly complex scenarios: (1) LZN can enhance existing models (image generation): When combined with the SoTA Rectified Flow model, LZN improves FID on CIFAR10 from 2.76 to 2.59-without modifying the training objective. (2) LZN can solve tasks independently (representation learning): LZN can implement unsupervised representation learning without auxiliary loss functions, outperforming the seminal MoCo and SimCLR methods by 9.3% and 0.2%, respectively, on downstream linear classification on ImageNet. (3) LZN can solve multiple tasks simultaneously (joint generation and classification): With image and label encoders/decoders, LZN performs both tasks jointly by design, improving FID and achieving SoTA classification accuracy on CIFAR10. The code and trained models are available at https://github.com/microsoft/latent-zoning-networks. The project website is at https://zinanlin.me/blogs/latent_zoning_networks.html.
How Quantization Shapes Bias in Large Language Models
Aug 25, 2025
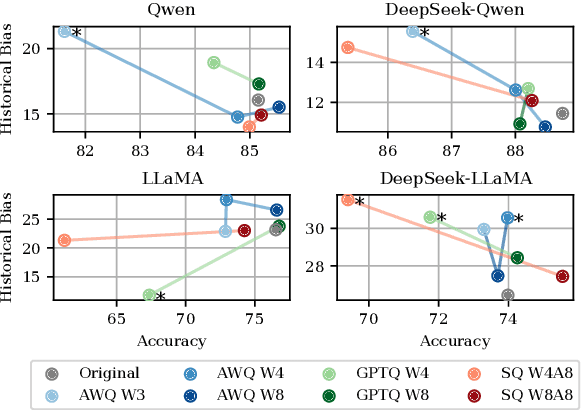
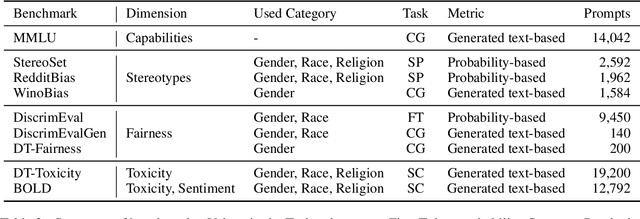
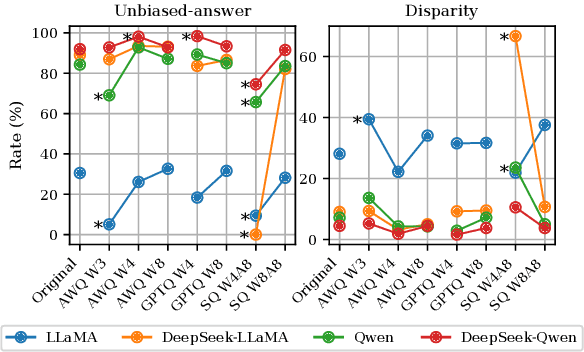
This work presents a comprehensive evaluation of how quantization affects model bias, with particular attention to its impact on individual demographic subgroups. We focus on weight and activation quantization strategies and examine their effects across a broad range of bias types, including stereotypes, toxicity, sentiment, and fairness. We employ both probabilistic and generated text-based metrics across nine benchmarks and evaluate models varying in architecture family and reasoning ability. Our findings show that quantization has a nuanced impact on bias: while it can reduce model toxicity and does not significantly impact sentiment, it tends to slightly increase stereotypes and unfairness in generative tasks, especially under aggressive compression. These trends are generally consistent across demographic categories and model types, although their magnitude depends on the specific setting. Overall, our results highlight the importance of carefully balancing efficiency and ethical considerations when applying quantization in practice.
FilMaster: Bridging Cinematic Principles and Generative AI for Automated Film Generation
Jun 23, 2025AI-driven content creation has shown potential in film production. However, existing film generation systems struggle to implement cinematic principles and thus fail to generate professional-quality films, particularly lacking diverse camera language and cinematic rhythm. This results in templated visuals and unengaging narratives. To address this, we introduce FilMaster, an end-to-end AI system that integrates real-world cinematic principles for professional-grade film generation, yielding editable, industry-standard outputs. FilMaster is built on two key principles: (1) learning cinematography from extensive real-world film data and (2) emulating professional, audience-centric post-production workflows. Inspired by these principles, FilMaster incorporates two stages: a Reference-Guided Generation Stage which transforms user input to video clips, and a Generative Post-Production Stage which transforms raw footage into audiovisual outputs by orchestrating visual and auditory elements for cinematic rhythm. Our generation stage highlights a Multi-shot Synergized RAG Camera Language Design module to guide the AI in generating professional camera language by retrieving reference clips from a vast corpus of 440,000 film clips. Our post-production stage emulates professional workflows by designing an Audience-Centric Cinematic Rhythm Control module, including Rough Cut and Fine Cut processes informed by simulated audience feedback, for effective integration of audiovisual elements to achieve engaging content. The system is empowered by generative AI models like (M)LLMs and video generation models. Furthermore, we introduce FilmEval, a comprehensive benchmark for evaluating AI-generated films. Extensive experiments show FilMaster's superior performance in camera language design and cinematic rhythm control, advancing generative AI in professional filmmaking.
AgentSociety Challenge: Designing LLM Agents for User Modeling and Recommendation on Web Platforms
Feb 26, 2025The AgentSociety Challenge is the first competition in the Web Conference that aims to explore the potential of Large Language Model (LLM) agents in modeling user behavior and enhancing recommender systems on web platforms. The Challenge consists of two tracks: the User Modeling Track and the Recommendation Track. Participants are tasked to utilize a combined dataset from Yelp, Amazon, and Goodreads, along with an interactive environment simulator, to develop innovative LLM agents. The Challenge has attracted 295 teams across the globe and received over 1,400 submissions in total over the course of 37 official competition days. The participants have achieved 21.9% and 20.3% performance improvement for Track 1 and Track 2 in the Development Phase, and 9.1% and 15.9% in the Final Phase, representing a significant accomplishment. This paper discusses the detailed designs of the Challenge, analyzes the outcomes, and highlights the most successful LLM agent designs. To support further research and development, we have open-sourced the benchmark environment at https://tsinghua-fib-lab.github.io/AgentSocietyChallenge.
Token Pruning for Caching Better: 9 Times Acceleration on Stable Diffusion for Free
Dec 31, 2024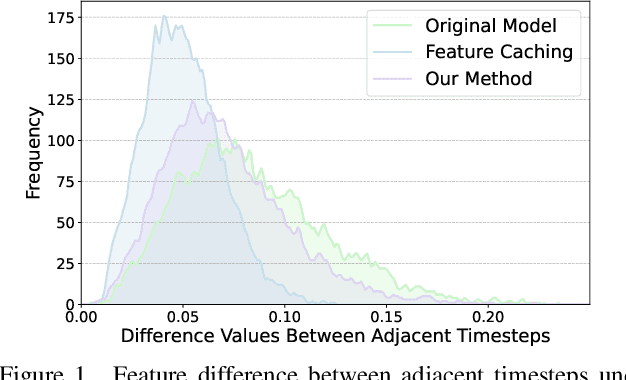
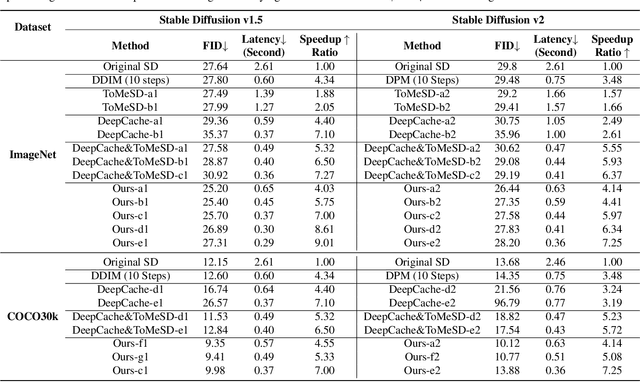

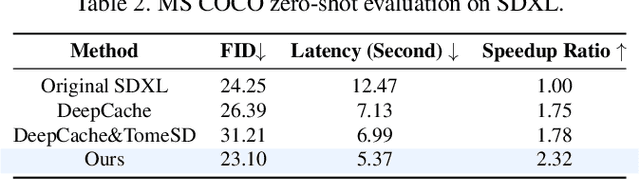
Stable Diffusion has achieved remarkable success in the field of text-to-image generation, with its powerful generative capabilities and diverse generation results making a lasting impact. However, its iterative denoising introduces high computational costs and slows generation speed, limiting broader adoption. The community has made numerous efforts to reduce this computational burden, with methods like feature caching attracting attention due to their effectiveness and simplicity. Nonetheless, simply reusing features computed at previous timesteps causes the features across adjacent timesteps to become similar, reducing the dynamics of features over time and ultimately compromising the quality of generated images. In this paper, we introduce a dynamics-aware token pruning (DaTo) approach that addresses the limitations of feature caching. DaTo selectively prunes tokens with lower dynamics, allowing only high-dynamic tokens to participate in self-attention layers, thereby extending feature dynamics across timesteps. DaTo combines feature caching with token pruning in a training-free manner, achieving both temporal and token-wise information reuse. Applied to Stable Diffusion on the ImageNet, our approach delivered a 9$\times$ speedup while reducing FID by 0.33, indicating enhanced image quality. On the COCO-30k, we observed a 7$\times$ acceleration coupled with a notable FID reduction of 2.17.