 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASP: Topology-aware Sequence Parallelism
Sep 30, 2025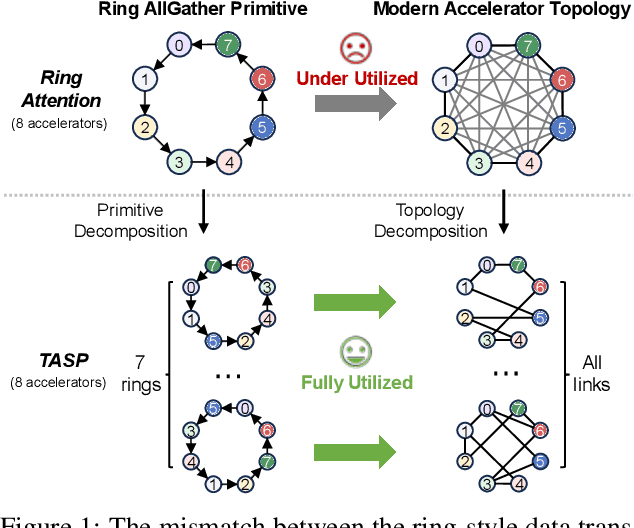


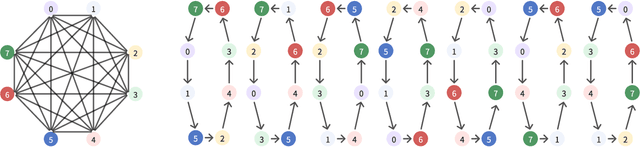
Long-context large language models (LLMs) face constraints due to the quadratic complexity of the self-attention mechanism. The mainstream sequence parallelism (SP) method, Ring Attention, attempts to solve this by distributing the query into multiple query chunks across accelerators and enable each Q tensor to access all KV tensors from other accelerators via the Ring AllGather communication primitive. However, it exhibits low communication efficiency, restricting its practical applicability. This inefficiency stems from the mismatch between the Ring AllGather communication primitive it adopts and the AlltoAll topology of modern accelerators. A Ring AllGather primitive is composed of iterations of ring-styled data transfer, which can only utilize a very limited fraction of an AlltoAll topology. Inspired by the Hamiltonian decomposition of complete directed graphs, we identify that modern accelerator topology can be decomposed into multiple orthogonal ring datapaths which can concurrently transfer data without interference. Based on this, we further observe that the Ring AllGather primitive can also be decomposed into the same number of concurrent ring-styled data transfer at every iteration. Based on these insights, we propose TASP, a topology-aware SP method for long-context LLMs that fully utilizes the communication capacity of modern accelerators via topology decomposition and primitive decomposition. Experimental results on both single-node and multi-node NVIDIA H100 systems and a single-node AMD MI300X system demonstrate that TASP achieves higher communication efficiency than Ring Attention on these modern accelerator topologies and achieves up to 3.58 speedup than Ring Attention and its variant Zigzag-Ring Attention. The code is available at https://github.com/infinigence/HamiltonAttention.
FlashOverlap: A Lightweight Design for Efficiently Overlapping Communication and Computation
Apr 28, 2025Generative models have achieved remarkable success across various applications, driving the demand for multi-GPU computing. Inter-GPU communication becomes a bottleneck in multi-GPU computing systems, particularly on consumer-grade GPUs. By exploiting concurrent hardware execution, overlapping computation and communication latency is an effective technique for mitigating the communication overhead. We identify that an efficient and adaptable overlapping design should satisfy (1) tile-wise overlapping to maximize the overlapping opportunity, (2) interference-free computation to maintain the original computational performance, and (3) communication agnosticism to reduce the development burden against varying communication primitives. Nevertheless, current designs fail to simultaneously optimize for all of those features. To address the issue, we propose FlashOverlap, a lightweight design characterized by tile-wise overlapping, interference-free computation, and communication agnosticism. FlashOverlap utilizes a novel signaling mechanism to identify tile-wise data dependency without interrupting the computation process, and reorders data to contiguous addresses, enabling communication by simply calling NCCL APIs. Experiments show that such a lightweight design achieves up to 1.65x speedup, outperforming existing works in most cases.
semi-PD: Towards Efficient LLM Serving via Phase-Wise Disaggregated Computation and Unified Storage
Apr 28, 2025Existing large language model (LLM) serving systems fall into two categories: 1) a unified system where prefill phase and decode phase are co-located on the same GPU, sharing the unified computational resource and storage, and 2) a disaggregated system where the two phases are disaggregated to different GPUs. The design of the disaggregated system addresses the latency interference and sophisticated scheduling issues in the unified system but leads to storage challenges including 1) replicated weights for both phases that prevent flexible deployment, 2) KV cache transfer overhead between the two phases, 3) storage imbalance that causes substantial wasted space of the GPU capacity, and 4) suboptimal resource adjustment arising from the difficulties in migrating KV cache. Such storage inefficiency delivers poor serving performance under high request rates. In this paper, we identify that the advantage of the disaggregated system lies in the disaggregated computation, i.e., partitioning the computational resource to enable the asynchronous computation of two phases. Thus, we propose a novel LLM serving system, semi-PD, characterized by disaggregated computation and unified storage. In semi-PD, we introduce a computation resource controller to achieve disaggregated computation at the streaming multi-processor (SM) level, and a unified memory manager to manage the asynchronous memory access from both phases. semi-PD has a low-overhead resource adjustment mechanism between the two phases, and a service-level objective (SLO) aware dynamic partitioning algorithm to optimize the SLO attainment. Compared to state-of-the-art systems, semi-PD maintains lower latency at higher request rates, reducing the average end-to-end latency per request by 1.27-2.58x on DeepSeek series models, and serves 1.55-1.72x more requests adhering to latency constraints on Llama series models.
MBQ: Modality-Balanced Quantization for Large Vision-Language Models
Dec 27, 2024



Vision-Language Models (VLMs) have enabled a variety of real-world applications. The large parameter size of VLMs brings large memory and computation overhead which poses significant challenges for deployment. Post-Training Quantization (PTQ) is an effective technique to reduce the memory and computation overhead. Existing PTQ methods mainly focus on large language models (LLMs), without considering the differences across other modalities. In this paper, we discover that there is a significant difference in sensitivity between language and vision tokens in large VLMs. Therefore, treating tokens from different modalities equally, as in existing PTQ methods, may over-emphasize the insensitive modalities, leading to significant accuracy loss. To deal with the above issue, we propose a simple yet effective method, Modality-Balanced Quantization (MBQ), for large VLMs. Specifically, MBQ incorporates the different sensitivities across modalities during the calibration process to minimize the reconstruction loss for better quantization parameters. Extensive experiments show that MBQ can significantly improve task accuracy by up to 4.4% and 11.6% under W3 and W4A8 quantization for 7B to 70B VLMs, compared to SOTA baselines. Additionally, we implement a W3 GPU kernel that fuses the dequantization and GEMV operators, achieving a 1.4x speedup on LLaVA-onevision-7B on the RTX 4090. The code is available at https://github.com/thu-nics/MBQ.
A Survey on Efficient Inference for Large Language Models
Apr 22, 2024Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
FlashDecoding++: Faster Large Language Model Inference on GPUs
Nov 10, 2023



As the Large Language Model (LLM) becomes increasingly important in various domains. However, the following challenges still remain unsolved in accelerating LLM inference: (1) Synchronized partial softmax update. The softmax operation requires a synchronized update operation among each partial softmax result, leading to ~20% overheads for the attention computation in LLMs. (2) Under-utilized computation of flat GEMM. The shape of matrices performing GEMM in LLM inference is flat, leading to under-utilized computation and >50% performance loss after padding zeros in previous designs. (3) Performance loss due to static dataflow. Kernel performance in LLM depends on varied input data features, hardware configurations, etc. A single and static dataflow may lead to a 50.25% performance loss for GEMMs of different shapes in LLM inference. We present FlashDecoding++, a fast LLM inference engine supporting mainstream LLMs and hardware back-ends. To tackle the above challenges, FlashDecoding++ creatively proposes: (1) Asynchronized softmax with unified max value. FlashDecoding++ introduces a unified max value technique for different partial softmax computations to avoid synchronization. (2) Flat GEMM optimization with double buffering. FlashDecoding++ points out that flat GEMMs with different shapes face varied bottlenecks. Then, techniques like double buffering are introduced. (3) Heuristic dataflow with hardware resource adaptation. FlashDecoding++ heuristically optimizes dataflow using different hardware resource considering input dynamics. Due to the versatility of optimizations in FlashDecoding++, FlashDecoding++ can achieve up to 4.86x and 2.18x speedup on both NVIDIA and AMD GPUs compared to Hugging Face implementations. FlashDecoding++ also achieves an average speedup of 1.37x compared to state-of-the-art LLM inference engines on mainstream LLMs.
Ada3D : Exploiting the Spatial Redundancy with Adaptive Inference for Efficient 3D Object Detection
Jul 17, 2023



Voxel-based methods have achieved state-of-the-art performance for 3D object detection in autonomous driving. However, their significant computational and memory costs pose a challenge for their application to resource-constrained vehicles. One reason for this high resource consumption is the presence of a large number of redundant background points in Lidar point clouds, resulting in spatial redundancy in both 3D voxel and dense BEV map representations. To address this issue, we propose an adaptive inference framework called Ada3D, which focuses on exploiting the input-level spatial redundancy. Ada3D adaptively filters the redundant input, guided by a lightweight importance predictor and the unique properties of the Lidar point cloud. Additionally, we utilize the BEV features' intrinsic sparsity by introducing the Sparsity Preserving Batch Normalization. With Ada3D, we achieve 40% reduction for 3D voxels and decrease the density of 2D BEV feature maps from 100% to 20% without sacrificing accuracy. Ada3D reduces the model computational and memory cost by 5x, and achieves 1.52x/1.45x end-to-end GPU latency and 1.5x/4.5x GPU peak memory optimization for the 3D and 2D backbone respectively.