 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models
Mar 19, 2026Diffusion transformers have demonstrated remarkable capabilities in generating videos. However, their practical deployment is severely constrained by high memory usage and computational cost. Post-Training Quantization provides a practical way to reduce memory usage and boost computation speed. Existing quantization methods typically apply a static bit-width allocation, overlooking the quantization difficulty of activations across diffusion timesteps, leading to a suboptimal trade-off between efficiency and quality. In this paper, we propose a inference time NVFP4/INT8 Mixed-Precision Quantization framework. We find a strong linear correlation between a block's input-output difference and the quantization sensitivity of its internal linear layers. Based on this insight, we design a lightweight predictor that dynamically allocates NVFP4 to temporally stable layers to maximize memory compression, while selectively preserving INT8 for volatile layers to ensure robustness. This adaptive precision strategy enables aggressive quantization without compromising generation quality. Beside this, we observe that the residual between the input and output of a Transformer block exhibits high temporal consistency across timesteps. Leveraging this temporal redundancy, we introduce Temporal Delta Cache (TDC) to skip computations for these invariant blocks, further reducing the computational cost. Extensive experiments demonstrate that our method achieves 1.92$\times$ end-to-end acceleration and 3.32$\times$ memory reduction, setting a new baseline for efficient inference in Video DiTs.
AltTS: A Dual-Path Framework with Alternating Optimization for Multivariate Time Series Forecasting
Feb 12, 2026Multivariate time series forecasting involves two qualitatively distinct factors: (i) stable within-series autoregressive (AR) dynamics, and (ii) intermittent cross-dimension interactions that can become spurious over long horizons. We argue that fitting a single model to capture both effects creates an optimization conflict: the high-variance updates needed for cross-dimension modeling can corrupt the gradients that support autoregression, resulting in brittle training and degraded long-horizon accuracy. To address this, we propose ALTTS, a dual-path framework that explicitly decouples autoregression and cross-relation (CR) modeling. In ALTTS, the AR path is instantiated with a linear predictor, while the CR path uses a Transformer equipped with Cross-Relation Self-Attention (CRSA); the two branches are coordinated via alternating optimization to isolate gradient noise and reduce cross-block interference. Extensive experiments on multiple benchmarks show that ALTTS consistently outperforms prior methods, with the most pronounced improvements on long-horizon forecasting. Overall, our results suggest that carefully designed optimization strategies, rather than ever more complex architectures, can be a key driver of progress in multivariate time series forecasting.
TUBO: A Tailored ML Framework for Reliable Network Traffic Forecasting
Feb 12, 2026Traffic forecasting based network operation optimization and management offers enormous promise but also presents significant challenges from traffic forecasting perspective. While deep learning models have proven to be relatively more effective than traditional statistical methods for time series forecasting, their reliability is not satisfactory due to their inability to effectively handle unique characteristics of network traffic. In particular, the burst and complex traffic patterns makes the existing models less reliable, as each type of deep learning model has limited capability in capturing traffic patterns. To address this issue, we introduce TUBO, a novel machine learning framework custom designed for reliable network traffic forecasting. TUBO features two key components: burst processing for handling significant traffic fluctuations and model selection for adapting to varying traffic patterns using a pool of models. A standout feature of TUBO is its ability to provide deterministic predictions along with quantified uncertainty, which serves as a cue for identifying the most reliable forecasts. Evaluations on three real-world network demand matrix (DM) datasets (Abilene, GEANT, and CERNET) show that TUBO significantly outperforms existing methods on forecasting accuracy (by 4 times), and also achieves up to 94% accuracy in burst occurrence forecasting. Furthermore, we also consider traffic demand forecasting based proactive traffic engineering (TE) as a downstream use case. Our results show that compared to reactive approaches and proactive TE using the best existing DM forecasting methods, proactive TE powered by TUBO improves aggregated throughput by 9 times and 3 times, respectively.
Uncertainty-Aware Gradient Signal-to-Noise Data Selection for Instruction Tuning
Jan 20, 2026Instruction tuning is a standard paradigm for adapting large language models (LLMs), but modern instruction datasets are large, noisy, and redundant, making full-data fine-tuning costly and often unnecessary. Existing data selection methods either build expensive gradient datastores or assign static scores from a weak proxy, largely ignoring evolving uncertainty, and thus missing a key source of LLM interpretability. We propose GRADFILTERING, an objective-agnostic, uncertainty-aware data selection framework that utilizes a small GPT-2 proxy with a LoRA ensemble and aggregates per-example gradients into a Gradient Signal-to-Noise Ratio (G-SNR) utility. Our method matches or surpasses random subsets and strong baselines in most LLM-as-a-judge evaluations as well as in human assessment. Moreover, GRADFILTERING-selected subsets converge faster than competitive filters under the same compute budget, reflecting the benefit of uncertainty-aware scoring.
MoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
Nov 19, 2025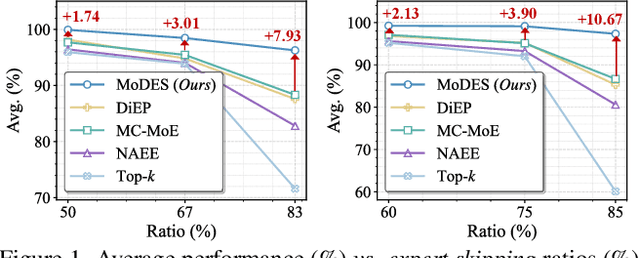

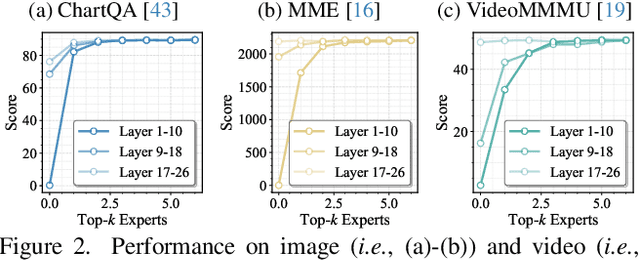
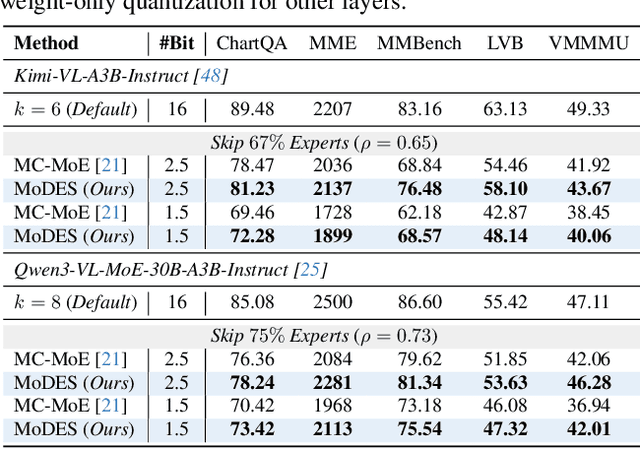
Mixture-of-Experts (MoE) Multimodal large language models (MLLMs) excel at vision-language tasks, but they suffer from high computational inefficiency. To reduce inference overhead, expert skipping methods have been proposed to deactivate redundant experts based on the current input tokens. However, we find that applying these methods-originally designed for unimodal large language models (LLMs)-to MLLMs results in considerable performance degradation. This is primarily because such methods fail to account for the heterogeneous contributions of experts across MoE layers and modality-specific behaviors of tokens within these layers. Motivated by these findings, we propose MoDES, the first training-free framework that adaptively skips experts to enable efficient and accurate MoE MLLM inference. It incorporates a globally-modulated local gating (GMLG) mechanism that integrates global layer-wise importance into local routing probabilities to accurately estimate per-token expert importance. A dual-modality thresholding (DMT) method is then applied, which processes tokens from each modality separately, to derive the skipping schedule. To set the optimal thresholds, we introduce a frontier search algorithm that exploits monotonicity properties, cutting convergence time from several days to a few hours. Extensive experiments for 3 model series across 13 benchmarks demonstrate that MoDES far outperforms previous approaches. For instance, when skipping 88% experts for Qwen3-VL-MoE-30B-A3B-Instruct, the performance boost is up to 10.67% (97.33% vs. 86.66%). Furthermore, MoDES significantly enhances inference speed, improving the prefilling time by 2.16$\times$ and the decoding time by 1.26$\times$.
OTARo: Once Tuning for All Precisions toward Robust On-Device LLMs
Nov 17, 2025Large Language Models (LLMs) fine-tuning techniques not only improve the adaptability to diverse downstream tasks, but also mitigate adverse effects of model quantization. Despite this, conventional quantization suffers from its structural limitation that hinders flexibility during the fine-tuning and deployment stages. Practical on-device tasks demand different quantization precisions (i.e. different bit-widths), e.g., understanding tasks tend to exhibit higher tolerance to reduced precision compared to generation tasks. Conventional quantization, typically relying on scaling factors that are incompatible across bit-widths, fails to support the on-device switching of precisions when confronted with complex real-world scenarios. To overcome the dilemma, we propose OTARo, a novel method that enables on-device LLMs to flexibly switch quantization precisions while maintaining performance robustness through once fine-tuning. OTARo introduces Shared Exponent Floating Point (SEFP), a distinct quantization mechanism, to produce different bit-widths through simple mantissa truncations of a single model. Moreover, to achieve bit-width robustness in downstream applications, OTARo performs a learning process toward losses induced by different bit-widths. The method involves two critical strategies: (1) Exploitation-Exploration Bit-Width Path Search (BPS), which iteratively updates the search path via a designed scoring mechanism; (2) Low-Precision Asynchronous Accumulation (LAA), which performs asynchronous gradient accumulations and delayed updates under low bit-widths. Experiments on popular LLMs, e.g., LLaMA3.2-1B, LLaMA3-8B, demonstrate that OTARo achieves consistently strong and robust performance for all precisions.
AIM: Software and Hardware Co-design for Architecture-level IR-drop Mitigation in High-performance PIM
Nov 06, 2025



SRAM Processing-in-Memory (PIM) has emerged as the most promising implementation for high-performance PIM, delivering superior computing density, energy efficiency, and computational precision. However, the pursuit of higher performance necessitates more complex circuit designs and increased operating frequencies, which exacerbate IR-drop issues. Severe IR-drop can significantly degrade chip performance and even threaten reliability. Conventional circuit-level IR-drop mitigation methods, such as back-end optimizations, are resource-intensive and often compromise power, performance, and area (PPA). To address these challenges, we propose AIM, comprehensive software and hardware co-design for architecture-level IR-drop mitigation in high-performance PIM. Initially, leveraging the bit-serial and in-situ dataflow processing properties of PIM, we introduce Rtog and HR, which establish a direct correlation between PIM workloads and IR-drop. Building on this foundation, we propose LHR and WDS, enabling extensive exploration of architecture-level IR-drop mitigation while maintaining computational accuracy through software optimization. Subsequently, we develop IR-Booster, a dynamic adjustment mechanism that integrates software-level HR information with hardware-based IR-drop monitoring to adapt the V-f pairs of the PIM macro, achieving enhanced energy efficiency and performance. Finally, we propose the HR-aware task mapping method, bridging software and hardware designs to achieve optimal improvement. Post-layout simulation results on a 7nm 256-TOPS PIM chip demonstrate that AIM achieves up to 69.2% IR-drop mitigation, resulting in 2.29x energy efficiency improvement and 1.152x speedup.
VocabTailor: Dynamic Vocabulary Selection for Downstream Tasks in Small Language Models
Aug 21, 2025Small Language Models (SLMs) provide computational advantages in resource-constrained environments, yet memory limitations remain a critical bottleneck for edge device deployment. A substantial portion of SLMs' memory footprint stems from vocabulary-related components, particularly embeddings and language modeling (LM) heads, due to large vocabulary sizes. Existing static vocabulary pruning, while reducing memory usage, suffers from rigid, one-size-fits-all designs that cause information loss from the prefill stage and a lack of flexibility. In this work, we identify two key principles underlying the vocabulary reduction challenge: the lexical locality principle, the observation that only a small subset of tokens is required during any single inference, and the asymmetry in computational characteristics between vocabulary-related components of SLM. Based on these insights, we introduce VocabTailor, a novel decoupled dynamic vocabulary selection framework that addresses memory constraints through offloading embedding and implements a hybrid static-dynamic vocabulary selection strategy for LM Head, enabling on-demand loading of vocabulary components. Comprehensive experiments across diverse downstream tasks demonstrate that VocabTailor achieves a reduction of up to 99% in the memory usage of vocabulary-related components with minimal or no degradation in task performance, substantially outperforming existing static vocabulary pruning.
Spec-VLA: Speculative Decoding for Vision-Language-Action Models with Relaxed Acceptance
Jul 30, 2025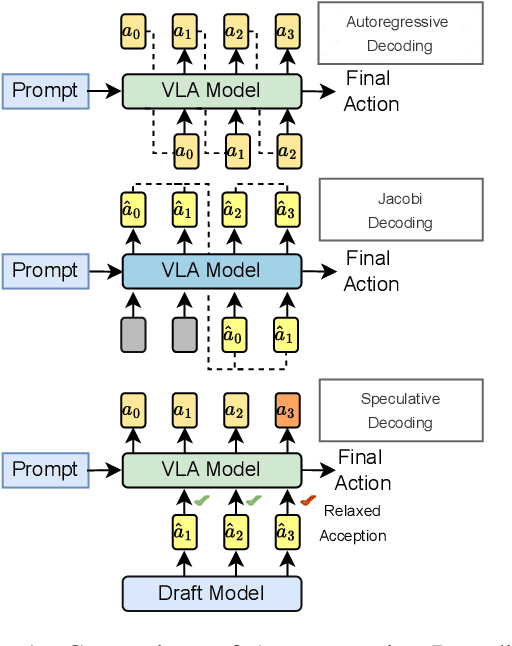
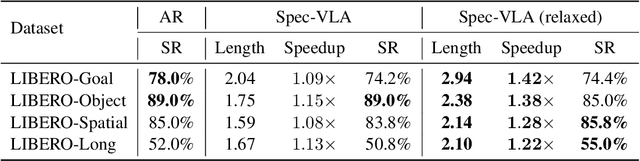
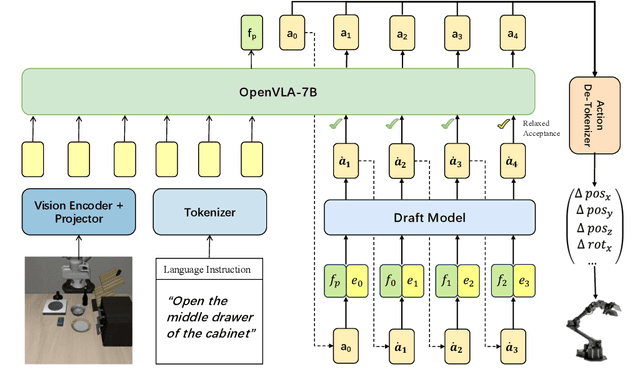
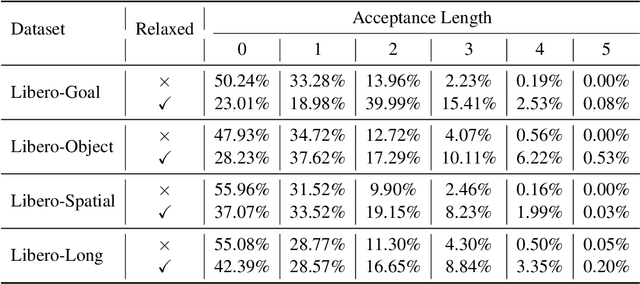
Vision-Language-Action (VLA) models have made substantial progress by leveraging the robust capabilities of Visual Language Models (VLMs). However, VLMs' significant parameter size and autoregressive (AR) decoding nature impose considerable computational demands on VLA models. While Speculative Decoding (SD) has shown efficacy in accelerating Large Language Models (LLMs) by incorporating efficient drafting and parallel verification, allowing multiple tokens to be generated in one forward pass, its application to VLA models remains unexplored. This work introduces Spec-VLA, an SD framework designed to accelerate VLA models. Due to the difficulty of the action prediction task and the greedy decoding mechanism of the VLA models, the direct application of the advanced SD framework to the VLA prediction task yields a minor speed improvement. To boost the generation speed, we propose an effective mechanism to relax acceptance utilizing the relative distances represented by the action tokens of the VLA model. Empirical results across diverse test scenarios affirm the effectiveness of the Spec-VLA framework, and further analysis substantiates the impact of our proposed strategies, which enhance the acceptance length by 44%, achieving 1.42 times speedup compared with the OpenVLA baseline, without compromising the success rate. The success of the Spec-VLA framework highlights the potential for broader application of speculative execution in VLA prediction scenarios.
SplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Jul 22, 2025


Generative models like Flow Matching have achieved state-of-the-art performance but are often hindered by a computationally expensive iterative sampling process. To address this, recent work has focused on few-step or one-step generation by learning the average velocity field, which directly maps noise to data. MeanFlow, a leading method in this area, learns this field by enforcing a differential identity that connects the average and instantaneous velocities. In this work, we argue that this differential formulation is a limiting special case of a more fundamental principle. We return to the first principles of average velocity and leverage the additivity property of definite integrals. This leads us to derive a novel, purely algebraic identity we term Interval Splitting Consistency. This identity establishes a self-referential relationship for the average velocity field across different time intervals without resorting to any differential operators. Based on this principle, we introduce SplitMeanFlow, a new training framework that enforces this algebraic consistency directly as a learning objective. We formally prove that the differential identity at the core of MeanFlow is recovered by taking the limit of our algebraic consistency as the interval split becomes infinitesimal. This establishes SplitMeanFlow as a direct and more general foundation for learning average velocity fields. From a practical standpoint, our algebraic approach is significantly more efficient, as it eliminates the need for JVP computations, resulting in simpler implementation, more stable training, and broader hardware compatibility. One-step and two-step SplitMeanFlow models have been successfully deployed in large-scale speech synthesis products (such as Doubao), achieving speedups of 20x.